Présentation des données internes du vecteur statique - 'union' vs ' std:: aligned storage t` - énorme différence de performance
suppose que vous devez mettre en œuvre une classe static_vector<T, N> , qui est un capacité fixe conteneur qui vit entièrement sur la pile et n'allaite jamais, et expose une interface std::vector comme. (Boost fournit boost::static_vector .)
considérant que nous devons avoir uninitialized storage for maximum N instances de T , il y a Plusieurs choix qui peuvent être faits lors de la conception de la mise en page des données internes:
-
Simple membre
union:union U { T _x; }; std::array<U, N> _data; -
Unique
std::aligned_storage_t:std::aligned_storage_t<sizeof(T) * N, alignof(T)> _data; -
Tableau de
std::aligned_storage_t:using storage = std::aligned_storage_t<sizeof(T), alignof(T)>; std::array<storage, N> _data;
quel que soit le choix, la création des membres nécessitera l'utilisation de " placement new " et pour y accéder, il faudra quelque chose du genre reinterpret_cast .
supposons maintenant que nous avons deux implémentations très minimales de static_vector<T, N> :
-
with_union: mis en œuvre en utilisant l'approche "single-memberunion -
with_storage: mis en œuvre en utilisant l'approche "uniquestd::aligned_storage_t".
effectuons le benchmark suivant en utilisant à la fois g++ et clang++ avec -O3 . J'ai utilisé quick-bench.com pour cette tâche :
void escape(void* p) { asm volatile("" : : "g"(p) : "memory"); }
void clobber() { asm volatile("" : : : "memory"); }
template <typename Vector>
void test()
{
for(std::size_t j = 0; j < 10; ++j)
{
clobber();
Vector v;
for(int i = 0; i < 123456; ++i) v.emplace_back(i);
escape(&v);
}
}
( escape et clobber sont tirées de la conférence CppCon 2015 de Chandler Carruth: " Tuning C++: Benchmarks, et CPUs, et compilateurs! Oh Là Là!" )
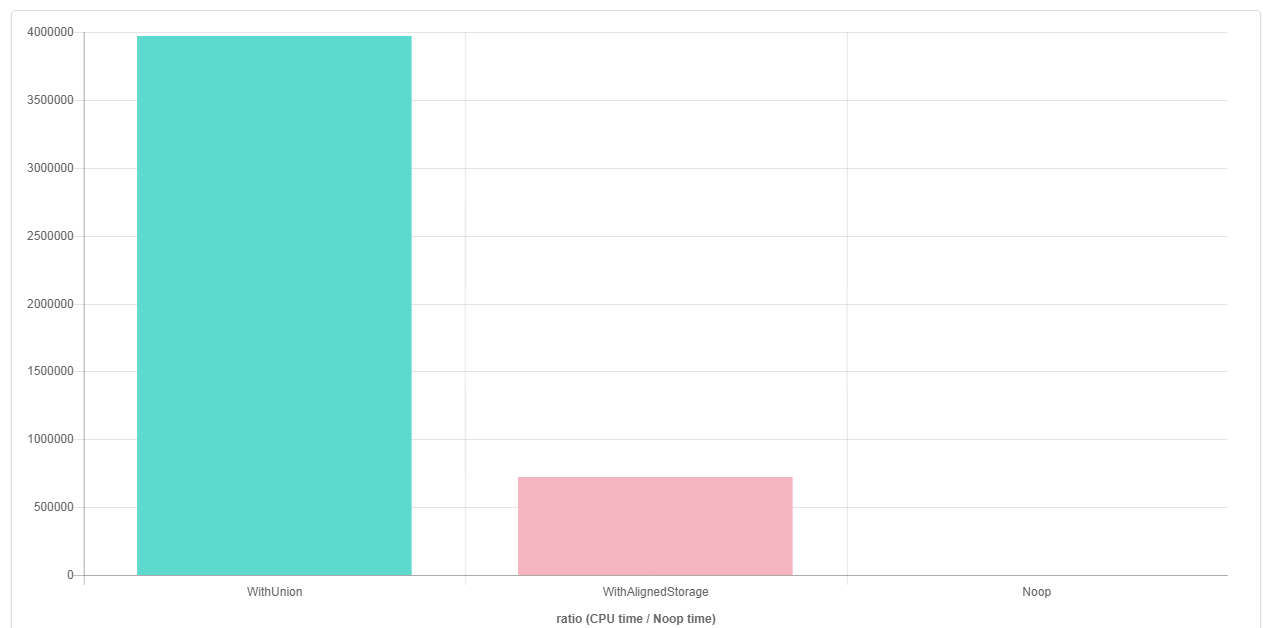
- résultats pour
g++ 7.2( vivre ici ) :
- résultats pour
clang++ 5.0( vivre ici ) :
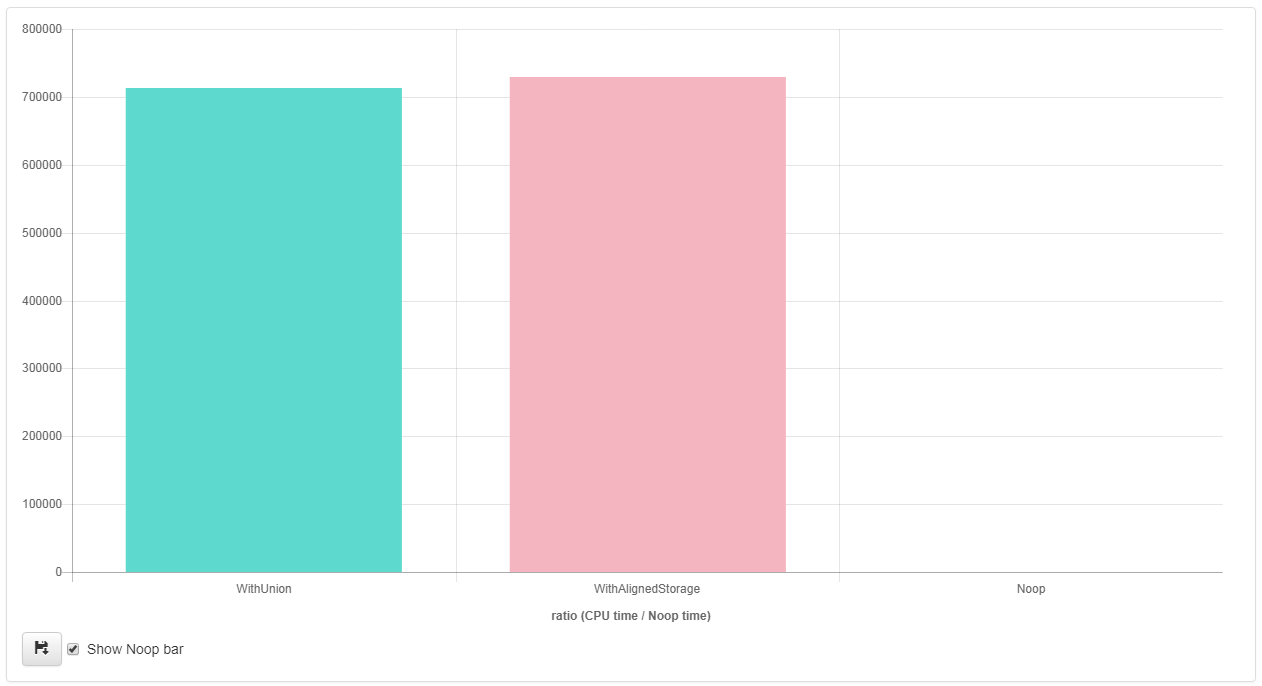
comme vous pouvez le voir à partir des résultats, g++ semble être en mesure d'optimiser de façon agressive (vectorisation) la mise en œuvre qui utilise l'approche" unique std::aligned_storage_t ", mais pas la mise en œuvre en utilisant le union .
mes questions sont:
-
il n'y a rien dans le Une norme qui empêche la mise en œuvre de
uniond'être optimisée de manière agressive? (i. e. la norme accorde - t-elle plus de liberté au compilateur lorsqu'il utilisestd::aligned_storage_t- si oui, pourquoi?) -
est-ce purement une question de "qualité de la mise en œuvre"?
1 réponses
xskxzr est à droite, c'est la même question que dans cette question . Fondamentalement, gcc manque une occasion d'optimisation en oubliant que les données de std::array est aligné. John Zwinck a généreusement signalé bug 80561 .
vous pouvez vérifier cela dans votre benchmark en faisant l'un des deux changements à with_union :
-
changement
_dataà partir d'unstd::array<U, N>tout simplementU[N]. La Performance devient identique -
rappeler à gcc que
_dataest en fait aligné en changeant la mise en œuvre deemplace_back()à:template <typename... Ts> T& emplace_back(Ts&&... xs) { U* data = static_cast<U*>(__builtin_assume_aligned(_data.data(), alignof(U))); T* ptr = &data[_size++]._x; return *(new (ptr) T{std::forward<Ts>(xs)...}); }
L'un ou l'autre de ces changements avec le reste de votre benchmark me donne des résultats comparables entre WithUnion et WithAlignedStorage .