Outils pour copier de façon sélective HTML+CSS+JS à partir de sites existants [fermé]
comme la plupart des développeurs web, j'aime à l'occasion regarder la source des sites Web pour voir comment leur balisage est construit. Des outils tels que Firebug et Chrome Developer Tools facilitent l'inspection du code, mais si je veux copier une section isolée et jouer avec elle localement, il serait difficile de copier tous les éléments individuels et leurs css associés. Et probablement autant de travail pour sauver la source entière et couper le code sans rapport.
ce serait génial si je pouvais faire un clic droit sur un noeud dans Firebug et avoir une option "Enregistrer HTML+CSS pour ce noeud". Un tel outil existe pas? Est-il possible d'étendre les outils de développement Firebug ou Chrome pour ajouter cette fonctionnalité?
16 réponses
SnappySnippet
j'ai finalement trouvé un peu de temps pour créer cet outil. Vous pouvez installer SnappySnippet à partir de Chrome Web Store. Il permet une extraction HTML+CSS facile à partir du noeud DOM spécifié (dernier inspecté). En outre, vous pouvez envoyer votre code directement à CodePen ou JSFiddle. Profitez-en!
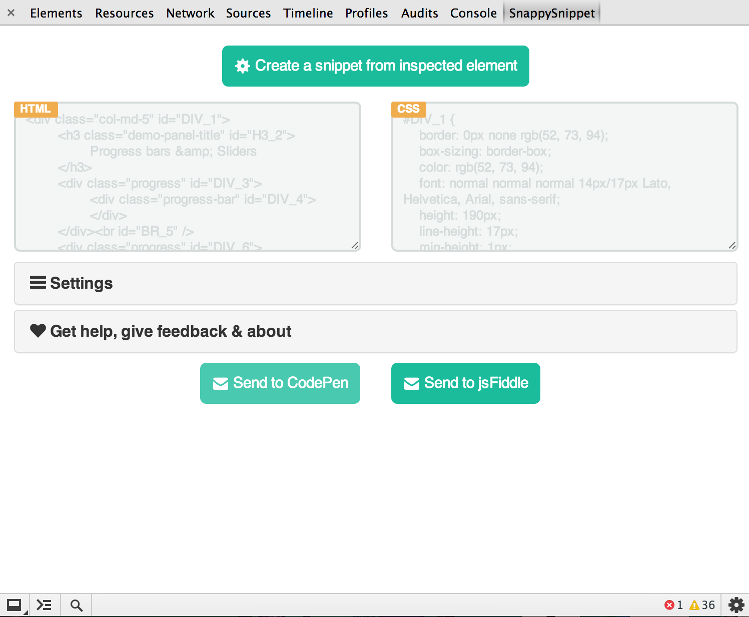
autres caractéristiques
- nettoie HTML (suppression d'attributs inutiles, correction d'indentation)
- optimise CSS pour le rendre lisible
- entièrement configurable (tous les filtres peuvent être désactivés)
- fonctionne avec
::beforeet::afterpseudo-éléments - belle INTERFACE utilisateur grâce à Bootstrap & Plate-UI projets
Code
SnappySnippet est open source, et vous pouvez trouver le code sur GitHub .
mise en œuvre
depuis que j'ai appris beaucoup en faisant cela, j'ai décidé de partager certains des problèmes que j'ai vécu et mes solutions à eux, peut-être que quelqu'un va trouver intéressant.
première tentative-getMatchedCSSRules()
au début j'ai essayé de récupérer les règles CSS originales (provenant des fichiers CSS sur le site web). Assez étonnamment, c'est très simple grâce à window.getMatchedCSSRules() , cependant, il ne fonctionne pas bien. Le problème était que nous ne prenions qu'une partie des sélecteurs HTML et CSS qui concordaient dans le contexte de l'ensemble du document, qui ne concordaient plus dans le contexte D'un extrait HTML. Comme l'analyse et la modification des sélecteurs ne semblaient pas être une bonne idée, j'ai renoncé à cette tentative.
Deuxième tentative - getComputedStyle()
alors, j'ai commencé par quelque chose que @CollectiveCognition a suggéré - getComputedStyle() . Cependant, je voulais vraiment séparer CSS form HTML au lieu d'inclure tous les styles.
Problème 1-séparer CSS de HTML
la solution ici n'était pas très belle mais assez simple. J'ai assigné des ID à tous les noeuds dans le sous-arbre sélectionné et j'ai utilisé cet ID pour créer des règles CSS appropriées.
Problème 2-suppression des propriétés avec des valeurs par défaut
assigner des ID aux noeuds s'est bien passé, cependant j'ai découvert que chacune de mes règles CSS a ~300 propriétés rendant l'ensemble du CSS illisible.
Il s'avère que getComputedStyle() renvoie toutes les propriétés CSS possibles et les valeurs calculées pour l'élément donné. Certains d'entre eux où vide, certains avaient navigateur valeurs par défaut. Pour supprimer les valeurs par défaut, je devais les obtenir à partir du navigateur en premier (et chaque étiquette a des valeurs par défaut différentes). La solution était de comparer les styles de l'élément provenant du site Web avec le même élément inséré dans un vide <iframe> . La logique ici était qu'il n'y avait pas de feuilles de style dans un <iframe> vide , de sorte que chaque élément que j'ai ajouté n'avait que des styles de navigateur par défaut. De cette façon, j'ai pu me débarrasser de la plupart des propriétés qui étaient insignifiantes.
problème 3-Ne conserver que des propriétés sténographiques
la chose suivante que j'ai remarquée était que les propriétés ayant l'équivalent en sténo étaient inutilement imprimées (par exemple il y avait border: solid black 1px et puis border-color: black; , border-width: 1px itd.).
Pour résoudre cela, j'ai simplement créé une liste de propriétés qui ont abréviation équivalents et filtrée à partir de résultats.
problème 4-suppression des propriétés préfixées
le nombre de propriétés dans chaque règle était beaucoup plus bas après l'opération précédente, mais j'ai trouvé que je sill avait beaucoup de -webkit- propriétés préfixées que je n'ai jamais entendu parler de ( -webkit-app-region ? -webkit-text-emphasis-position ?).
Je me demandais si je devais garder l'une de ces propriétés parce que certaines d'entre elles semblaient utiles ( -webkit-transform-origin , -webkit-perspective-origin etc.). Je n'ai pas trouvé comment vérifier cela, cependant, et puisque je savais que la plupart du temps ces propriétés sont juste des ordures, j'ai décidé de les enlever tous.
problème 5-combinaison des mêmes règles CSS
le problème suivant que j'ai repéré était que les mêmes règles CSS sont répétées encore et encore (par exemple pour chaque <li> avec les mêmes styles exacts il y avait la même règle dans la sortie CSS créée).
Il s'agissait simplement de comparer des règles entre elles et de les combiner qui avaient exactement le même ensemble de propriétés et de valeurs. En conséquence, au lieu de #LI_1{...}, #LI_2{...} j'ai eu #LI_1, #LI_2 {...} .
problème 6-nettoyage et fixation de l'indentation HTML
comme j'étais satisfait du résultat, j'ai déménagé en HTML. Cela ressemblait à un gâchis, principalement parce que la propriété outerHTML la garde formatée exactement comme elle a été retournée par le serveur.
La seule chose dont le code HTML a été extrait de outerHTML était un simple reformatage du code. Puisque c'est quelque chose disponible dans chaque IDE, j'étais sûr qu'il y a un Bibliothèque JavaScript qui fait exactement cela. Et il s'avère que j'avais raison (jQuery-clean) . De plus, j'ai supprimé des attributs inutiles ( style , data-ng-repeat , etc.).
problème 7-filtres cassant CSS
Puisqu'il y a une chance que dans certaines circonstances les filtres mentionnés ci-dessus puissent casser CSS dans l'extrait, je les ai tous rendus optionnels. Vous pouvez les désactiver du Les paramètres dans le menu.
les navigateurs Webkit (pas sûr à propos de FireBug) vous permettent de copier le HTML d'un élément facilement, donc c'est une partie du processus hors du chemin.
exécuter ceci (dans la console javascript) avant de copier le HTML pour un élément déplacera tous les styles calculés pour l'élément parent donné, ainsi que tous les éléments enfants, dans l'attribut style inline qui sera alors disponible en tant que partie du HTML.
var el = document.querySelector("#someid");
var els = el.getElementsByTagName("*");
for(var i = -1, l = els.length; ++i < l;){
els[i].setAttribute("style", window.getComputedStyle(els[i]).cssText);
}
c'est un total hack et vous aurez beaucoup d'attributs CSS "junk" à parcourir, mais devrait au moins commencer.
j'ai posé cette question à l'origine, je cherchais une solution Chrome (ou FireFox), mais je suis tombé sur cette fonctionnalité dans Internet Explorer developer tools. À peu près ce que je cherche (sauf le javascript)
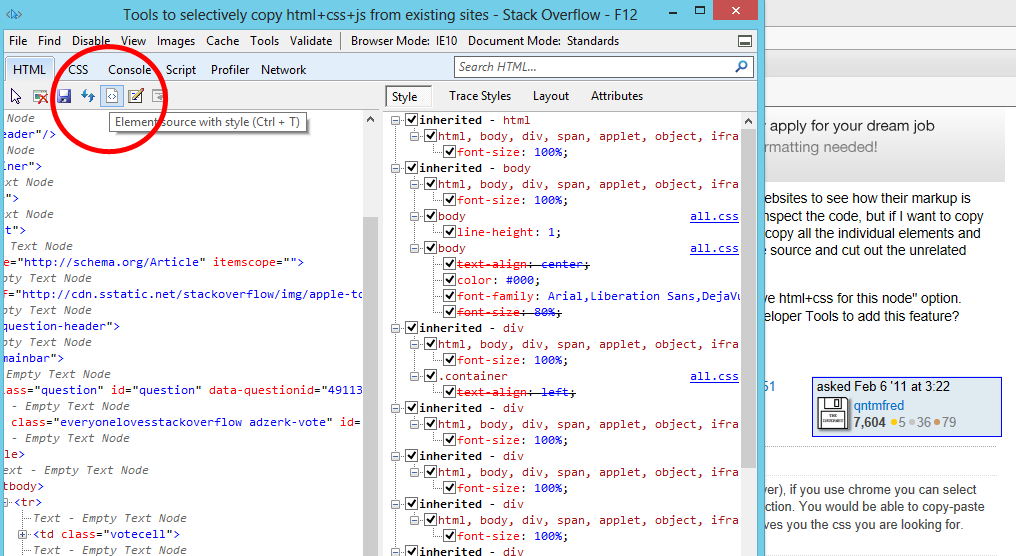
résultat:
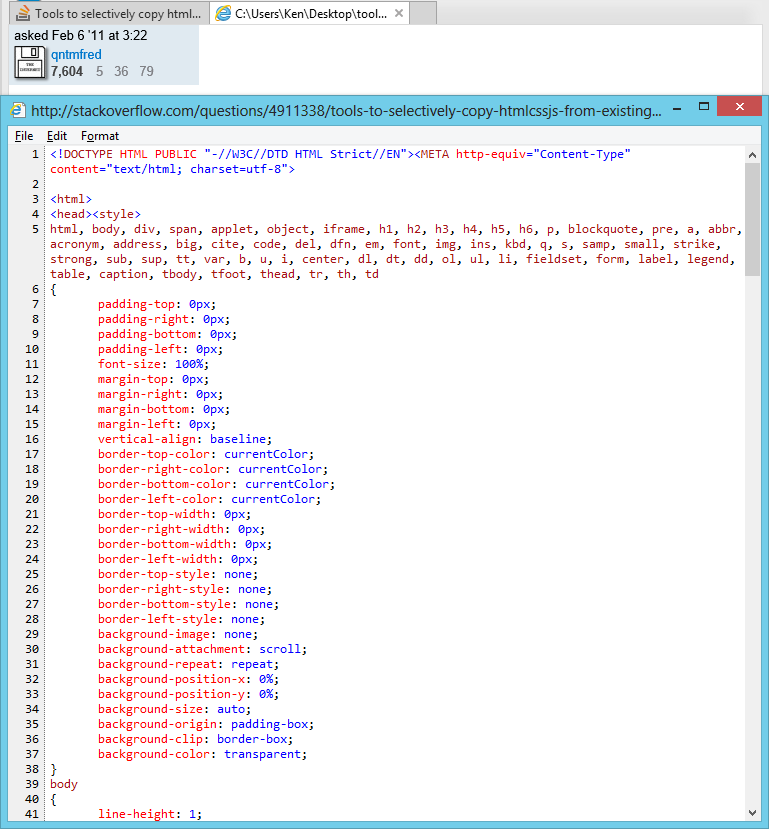
j'ai créé cet outil il y a des années dans le même but:
http://www.betterprogramming.com/htmlclipper.html
vous pouvez l'utiliser et l'améliorer.
cela peut être fait par le Plugin Firebug appelé scrapbook
vous pouvez vérifier l'option Javascript dans le paramètre
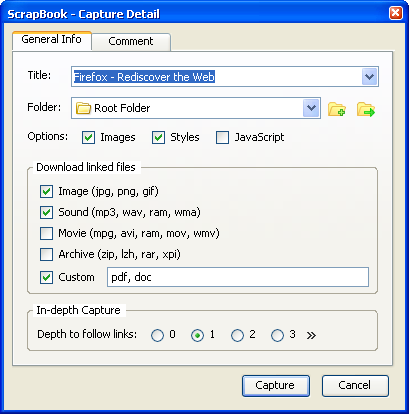
Edit:
Ce peut aussi aider à
Firequark est une extension de Firebugg pour faciliter le processus de L'écran HTML Raclage. Firequark automatiquement extrait le sélecteur css pour un plusieurs html nœud(s) à partir d'une page web L'utilisation de Firebug (un développement web plugin pour Firefox). Le sélecteur css généré peut être fournie en entrée à scrapers d'écran html comme Scrapi à extraire de l'information. Firequark est construit pour libérer la puissance de css sélecteur pour l'utilisation de html écran raclage.
divclip est une mise à jour version de celui de Florentin Sardan htmlclipper
moderne, avec des améliorations: ES5, HTML5, CSS délimités...
vous pouvez extraire programmatiquement une div stylisée avec:
var html = require("divclip").bySel(".article-body");
console.log(html);
de Profiter de.
il n'y a pas besoin de plugins. Cela peut être fait très simplement avec Internet Explorer 11 native Developer Tools en un seul clic, très propre. Juste sur un élément et d'inspecter l'élément et cliquez-droit sur certains bloc et choisissez "Copier l'élément avec des styles". Vous pouvez le voir dans l'image ci-dessous.
il fournit le code css très propre, comme
.menu {
margin: 0;
}
.menu li {
list-style: none;
}
récemment, j'ai créé une extension chrome "extrait Snippet" pour copier l'élément inspecté, html et seulement les questions CSS et médias pertinents à partir d'une page. Notez que cela vous donnerait le CSS pertinent réel
https://chrome.google.com/webstore/detail/extract-snippet/bfcjfegkgdoomgmofhcidoiampnpbdao?hl=en
un outil avec une solution unique pour ce que je ne connais pas, mais vous pouvez utiliser Firebug et Web Developer extension en même temps.
utilisez Firebug pour copier la section html dont vous avez besoin (inspecter L'élément) et le développeur Web pour voir quel css est associé à un élément (appelant le développeur Web "Afficher les informations de Style" - cela fonctionne comme "inspecter L'élément" de Firebug, mais au lieu d'afficher le balisage html il montre le CSS associé avec ce balisage.)
Ce n'est pas exactement ce que vous voulez (un clic pour tout), mais c'est assez proche, et au moins intuitif.
http://clipboard.com fait ceci et assez bien. Bien que votre attente de la version copiée étant exactement comme dans l'original de sorte que vous pouvez jouer et apprendre avec elle, peut ne pas être réaliste.
j'ai aussi besoin de cette fonctionnalité sur Firebug! D'ici là, une autre approche consiste à utiliser ce "service en ligne 151920920" pour supprimer les classes et convertir les css en styles inline.
il suffit de copier la partie que vous voulez à partir de la page Web et de la coller dans l'éditeur wysiwyg. Vérifiez la source html en cliquant sur le bouton "source" dans la barre d'outils de l'éditeur.
j'ai trouvé cela plus facile quand je travaillais sur un site Drupal. J'utilise WYSIWYG CKeditor.
jQuery.fn.extend({
getStyles: function() {
var rulesUsed = [];
var sheets = document.styleSheets;
for (var c = 0; c < sheets.length; c++) {
var rules = sheets[c].rules || sheets[c].cssRules;
for (var r = 0; r < rules.length; r++) {
var selectorText = rules[r].selectorText.toLowerCase().replace(":hover","");
if (this.is(selectorText) || this.find(selectorText).length > 0) {
rulesUsed.push(rules[r]);
}
}
}
var style = rulesUsed.map(function(cssRule) {
return cssRule.selectorText.toLowerCase() + ' { ' + cssRule.style.cssText.toLowerCase() + ' }';
}).join("\n");
return style;
}
});
utilisation:
$("#login_wrapper").getStyles()
j'ai adapté le top réponse votée comme un bookmarklet de dragabble.
il suffit de visiter cette page et de glisser le bouton" Run jQuery Code " dans votre barre de signet.
il y a un plugin firefox qui sauve le HTML de la page entière, CSS, etc.. mais je n'ai pas vu un seul qui n'partielle enregistrer.
je me souviens IE 5.5 a ce que vous recherchez ;)
j'ai traversé tous les outils mentionnés comme réponse ici. Mais ils donnent répété, sale HTML CSS avec beau visage que vous regardiez vers le haut sur. Ils ne te donnent pas de JS.
Ce que je fais:
- D'abord je filtre des annonces qui ne sont pas obligatoires sur la page
- ensuite , sauvegardez la page web complète avec les ressources de lien.
- Supprimer HTML, CSS et JS inutiles
- continue de déverrouiller ressources un par un avec soin.