Performances bêta Swift: tri des tableaux
J'implémentais un algorithme dans Swift Beta et j'ai remarqué que les performances étaient très médiocres. Après avoir creusé plus profondément, j'ai réalisé que l'un des goulots d'étranglement était quelque chose d'aussi simple que le tri des tableaux. La partie pertinente est ici:
let n = 1000000
var x = [Int](repeating: 0, count: n)
for i in 0..<n {
x[i] = random()
}
// start clock here
let y = sort(x)
// stop clock here
En C++, une opération similaire prend 0.06 s sur mon ordinateur.
En Python, il faut 0.6 S (Pas de trucs, juste y = trié (x) pour une liste d'entiers).
Dans Swift prend 6 si je le compile avec le commande suivante:
xcrun swift -O3 -sdk `xcrun --show-sdk-path --sdk macosx`
Et il faut autant que 88s si je compile avec la commande suivante:
xcrun swift -O0 -sdk `xcrun --show-sdk-path --sdk macosx`
Les Timings dans Xcode avec les builds "Release" et "Debug" sont similaires.
Qu'est-ce qui ne va pas ici? Je pourrais comprendre une perte de performance en comparaison avec C++, mais pas un ralentissement 10 fois par rapport à Python pur.
Edit: mweathers a remarqué que changer -O3 en -Ofast rend ce code presque aussi rapide que le c++ la version! Cependant, -Ofast change beaucoup la sémantique du langage - dans mes tests, il a désactivé les contrôles pour les débordements d'entiers et les débordements d'indexation de tableau . Par exemple, avec -Ofast, le code Swift suivant s'exécute silencieusement sans s'écraser (et imprime des déchets):
let n = 10000000
print(n*n*n*n*n)
let x = [Int](repeating: 10, count: n)
print(x[n])
Donc -Ofast n'est pas ce que nous voulons; L'intérêt de Swift est que nous avons les filets de sécurité en place. Bien sûr, les filets de sécurité ont un certain impact sur la performance, mais ils ne devraient pas programmes 100 fois plus lents. Rappelez-vous que Java vérifie déjà les limites du tableau, et dans les cas typiques, le ralentissement est d'un facteur beaucoup moins que 2. Et dans Clang et GCC, nous avons -ftrapv pour vérifier les débordements entiers (signés), et ce n'est pas si lent non plus.
D'où la question: Comment Pouvons-nous obtenir une performance raisonnable dans Swift sans perdre les filets de sécurité?
Edit 2: j'ai fait un peu plus de benchmarking, avec des boucles très simples le long des lignes de
for i in 0..<n {
x[i] = x[i] ^ 12345678
}
(ici, l'opération xor est là juste pour que je puisse plus facilement trouver la boucle pertinente dans le code d'assemblage. J'ai essayé de choisir une opération facile à repérer mais aussi "inoffensive" en ce sens qu'elle ne devrait pas nécessiter de vérifications liées aux débordements d'entiers.)
Encore une fois, il y avait une énorme différence dans les performances entre -O3 et -Ofast. J'ai donc regardé le code d'assemblage:
Avec
-Ofast, j'obtiens à peu près ce à quoi je m'attendais. Le la partie pertinente est une boucle avec 5 instructions de langage machine.Avec
-O3je reçois quelque chose qui était au-delà de mon imagination la plus folle. La boucle intérieure s'étend sur 88 lignes de code d'assemblage. Je n'ai pas essayé de tout comprendre, mais les parties les plus suspectes sont 13 invocations de "callq _swift_retain" et 13 autres invocations de "callq _swift_release". C'est-à-dire 26 appels de sous-programme dans la boucle interne !
Edit 3: Dans les commentaires, Ferruccio a demandé des benchmarks équitables en ce sens qu'ils ne reposent pas sur des fonctions intégrées (par exemple, le tri). Je pense que le programme suivant est un assez bon exemple:
let n = 10000
var x = [Int](repeating: 1, count: n)
for i in 0..<n {
for j in 0..<n {
x[i] = x[j]
}
}
Il n'y a pas d'arithmétique, donc nous n'avons pas besoin de nous soucier des débordements entiers. La seule chose que nous faisons est juste beaucoup de références de tableau. Et les résultats sont ici-Swift-O3 perd par facteur près de 500 en comparaison avec-Ofast:
- C++ - O3: 0.05 s
- C++ - O0: 0,4 s
- Java: 0,2 s
- Python avec PyPy: 0.5 s
- Python: 12 s
- Swift-Ofast: 0.05 s
- Swift-O3: 23 s
- Swift-O0: 443 s
(Si vous craignez que le compilateur optimise entièrement les boucles inutiles, vous pouvez le changer en x[i] ^= x[j], et ajouter une instruction print qui génère x[0]. Cela ne change rien; les timings seront très similaires.)
Et oui, ici l'implémentation Python était une implémentation Python pure stupide avec une liste d'ints et imbriquée pour les boucles. Il devrait être beaucoup plus lent que Swift non optimisé. Quelque chose semble être sérieusement cassé avec L'indexation Swift et array.
Edit 4: ces problèmes (ainsi que d'autres problèmes de performance) semblent avoir été corrigés dans Xcode 6 beta 5.
Pour le tri, j'ai maintenant les timings suivants:
- clang++ - O3: 0.06 s
- swiftc - Ofast: 0,1 s
- swiftc-O: 0,1 s
- swiftc: 4 s
Pour les boucles imbriquées:
- clang++ - O3: 0.06 s
- swiftc-Ofast: 0,3 s
- swiftc-O: 0,4 s
- swiftc: 540 s
Il semble qu'il n'y ait plus de raison d'utiliser le non sécurisé -Ofast (alias -Ounchecked); plain -O produit un code tout aussi bon.
8 réponses
Tl; Dr Swift 1.0 est maintenant aussi rapide que C par ce benchmark en utilisant le niveau d'optimisation de version par défaut [- O].
Voici un quicksort en place dans Swift Beta:
func quicksort_swift(inout a:CInt[], start:Int, end:Int) {
if (end - start < 2){
return
}
var p = a[start + (end - start)/2]
var l = start
var r = end - 1
while (l <= r){
if (a[l] < p){
l += 1
continue
}
if (a[r] > p){
r -= 1
continue
}
var t = a[l]
a[l] = a[r]
a[r] = t
l += 1
r -= 1
}
quicksort_swift(&a, start, r + 1)
quicksort_swift(&a, r + 1, end)
}
Et la même chose en C:
void quicksort_c(int *a, int n) {
if (n < 2)
return;
int p = a[n / 2];
int *l = a;
int *r = a + n - 1;
while (l <= r) {
if (*l < p) {
l++;
continue;
}
if (*r > p) {
r--;
continue;
}
int t = *l;
*l++ = *r;
*r-- = t;
}
quicksort_c(a, r - a + 1);
quicksort_c(l, a + n - l);
}
Les deux fonctionnent:
var a_swift:CInt[] = [0,5,2,8,1234,-1,2]
var a_c:CInt[] = [0,5,2,8,1234,-1,2]
quicksort_swift(&a_swift, 0, a_swift.count)
quicksort_c(&a_c, CInt(a_c.count))
// [-1, 0, 2, 2, 5, 8, 1234]
// [-1, 0, 2, 2, 5, 8, 1234]
Les deux sont appelés dans le même programme qu'écrit.
var x_swift = CInt[](count: n, repeatedValue: 0)
var x_c = CInt[](count: n, repeatedValue: 0)
for var i = 0; i < n; ++i {
x_swift[i] = CInt(random())
x_c[i] = CInt(random())
}
let swift_start:UInt64 = mach_absolute_time();
quicksort_swift(&x_swift, 0, x_swift.count)
let swift_stop:UInt64 = mach_absolute_time();
let c_start:UInt64 = mach_absolute_time();
quicksort_c(&x_c, CInt(x_c.count))
let c_stop:UInt64 = mach_absolute_time();
Cela convertit les temps absolus en secondes:
static const uint64_t NANOS_PER_USEC = 1000ULL;
static const uint64_t NANOS_PER_MSEC = 1000ULL * NANOS_PER_USEC;
static const uint64_t NANOS_PER_SEC = 1000ULL * NANOS_PER_MSEC;
mach_timebase_info_data_t timebase_info;
uint64_t abs_to_nanos(uint64_t abs) {
if ( timebase_info.denom == 0 ) {
(void)mach_timebase_info(&timebase_info);
}
return abs * timebase_info.numer / timebase_info.denom;
}
double abs_to_seconds(uint64_t abs) {
return abs_to_nanos(abs) / (double)NANOS_PER_SEC;
}
Voici un résumé des niveaux d'optimisation du compilateur:
[-Onone] no optimizations, the default for debug.
[-O] perform optimizations, the default for release.
[-Ofast] perform optimizations and disable runtime overflow checks and runtime type checks.
Temps en secondes avec [Individualisé] pour n=10_000:
Swift: 0.895296452
C: 0.001223848
Voici la fonction intégrée de Swift sort () pour n=10_000:
Swift_builtin: 0.77865783
Ici [-O] pour n=10_000:
Swift: 0.045478346
C: 0.000784666
Swift_builtin: 0.032513488
Comme vous pouvez le voir, les performances de Swift ont été multipliées par 20.
Selon la réponse de mweathers , La définition de [- Ofast] fait la vraie différence, ce qui entraîne ces temps pour n=10_000:
Swift: 0.000706745
C: 0.000742374
Swift_builtin: 0.000603576
Et pour n=1_000_000:
Swift: 0.107111846
C: 0.114957179
Swift_sort: 0.092688548
Pour la comparaison, c'est avec [Individualisé] pour n=1_000_000:
Swift: 142.659763258
C: 0.162065333
Swift_sort: 114.095478272
Donc Swift sans optimisations était presque 1000x plus lent que C dans ce benchmark, à ce stade de son développement. D'autre part, avec les deux compilateurs définis sur [-Ofast] Swift a effectivement effectué au moins aussi bien sinon légèrement mieux que C.
, Il a été souligné que [-Ofast] la sémantique de la langue, rendant potentiellement dangereux. C'est ce que déclare Apple dans les notes de version de Xcode 5.0:
Un nouveau niveau d'optimisation-Ofast, disponible dans LLVM, permet des optimisations agressives. - Ofast détend certaines restrictions conservatrices, principalement pour les opérations à virgule flottante, qui sont sûres pour la plupart du code. Il peut produire des gains significatifs de haute performance du compilateur.
Ils le préconisent tous. Que ce soit sage ou Non, Je ne pouvais pas dire, mais de ce que je peux dire, il semble assez raisonnable pour utiliser [- Ofast] dans une version si vous ne faites pas d'arithmétique à virgule flottante de haute précision et que vous êtes sûr qu'aucun débordement d'entier ou de tableau n'est possible dans votre programme. Si vous avez besoin de contrôles de débordement et haute performance / arithmétique précise, choisissez une autre langue pour l'instant.
MISE À JOUR BÊTA 3:
N=10_000 avec [-O]:
Swift: 0.019697268
C: 0.000718064
Swift_sort: 0.002094721
Swift en général est un peu plus rapide et il semble que le tri intégré de Swift ait changé de manière significative.
MISE À JOUR FINALE:
[-Onone]:
Swift: 0.678056695
C: 0.000973914
[-O]:
Swift: 0.001158492
C: 0.001192406
[-Ounchecked]:
Swift: 0.000827764
C: 0.001078914
TL; DR : Oui, la seule implémentation du langage Swift est lente, en ce moment . Si vous avez besoin de code rapide, numérique (et d'autres types de code, probablement), allez-y avec un autre. À l'avenir, vous devriez réévaluer votre choix. Il pourrait être assez bon pour la plupart du code d'application qui est écrit à un niveau supérieur, cependant.
D'après ce que je vois dans SIL et LLVM IR, il semble qu'ils aient besoin d'un tas d'optimisations pour supprimer les retains et les releases, ce qui pourrait être implémenté dans Clang (pour Objective-C), mais ils ne les ont pas encore portés. C'est la théorie avec laquelle je vais (pour l'instant... je dois encore confirmer que Clang fait quelque chose à ce sujet), car un profileur exécuté sur le dernier cas de test de cette question donne ce résultat" joli":
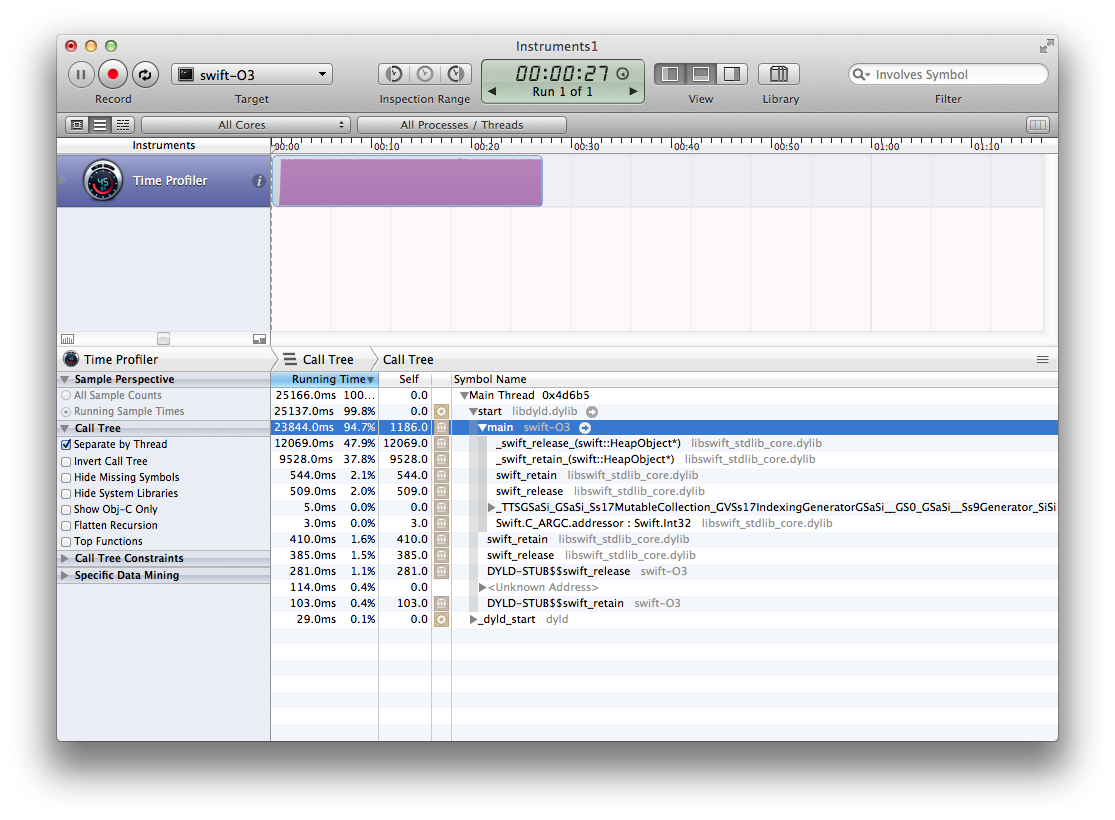
Comme l'ont dit beaucoup d'autres, -Ofast est totalement dangereux et change la sémantique du langage. Pour moi, c'est à l'étape" si vous allez l'utiliser, utilisez simplement une autre langue". Je vais réévaluer ce choix plus tard, si elle change.
-O3 nous obtient un tas de swift_retain et swift_release appels qui, honnêtement, ne me regardez pas comme ils devraient être là pour cet exemple. L'optimiseur aurait dû les élider (la plupart) AFAICT, car il connaît la plupart des informations sur le tableau, et sait qu'il a (au moins) une référence forte à celui-ci.
Il ne devrait pas émettre plus de retenues quand il n'appelle même pas de fonctions qui pourraient libérer les objets. Je ne pense pas qu'un constructeur de tableau peut retourner un tableau qui est plus petit que ce qui était demandé, ce qui signifie que beaucoup de vérifications qui ont été émises sont inutiles. Il sait aussi que l'entier ne sera jamais supérieur à 10k, donc les contrôles de débordement peuvent être optimisés (pas à cause de -Ofast bizarrerie, mais à cause de la sémantique du langage (rien d'autre ne change que var ne peut y accéder, et ajouter jusqu'à 10k est sûr pour le type Int).
Le compilateur peut ne pas pouvoir déballer le tableau ou le tableau les éléments, cependant, puisqu'ils sont passés à sort(), qui est une fonction externe et doit obtenir les arguments qu'elle attend. Cela nous obligera à utiliser indirectement les valeurs Int, ce qui le rendrait un peu plus lent. Cela pourrait changer si la fonction générique sort() (Pas de la manière multi-méthode) était disponible pour le compilateur et était inline.
C'est un langage très nouveau (publiquement), et il traverse ce que je suppose être beaucoup de changements, car il y a des gens (fortement) impliqué dans la langue Swift demandant des commentaires et ils disent tous que la langue n'est pas terminée et changera.
Code utilisé:
import Cocoa
let swift_start = NSDate.timeIntervalSinceReferenceDate();
let n: Int = 10000
let x = Int[](count: n, repeatedValue: 1)
for i in 0..n {
for j in 0..n {
let tmp: Int = x[j]
x[i] = tmp
}
}
let y: Int[] = sort(x)
let swift_stop = NSDate.timeIntervalSinceReferenceDate();
println("\(swift_stop - swift_start)s")
P. S: Je ne suis pas un expert sur Objective-C Ni toutes les installations de Cocoa , Objective-C, ou les runtimes Swift. Je pourrais aussi supposer des choses que je n'ai pas écrites.
J'ai décidé de jeter un oeil à cela pour le plaisir, et voici les horaires que je reçois:
Swift 4.0.2 : 0.83s (0.74s with `-Ounchecked`)
C++ (Apple LLVM 8.0.0): 0.74s
Swift
// Swift 4.0 code
import Foundation
func doTest() -> Void {
let arraySize = 10000000
var randomNumbers = [UInt32]()
for _ in 0..<arraySize {
randomNumbers.append(arc4random_uniform(UInt32(arraySize)))
}
let start = Date()
randomNumbers.sort()
let end = Date()
print(randomNumbers[0])
print("Elapsed time: \(end.timeIntervalSince(start))")
}
doTest()
Résultats:
Swift 1.1
xcrun swiftc --version
Swift version 1.1 (swift-600.0.54.20)
Target: x86_64-apple-darwin14.0.0
xcrun swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 1.02204304933548
Swift 1.2
xcrun swiftc --version
Apple Swift version 1.2 (swiftlang-602.0.49.6 clang-602.0.49)
Target: x86_64-apple-darwin14.3.0
xcrun -sdk macosx swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 0.738763988018036
Swift 2.0
xcrun swiftc --version
Apple Swift version 2.0 (swiftlang-700.0.59 clang-700.0.72)
Target: x86_64-apple-darwin15.0.0
xcrun -sdk macosx swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 0.767306983470917
Il semble être la même performance si je compile avec -Ounchecked.
Swift 3.0
xcrun swiftc --version
Apple Swift version 3.0 (swiftlang-800.0.46.2 clang-800.0.38)
Target: x86_64-apple-macosx10.9
xcrun -sdk macosx swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 0.939633965492249
xcrun -sdk macosx swiftc -Ounchecked SwiftSort.swift
./SwiftSort
Elapsed time: 0.866258025169373
Il semble y avoir eu une régression des performances de Swift 2.0 à Swift 3.0, et je vois aussi un différence entre -O et -Ounchecked, pour la première fois.
Swift 4.0
xcrun swiftc --version
Apple Swift version 4.0.2 (swiftlang-900.0.69.2 clang-900.0.38)
Target: x86_64-apple-macosx10.9
xcrun -sdk macosx swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 0.834299981594086
xcrun -sdk macosx swiftc -Ounchecked SwiftSort.swift
./SwiftSort
Elapsed time: 0.742045998573303
Swift 4 Améliore à nouveau les performances, tout en maintenant un écart entre -O et -Ounchecked. -O -whole-module-optimization ne semblait pas faire de différence.
C++
#include <chrono>
#include <iostream>
#include <vector>
#include <cstdint>
#include <stdlib.h>
using namespace std;
using namespace std::chrono;
int main(int argc, const char * argv[]) {
const auto arraySize = 10000000;
vector<uint32_t> randomNumbers;
for (int i = 0; i < arraySize; ++i) {
randomNumbers.emplace_back(arc4random_uniform(arraySize));
}
const auto start = high_resolution_clock::now();
sort(begin(randomNumbers), end(randomNumbers));
const auto end = high_resolution_clock::now();
cout << randomNumbers[0] << "\n";
cout << "Elapsed time: " << duration_cast<duration<double>>(end - start).count() << "\n";
return 0;
}
Résultats:
Apple Clang 6.0
clang++ --version
Apple LLVM version 6.0 (clang-600.0.54) (based on LLVM 3.5svn)
Target: x86_64-apple-darwin14.0.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.688969
Apple Clang 6.1.0
clang++ --version
Apple LLVM version 6.1.0 (clang-602.0.49) (based on LLVM 3.6.0svn)
Target: x86_64-apple-darwin14.3.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.670652
Apple Clang 7.0.0
clang++ --version
Apple LLVM version 7.0.0 (clang-700.0.72)
Target: x86_64-apple-darwin15.0.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.690152
Clang De Pomme 8.0.0
clang++ --version
Apple LLVM version 8.0.0 (clang-800.0.38)
Target: x86_64-apple-darwin15.6.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.68253
Apple Clang 9.0.0
clang++ --version
Apple LLVM version 9.0.0 (clang-900.0.38)
Target: x86_64-apple-darwin16.7.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.736784
Verdict
Au moment d'écrire ces lignes, le tri de Swift est rapide, mais pas encore aussi rapide que le tri C++lorsqu'il est compilé avec -O, avec les compilateurs et bibliothèques ci-dessus. Avec -Ounchecked, Il semble être aussi rapide que C++ dans Swift 4.0.2 et Apple LLVM 9.0.0.
De The Swift Programming Language:
La bibliothèque standard de la fonction de tri Swift fournit une fonction appelée trier, qui trie un tableau de valeurs d'un type connu, basé sur la sortie d'une fermeture de tri que vous fournissez. Une fois terminé, l' processus de tri, la fonction de tri renvoie un nouveau tableau de la même type et taille comme l'ancien, avec ses éléments dans le bon trié ordre.
La fonction sort a deux déclarations.
La valeur par défaut déclaration qui vous permet de spécifier une fermeture de comparaison:
func sort<T>(array: T[], pred: (T, T) -> Bool) -> T[]
Et une deuxième déclaration qui ne prend qu'un seul paramètre (le tableau )et est " codé en dur pour utiliser le comparateur moins que."
func sort<T : Comparable>(array: T[]) -> T[]
Example:
sort( _arrayToSort_ ) { $0 > $1 }
J'ai testé une version modifiée de votre code dans un terrain de jeu avec la fermeture ajoutée pour que je puisse surveiller la fonction un peu plus étroitement, et j'ai trouvé qu'avec n réglé sur 1000, la fermeture était appelée environ 11 000 fois.
let n = 1000
let x = Int[](count: n, repeatedValue: 0)
for i in 0..n {
x[i] = random()
}
let y = sort(x) { $0 > $1 }
Ce n'est pas une fonction efficace, un Je recommanderais d'utiliser une meilleure implémentation de la fonction de tri.
Modifier:
J'ai jeté un coup d'oeil à la page wikipedia Quicksort et j'ai écrit une implémentation rapide pour cela. Voici le programme complet que j'ai utilisé (dans une aire de jeux)
import Foundation
func quickSort(inout array: Int[], begin: Int, end: Int) {
if (begin < end) {
let p = partition(&array, begin, end)
quickSort(&array, begin, p - 1)
quickSort(&array, p + 1, end)
}
}
func partition(inout array: Int[], left: Int, right: Int) -> Int {
let numElements = right - left + 1
let pivotIndex = left + numElements / 2
let pivotValue = array[pivotIndex]
swap(&array[pivotIndex], &array[right])
var storeIndex = left
for i in left..right {
let a = 1 // <- Used to see how many comparisons are made
if array[i] <= pivotValue {
swap(&array[i], &array[storeIndex])
storeIndex++
}
}
swap(&array[storeIndex], &array[right]) // Move pivot to its final place
return storeIndex
}
let n = 1000
var x = Int[](count: n, repeatedValue: 0)
for i in 0..n {
x[i] = Int(arc4random())
}
quickSort(&x, 0, x.count - 1) // <- Does the sorting
for i in 0..n {
x[i] // <- Used by the playground to display the results
}
En utilisant ceci avec n = 1000, j'ai trouvé que
- quickSort () a été appelé environ 650 fois,
- environ 6000 swaps ont été effectués,
- et il y a environ 10 000 comparaisons
Il semble que le tri intégré la méthode est (ou est proche de) un tri rapide, et est vraiment lente...
À partir de Xcode 7, vous pouvez activer Fast, Whole Module Optimization. Cela devrait augmenter vos performances immédiatement.

Performances du tableau Swift revisitées:
J'ai écrit mon propre benchmark comparant Swift avec C / Objective - C. Mon benchmark calcule les nombres premiers. Il utilise le tableau des nombres premiers précédents pour rechercher des facteurs premiers dans chaque nouveau candidat, donc c'est assez rapide. Cependant, il fait des tonnes de lecture de tableau, et moins d'écriture dans les tableaux.
J'ai initialement fait ce benchmark contre Swift 1.2. J'ai décidé de mettre à jour le projet et de l'exécuter contre Swift 2.0.
Le projet vous permet Choisissez entre l'utilisation de tableaux swift normaux et L'utilisation de tampons de mémoire non sécurisés Swift en utilisant la sémantique de tableau.
Pour C / Objective-C, vous pouvez choisir D'utiliser NSArrays ou c malloc'ed arrays.
Les résultats du test semblent être assez similaires avec l'optimisation du code la plus rapide et la plus petite ([-0s]) ou l'optimisation la plus rapide et agressive ([-0fast]).
Les performances de Swift 2.0 sont toujours horribles avec l'optimisation du code désactivée, alors que les performances C / Objective-C ne sont que modérément plus lent.
L'essentiel est que les calculs basés sur un tableau c malloc'D sont les plus rapides, par une marge modeste
Swift avec des tampons non sécurisés prend environ 1,19 X-1,20 X plus longtemps que les tableaux c malloc'd Lors de l'utilisation de l'optimisation de code la plus rapide et la plus petite. la différence semble un peu moins avec une optimisation rapide et agressive (Swift prend plus de 1,18 x à 1,16 x plus longtemps que C.
Si vous utilisez des tableaux Swift réguliers, la différence avec C est légèrement plus grande. (Swift prend ~1.22 à 1,23 plus.)
Les tableaux Swift réguliers sont DRAMATICALLY plus rapides que dans Swift 1.2 / Xcode 6. Leurs performances sont si proches des tableaux Swift unsafe buffer basés que l'utilisation de tampons de mémoire non sécurisés ne semble plus en valoir la peine, ce qui est important.
BTW, Objective-C NSArray performance pue. Si vous allez utiliser les objets conteneur natifs dans les deux langues, Swift est considérablement plus rapide.
, Vous pouvez consulter mon projet sur github à SwiftPerformanceBenchmark
Il a une interface utilisateur simple qui rend la collecte des statistiques assez facile.
Il est intéressant que le tri semble être légèrement plus rapide dans Swift qu'en C maintenant, mais que cet algorithme de nombres premiers est encore plus rapide dans Swift.
Le problème principal qui est mentionné par d'autres mais pas assez appelé est que -O3 ne fait rien du tout dans Swift (et n'a jamais) donc lorsqu'il est compilé avec cela, il est effectivement non optimisé (-Onone).
Les noms des options ont changé au fil du temps, de sorte que certaines autres réponses ont des indicateurs obsolètes pour les options de construction. Les options actuelles correctes (Swift 2.2) sont:
-Onone // Debug - slow
-O // Optimised
-O -whole-module-optimization //Optimised across files
L'optimisation du module entier a une compilation plus lente mais peut optimiser les fichiers dans le module, c'est-à-dire dans chaque framework et dans le code de l'application réelle, mais pas entre eux. Vous devriez l'utiliser pour tout ce qui est critique pour les performances)
Vous pouvez également désactiver les contrôles de sécurité pour encore plus de vitesse, mais avec toutes les assertions et conditions préalables non seulement désactivées mais optimisées sur la base qu'elles sont correctes. Si jamais vous frappez une assertion, cela signifie que vous êtes dans un comportement indéfini. Utilisez avec une extrême prudence et seulement si vous déterminez que l'augmentation de vitesse est utile pour vous (en testant). Si vous trouvez qu'il est précieux pour certains codes, je recommande de séparer ce code dans un cadre séparé et de désactiver uniquement les contrôles de sécurité pour ce module.
func partition(inout list : [Int], low: Int, high : Int) -> Int {
let pivot = list[high]
var j = low
var i = j - 1
while j < high {
if list[j] <= pivot{
i += 1
(list[i], list[j]) = (list[j], list[i])
}
j += 1
}
(list[i+1], list[high]) = (list[high], list[i+1])
return i+1
}
func quikcSort(inout list : [Int] , low : Int , high : Int) {
if low < high {
let pIndex = partition(&list, low: low, high: high)
quikcSort(&list, low: low, high: pIndex-1)
quikcSort(&list, low: pIndex + 1, high: high)
}
}
var list = [7,3,15,10,0,8,2,4]
quikcSort(&list, low: 0, high: list.count-1)
var list2 = [ 10, 0, 3, 9, 2, 14, 26, 27, 1, 5, 8, -1, 8 ]
quikcSort(&list2, low: 0, high: list2.count-1)
var list3 = [1,3,9,8,2,7,5]
quikcSort(&list3, low: 0, high: list3.count-1)
Ceci est mon Blog sur Quick Sort- GitHub sample Quick-Sort
Vous pouvez jeter un oeil sur L'algorithme de partitionnement de Lomuto dans le partitionnement de la liste. Écrit en Swift