La vitesse d'insertion de SQLite ralentit à mesure que le nombre d'enregistrements augmente à cause d'un index
question originale
arrière-plan
il est bien connu que la SQLite doit être affinée pour atteindre des vitesses d'insertion de l'ordre de 50k inserts/s. Il y a ici de nombreuses questions concernant les vitesses d'insertion lentes et une foule de conseils et de points de référence.
Il ya aussi revendications que SQLite peut traiter de grandes quantités de données , avec des rapports de 50 + GB ne causant pas aucun problème avec les bons réglages.
j'ai suivi les conseils ici et d'ailleurs pour atteindre ces vitesses, et je suis heureux avec 35k-45k insertions/s. Le problème que j'ai c'est que tous les indices démontrent rapide insérer vitesses avec < 1m enregistrements. Ce que je vois, c'est que vitesse d'insertion semble être inversement proportionnelle à la taille de la table .
Problème
mon cas d'utilisation nécessite de stocker 500m à 1b tuples ( [x_id, y_id, z_id] ) sur quelques années (1m lignes / jour) dans un tableau de liens. Les valeurs sont toutes des ID entiers entre 1 et 2 000 000. Il n'y a qu'un seul index sur z_id .
Performance est très bonne pour la première 10m lignes, ~35k insertions/s, mais par le temps que la table a ~20m de lignes, les performances commencent à souffrir. Je vois maintenant environ 100 inserts / s.
La taille de la table n'est pas particulièrement grand. Avec des rangées de 20m, la taille sur le disque est d'environ 500MB.
le projet est écrit en Perl.
Question
est - ce la réalité des grandes tables en SQLite ou y a-t-il des secrets à maintenir taux d'insertion élevés pour les tables avec des rangées > 10m?
solutions de rechange connues que j'aimerais éviter si possible
- Supprimer l'index, ajouter les notices, et ré-indexer : C'est bien comme solution de contournement, mais ne fonctionne pas lorsque la base de données doit encore être utilisable pendant les mises à jour. Il ne fonctionnera pas de rendre la base de données complètement inaccessible pour x minutes / jour
- Casser la table dans le plus petit sous-tables / fichiers : Ce sera le travail à court terme, et j'ai déjà expérimenté. Le problème est que j'ai besoin d'être en mesure de récupérer des données de l'histoire entière en questionnant ce qui signifie que finalement Je vais atteindre la limite de 62 pièces jointes. Attacher, recueillir des résultats dans une table de température, et détacher des centaines de fois par demande semble être beaucoup de travail et de frais généraux, mais je vais essayer s'il n'y a pas d'autres solutions.
- Ensemble
SQLITE_FCNTL_CHUNK_SIZE: je ne sais pas C (?!), donc je préfère ne pas l'apprendre juste pour obtenir ce fait. Je ne vois pas comment paramétrer ce paramètre en utilisant Perl.
UPDATE
suivant la suggestion de Tim qu'un indice causait de plus en plus slow insert times malgré les prétentions de SQLite la manipulation de grands ensembles de données, j'ai effectué une comparaison avec les éléments suivants paramètres:
- lignes insérées: 14 millions
- commit lot size: 50 000 notices
-
cache_sizepragma: 10,000 -
page_sizepragma: 4,096 -
temp_storepragma: mémoire -
journal_modepragma: supprimer -
synchronouspragma: off
dans mon projet, comme dans les résultats de référence ci-dessous, une table temporaire basée sur le fichier est créée et le support intégré de SQLite
pour importer des données CSV est utilisé. Le tableau temporaire est alors joint
à la base de données de réception et les ensembles de 50.000 lignes sont insérés avec un
insert-select déclaration. Par conséquent, les temps d'insertion ne reflètent pas
fichier de base de données insérer fois, mais plutôt la table à la table insérer
vitesse. La prise en compte du temps D'importation CSV réduirait les vitesses
de 25 à 50% (une très forte estimation approximative, il ne faut pas longtemps pour importer les
Des données au format CSV).
ayant clairement un indice provoque le ralentissement dans la vitesse d'insertion que la taille de la table augmente.
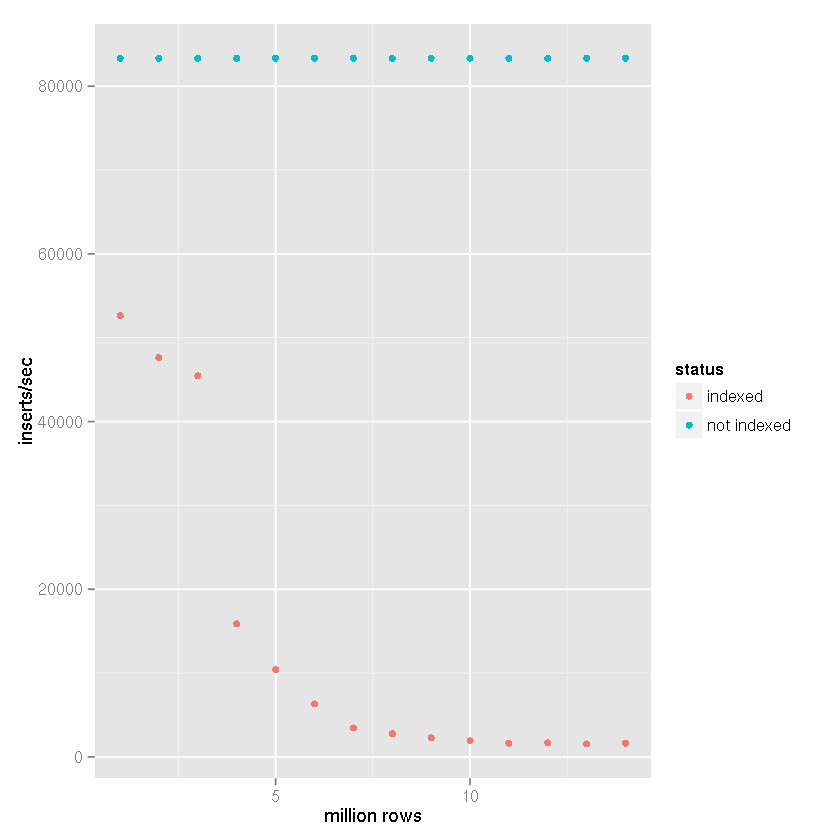
il est assez clair d'après les données ci-dessus que la bonne réponse peut être attribuée à la réponse de Tim plutôt que les affirmations que SQLite ne peut tout simplement pas le gérer. Clairement il peut poignée grands ensembles de données si indexation que l'ensemble de données ne fait pas partie de votre cas d'utilisation. J'utilise SQLite justement pour cela, comme backend pour un système de journalisation, depuis un certain temps maintenant qui ne pas ont besoin d'être indexés, donc j'ai été assez surpris par le ralentissement que j'ai connu.
Conclusion
si quelqu'un se trouve vouloir stocker une grande quantité de données en utilisant SQLite et avoir indexé, en utilisant des fragments peut être la réponse. J'ai finalement décidé d'utiliser les trois premiers caractères D'une colonne MD5 unique dans z pour déterminer l'affectation à l'une des 4 096 bases de données. Puisque mon cas d'utilisation est principalement de nature archivistique, le schéma ne changera pas et les requêtes n'auront jamais besoin de marcher en éclats. Il y a une limite à la taille de la base de données étant donné que les données extrêmement anciennes seront réduites et éventuellement écartées, de sorte que cette combinaison de les réglages, et même une certaine normalisation de me donne un bel équilibre qui, basé sur l'étalonnage ci-dessus, maintiendra une vitesse d'insertion d'au moins 10k inserts / seconde.
1 réponses
si votre exigence est de trouver un z_id particulier et les x_ids et y_ids qui lui sont liés (par opposition à la sélection rapide d'une gamme de z_ids), vous pouvez regarder dans un tableau de hachage non indexé db imbriqué qui vous permettrait de trouver instantanément votre chemin à un z_id particulier afin d'obtenir ses y_ids et x_ids -- sans la tête d'indexation et la performance dégradée concomitante pendant les inserts que l'indice se développe. Pour éviter les collisions de godets, choisissez une clé algorithme de hachage qui donne le plus de poids aux chiffres de z_id avec la plus grande variation (pondéré à droite).
P. S. une base de données qui utilise un arbre b peut apparaître d'abord plus rapidement qu'un db qui utilise le hachage linéaire, par exemple, mais la performance d'insertion restera au niveau du hachage linéaire que la performance sur l'arbre B commence à se dégrader.
P. P. S. pour répondre à la question de kawing-chiu: la caractéristique de base pertinente ici est qu'une telle base de données repose sur soi-disant "sparse" des tableaux dans lesquels l'emplacement physique d'un enregistrement est déterminée par un algorithme de hachage qui prend la clé d'enregistrement à l'entrée. Cette approche permet une recherche directement à l'emplacement du document dans le tableau sans l'intermédiaire d'un index . Comme il n'est pas nécessaire de parcourir les indices ou de rééquilibrer les indices, les temps d'insertion restent constants à mesure que la densité de la population augmente. Avec un arbre b, par contre, insert times se dégrade comme le l'arbre de référence pousse. Les applications OLTP avec un grand nombre d'inserts concurrents peuvent bénéficier d'une telle approche de table clairsemée. Les enregistrements sont dispersés dans le tableau. L'inconvénient des notices dispersées dans la" toundra " de la table clairsemée est que la collecte de grands ensembles de notices qui ont une valeur en commun, comme un code postal, peut être plus lente. L'approche hashed sparse-table est optimisée pour insérer et récupérer des enregistrements individuels, et pour récupérer réseaux d'enregistrements liés, pas de grands ensembles d'enregistrements qui ont une certaine valeur du champ en commun.
une base de données relationnelle imbriquée est une base de données qui permet tuples dans une colonne d'une rangée.