SQLite-UPSERT * not * insérer ou remplacer
http://en.wikipedia.org/wiki/Upsert
Insérer une mise à Jour de procédures stockées sous SQL Server
y a-t-il une façon intelligente de faire cela en SQLite à laquelle je n'ai pas pensé?
Fondamentalement, je veux mettre à jour trois des quatre colonnes si l'enregistrement existe, Si elle n'existe pas, je veux insérer l'enregistrement avec la valeur par défaut (NUL) pour la quatrième colonne.
L'ID est une clé primaire de sorte qu'il n'y aura jamais qu'un enregistrement à UPSERT.
(j'essaie d'éviter les frais généraux de SELECT afin de déterminer si je dois mettre à jour ou insérer évidemment)
Suggestions?
Je ne peux pas confirmer cette syntaxe sur le site SQLite pour table CREATE. Je n'ai pas construit de démo pour le tester, mais il ne semble pas être supporté..
si c'était le cas, j'ai trois colonnes pour qu'il ressemble réellement à:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
Blob1 BLOB ON CONFLICT REPLACE,
Blob2 BLOB ON CONFLICT REPLACE,
Blob3 BLOB
);
mais les deux premiers blobs ne causeront pas de conflit, seul L'ID J'ai donc asusme Blob1 et Blob2 ne seraient pas remplacés (comme souhaité)
Mises à jour dans SQLite, lors de la liaison de données sont d'une transaction complète, sens Chaque ligne envoyée à mettre à jour nécessite: contrairement à L'insertion qui permet l'utilisation de la fonction de réinitialisation
La vie d'un objet statement va quelque chose comme ceci:
- créer l'objet en utilisant sqlite3_prepare_v2 ()
- lie les valeurs aux paramètres de l'hôte en utilisant les interfaces sqlite3_bind_.
- exécutez le SQL en appelant sqlite3_step ()
- réinitialisez la déclaration en utilisant sqlite3_reset () puis retournez à l'étape 2 et répétez.
- détruire l'objet de déclaration en utilisant sqlite3_finalize ().
mise à jour je devine est lent par rapport à insérer, mais comment se compare-t-il de sélectionner à l'aide de la clé primaire?
peut-être devrais-je utiliser le select pour lire la 4ème colonne (Blob3) et utiliser ensuite REPLACE pour écrire un nouvel enregistrement mélangeant la 4ème colonne originale avec les nouvelles données pour les 3 premières colonnes?
17 réponses
sur la base de 3 colonnes du tableau.. ID, NOM, RÔLE
mauvais: ceci insérera ou remplacera toutes les colonnes avec de nouvelles valeurs pour ID=1:
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES (1, 'John Foo', 'CEO');
mauvais: ceci insérera ou remplacera 2 des colonnes... la colonne Nom sera définie à NULL ou la valeur par défaut:
INSERT OR REPLACE INTO Employee (id, role)
VALUES (1, 'code monkey');
BONNE: Ce sera la mise à jour 2 colonnes. Quand ID=1 existe, le nom n'est pas affecté. Quand ID=1 n'existe pas, le nom sera par défaut (NULL).
INSERT OR REPLACE INTO Employee (id, role, name)
VALUES ( 1,
'code monkey',
(SELECT name FROM Employee WHERE id = 1)
);
ceci mettra à jour 2 des colonnes. Quand ID=1 existe, le rôle n'est pas affecté. Quand ID=1 n'existe pas, le rôle sera défini à 'Benchwarmer' au lieu de la valeur par défaut.
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES ( 1,
'Susan Bar',
COALESCE((SELECT role FROM Employee WHERE id = 1), 'Benchwarmer')
);
insérer ou remplacer est et non équivalent à"UPSERT".
dites que j'ai L'employé de la table avec les champs id, nom, et rôle:
INSERT OR REPLACE INTO Employee ("id", "name", "role") VALUES (1, "John Foo", "CEO")
INSERT OR REPLACE INTO Employee ("id", "role") VALUES (1, "code monkey")
Boom, vous avez perdu le nom de l'employé numéro 1. SQLite l'a remplacé par une valeur par défaut.
le résultat attendu d'un UPSERT serait de changer le rôle et de conserver le nom.
la réponse D'Eric B est acceptable si vous voulez préserver juste une ou peut-être deux colonnes de la rangée existante. Si vous voulez préserver beaucoup de colonnes, il devient trop encombrant rapidement.
voici une approche qui s'adaptera bien à n'importe quelle quantité de colonnes de chaque côté. Pour l'illustrer, je supposerai le schéma suivant:
CREATE TABLE page (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE,
title TEXT,
content TEXT,
author INTEGER NOT NULL REFERENCES user (id),
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
noter en particulier que name est la clé naturelle de la rangée – id est utilisé uniquement pour les clés étrangères, de sorte que le point est pour SQLite de choisir la valeur ID elle-même lors de l'insertion d'une nouvelle ligne. Mais lors de la mise à jour d'une rangée existante basée sur son name , je veux qu'elle continue à avoir l'ancienne valeur ID (évidemment!).
je réalise un vrai UPSERT avec la construction suivante:
WITH new (name, title, author) AS ( VALUES('about', 'About this site', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT old.id, new.name, new.title, old.content, new.author
FROM new LEFT JOIN page AS old ON new.name = old.name;
La forme exacte de cette requête peut varier un peu. La clé est l'utilisation de INSERT SELECT avec une jointure externe gauche, pour rejoindre une ligne existante aux nouvelles valeurs.
ici, si une rangée n'existait pas auparavant, old.id sera NULL et SQLite assignera alors un ID automatiquement, mais s'il y avait déjà une telle rangée, old.id aura une valeur réelle et cela sera réutilisé. Ce qui est exactement ce que je voulais.
En fait, c'est très souple. Notez que la colonne ts est complètement absente de tous les côtés – parce qu'elle a une valeur DEFAULT , SQLite je vais juste faire la bonne chose dans tous les cas, pour ne pas avoir à m'en occuper moi-même.
vous pouvez également inclure une colonne sur les deux côtés new et old et ensuite utiliser par exemple COALESCE(new.content, old.content) dans la partie extérieure SELECT pour dire" insérez le nouveau contenu s'il y en avait, sinon conservez l'ancien contenu " – par exemple si vous utilisez une requête fixe et liez les nouvelles valeurs avec des espaces réservés.
si vous faites généralement des mises à jour, je le ferais ..
- commencer une opération
- faire la mise à jour
- Vérifier le nombre de lignes
- s'il est 0, insérer
- Commit
Si vous sont généralement de faire des inserts, je
- commencer une opération
- , Essayez un encart
- vérification de l'erreur de violation de la clé primaire
- si nous avons une erreur faites la mise à jour
- Commit
de cette façon, vous évitez le select et vous êtes transactionnellement sain sur Sqlite.
je me rends compte que c'est un vieux fil, mais j'ai travaillé dans sqlite3 à partir de la fin et j'ai inventé cette méthode qui convenait mieux à mes besoins de générer dynamiquement des requêtes paramétrées:
insert or ignore into <table>(<primaryKey>, <column1>, <column2>, ...) values(<primaryKeyValue>, <value1>, <value2>, ...);
update <table> set <column1>=<value1>, <column2>=<value2>, ... where changes()=0 and <primaryKey>=<primaryKeyValue>;
c'est toujours 2 requêtes avec une clause où sur la mise à jour mais semble faire l'affaire. J'ai aussi cette vision dans ma tête que sqlite peut optimiser la mise à jour complètement si l'appel à changes() est supérieur à zéro. Si oui ou non il ne fait c'est au-delà de ma connaissance, mais un homme peut rêver n'est-ce pas? ;)
Pour des points bonus, vous pouvez ajouter cette ligne qui vous renvoie l'id de la ligne que ce soit une nouvelle ligne ou une ligne existante.
select case changes() WHEN 0 THEN last_insert_rowid() else <primaryKeyValue> end;
2018-05-18 STOP PRESS.
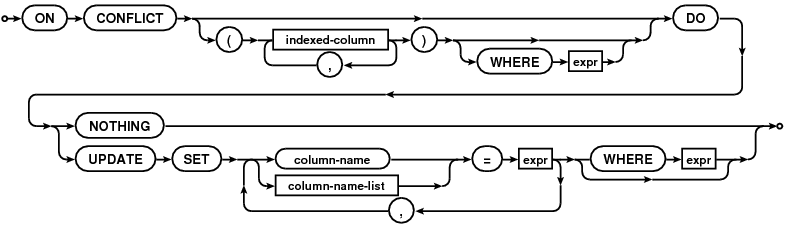
upsert support in SQLite! La syntaxe UPSERT a été ajoutée à SQLite avec la version 3.24.0 (en attente) !
UPSERT est un ajout de syntaxe spécial à INSERT qui fait que L'INSERT se comporte comme une mise à jour ou un no-op si L'INSERT violerait une contrainte d'unicité. UPSERT n'est pas un SQL standard. UPSERT en SQLite suit la syntaxe établie par PostgreSQL.
je sais que je suis en retard à la fête mais....
UPDATE employee SET role = 'code_monkey', name='fred' WHERE id = 1;
INSERT OR IGNORE INTO employee(id, role, name) values (1, 'code monkey', 'fred');
donc il essaie de mettre à jour, si l'enregistrement est là alors l'insert n'est pas action-ed.
alternativement:
une autre façon complètement différente de faire ceci est: dans mon application j'ai mis mon rowID en mémoire pour être long.MaxValue quand je crée la ligne en mémoire. (MaxValue ne sera jamais utilisé comme une ID vous ne vivrez pas assez longtemps.... Alors si rowID n'est pas cette valeur alors il doit déjà être dans la base de données donc nécessite une mise à jour si elle est MaxValue alors il a besoin d'un insert. Ceci n'est utile que si vous pouvez suivre les rowIDs dans votre application.
Voici une solution qui est en fait un UPSERT (UPDATE ou INSERT) au lieu d'un INSERT ou D'un REPLACE (qui fonctionne différemment dans de nombreuses situations).
il fonctionne comme ceci:
1. Essayez de mettre à jour si un enregistrement avec le même Id existe.
2. Si la mise à jour ne change aucune ligne ( NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0) ), alors insérez l'enregistrement.
Ainsi soit un enregistrement existant a été mis à jour ou un insert sera effectué.
le détail important est d'utiliser la fonction changes() SQL pour vérifier si l'instruction update a frappé des enregistrements existants et n'effectuer l'instruction insert que si elle n'a pas frappé d'enregistrement.
une chose à mentionner est que la fonction changes () ne renvoie pas les changements effectués par des déclencheurs de niveau inférieur (voir http://sqlite.org/lang_corefunc.html#changes ), il faut donc en tenir compte.
ici est SQL...
mise à jour du Test:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 2;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 2, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
, remplacer
par ."--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 3;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 3, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
extension sur réponse D'Aristote vous pouvez sélectionner à partir d'un mannequin table "singleton" (une table de votre propre création avec une seule rangée). Cela permet d'éviter certains doublons.
j'ai aussi gardé l'exemple portable à travers MySQL et SQLite et j'ai utilisé une colonne 'date_added' comme exemple de comment vous pouvez définir une colonne seulement la première fois.
REPLACE INTO page (
id,
name,
title,
content,
author,
date_added)
SELECT
old.id,
"about",
"About this site",
old.content,
42,
IFNULL(old.date_added,"21/05/2013")
FROM singleton
LEFT JOIN page AS old ON old.name = "about";
la meilleure approche que je connaisse est de faire une mise à jour, suivie d'un encart. Le "au-dessus d'un select" est nécessaire, mais ce n'est pas un fardeau terrible puisque vous cherchez sur la clé primaire, qui est rapide.
vous devriez être en mesure de modifier les énoncés ci-dessous avec vos noms de table et de champ pour faire ce que vous voulez.
--first, update any matches
UPDATE DESTINATION_TABLE DT
SET
MY_FIELD1 = (
SELECT MY_FIELD1
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
,MY_FIELD2 = (
SELECT MY_FIELD2
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
WHERE EXISTS(
SELECT ST2.PRIMARY_KEY
FROM
SOURCE_TABLE ST2
,DESTINATION_TABLE DT2
WHERE ST2.PRIMARY_KEY = DT2.PRIMARY_KEY
);
--second, insert any non-matches
INSERT INTO DESTINATION_TABLE(
MY_FIELD1
,MY_FIELD2
)
SELECT
ST.MY_FIELD1
,NULL AS MY_FIELD2 --insert NULL into this field
FROM
SOURCE_TABLE ST
WHERE NOT EXISTS(
SELECT DT2.PRIMARY_KEY
FROM DESTINATION_TABLE DT2
WHERE DT2.PRIMARY_KEY = ST.PRIMARY_KEY
);
si quelqu'un veut lire ma solution pour SQLite à Cordova, j'ai obtenu cette méthode js Générique grâce à @david réponse ci-dessus.
function addOrUpdateRecords(tableName, values, callback) {
get_columnNames(tableName, function (data) {
var columnNames = data;
myDb.transaction(function (transaction) {
var query_update = "";
var query_insert = "";
var update_string = "UPDATE " + tableName + " SET ";
var insert_string = "INSERT INTO " + tableName + " SELECT ";
myDb.transaction(function (transaction) {
// Data from the array [[data1, ... datan],[()],[()]...]:
$.each(values, function (index1, value1) {
var sel_str = "";
var upd_str = "";
var remoteid = "";
$.each(value1, function (index2, value2) {
if (index2 == 0) remoteid = value2;
upd_str = upd_str + columnNames[index2] + "='" + value2 + "', ";
sel_str = sel_str + "'" + value2 + "', ";
});
sel_str = sel_str.substr(0, sel_str.length - 2);
sel_str = sel_str + " WHERE NOT EXISTS(SELECT changes() AS change FROM "+tableName+" WHERE change <> 0);";
upd_str = upd_str.substr(0, upd_str.length - 2);
upd_str = upd_str + " WHERE remoteid = '" + remoteid + "';";
query_update = update_string + upd_str;
query_insert = insert_string + sel_str;
// Start transaction:
transaction.executeSql(query_update);
transaction.executeSql(query_insert);
});
}, function (error) {
callback("Error: " + error);
}, function () {
callback("Success");
});
});
});
}
Alors, d'abord ramasser les noms de colonne avec cette fonction:
function get_columnNames(tableName, callback) {
myDb.transaction(function (transaction) {
var query_exec = "SELECT name, sql FROM sqlite_master WHERE type='table' AND name ='" + tableName + "'";
transaction.executeSql(query_exec, [], function (tx, results) {
var columnParts = results.rows.item(0).sql.replace(/^[^\(]+\(([^\)]+)\)/g, '').split(','); ///// RegEx
var columnNames = [];
for (i in columnParts) {
if (typeof columnParts[i] === 'string')
columnNames.push(columnParts[i].split(" ")[0]);
};
callback(columnNames);
});
});
}
ensuite construire les transactions programmatically.
"Values" est un tableau que vous devez construire avant et il représente les lignes que vous voulez insérer ou mettre à jour dans le tableau.
"remoteid" est l'id que j'ai utilisé comme référence, puisque je suis synchronisé avec mon serveur distant.
pour l'utilisation du plugin SQLite Cordova, s'il vous plaît se référer à la Officielle lien
commençant par la version 3.24.0 UPSERT est supporté par SQLite.
De la documentation :
UPSERT est un ajout de syntaxe spécial à INSERT qui fait en sorte que L'INSERT se comporte comme une mise à jour ou un no-op si L'INSERT viole une contrainte d'unicité. UPSERT n'est pas un SQL standard. UPSERT en SQLite suit la syntaxe établie par PostgreSQL. La syntaxe UPSERT a été ajoutée SQLite avec la version 3.24.0 (en attente).
un UPSERT est un INSERT ordinaire qui est suivi de la clause spéciale sur le conflit
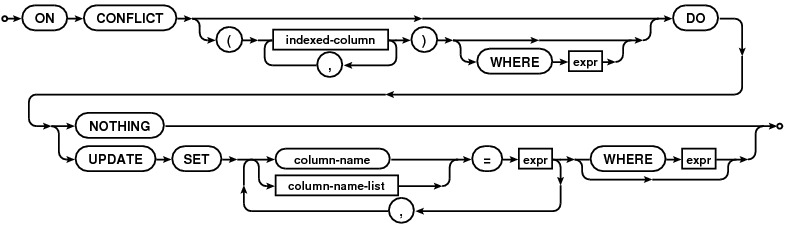
Image source: /images/content/418898/d59a3fced398fbcc6b856d6e32b9747e.gif
vous pouvez en effet faire un upsert en SQLite, il semble juste un peu différent que vous êtes habitués. Ça ressemblerait à quelque chose comme:
INSERT INTO table name (column1, column2)
VALUES ("value12", "value2") WHERE id = 123
ON CONFLICT DO UPDATE
SET column1 = "value1", column2 = "value2" WHERE id = 123
je pense que c'est peut-être ce que vous cherchez: sur la clause de conflit .
si vous définissez votre table comme ceci:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
field1 TEXT
);
maintenant, si vous faites un INSERT avec un id qui existe déjà, SQLite fait automatiquement une mise à jour au lieu d'INSERT.
Hth...
cette méthode corrige quelques-unes des autres méthodes de la réponse à cette question et incorpore l'utilisation de CTE (Common Table Expressions). Je vais vous présenter la requête puis expliquer pourquoi j'ai fait ce que j'ai fait.
j'aimerais changer le nom de famille de l'employé 300 en DAVIS s'il y a un employé 300. Sinon, je vais ajouter un nouvel employé.
nom de la Table: employees Colonnes: id, first_name ,last_name
La requête est:
INSERT OR REPLACE INTO employees (employee_id, first_name, last_name)
WITH registered_employees AS ( --CTE for checking if the row exists or not
SELECT --this is needed to ensure that the null row comes second
*
FROM (
SELECT --an existing row
*
FROM
employees
WHERE
employee_id = '300'
UNION
SELECT --a dummy row if the original cannot be found
NULL AS employee_id,
NULL AS first_name,
NULL AS last_name
)
ORDER BY
employee_id IS NULL --we want nulls to be last
LIMIT 1 --we only want one row from this statement
)
SELECT --this is where you provide defaults for what you would like to insert
registered_employees.employee_id, --if this is null the SQLite default will be used
COALESCE(registered_employees.first_name, 'SALLY'),
'DAVIS'
FROM
registered_employees
;
fondamentalement, j'ai utilisé le CTE pour réduire le nombre de fois où l'instruction select doit être utilisée pour déterminer les valeurs par défaut. Puisqu'il s'agit d'un CTE, nous sélectionnons simplement les colonnes que nous voulons à partir de la table et L'instruction INSERT utilise ceci.
maintenant vous pouvez décider quelles valeurs par défaut vous voulez utiliser en remplaçant les nulls, dans la fonction COALESCE avec ce que les valeurs devraient être.
suite à Aristotle Pagaltzis et l'idée de COALESCE de réponse D'Eric B , voici une option upsert pour mettre à jour seulement quelques colonnes ou insérer une rangée complète si elle n'existe pas.
dans ce cas, imaginez que le titre et le contenu doivent être mis à jour, en conservant les autres anciennes valeurs lorsqu'elles existent et en insérant celles qui sont fournies lorsque le nom n'est pas trouvé:
NOTE id est forcé D'être nul quand INSERT comme il est censé être auto-engagement. S'il s'agit simplement d'une clé primaire générée, alors COALESCE peut aussi être utilisé (voir Aristotle Pagaltzis comment ).
WITH new (id, name, title, content, author)
AS ( VALUES(100, 'about', 'About this site', 'Whatever new content here', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT
old.id, COALESCE(old.name, new.name),
new.title, new.content,
COALESCE(old.author, new.author)
FROM new LEFT JOIN page AS old ON new.name = old.name;
Ainsi, la règle générale serait, si vous voulez garder les anciennes valeurs, utilisez COALESCE , lorsque vous voulez mettre à jour les valeurs, utilisez new.fieldname
ayant juste lu ce fil et été déçu que ce n'était pas facile de se contenter de ce"UPSERT" ing, j'ai enquêté plus loin...
vous pouvez en fait le faire directement et facilement en SQLITE.
au lieu d'utiliser: INSERT INTO
utilisation: INSERT OR REPLACE INTO
C'est exactement ce que vous voulez faire!
SELECT COUNT(*) FROM table1 WHERE id = 1;
si COUNT(*) = 0
INSERT INTO table1(col1, col2, cole) VALUES(var1,var2,var3);
sinon si COUNT(*) > 0
UPDATE table1 SET col1 = var4, col2 = var5, col3 = var6 WHERE id = 1;