Performance SQL: choisir DISTINCT versus GROUP BY
j'ai essayé d'améliorer les temps de requête pour une application existante gérée par une base de données Oracle qui a été en cours d'exécution un peu léthargique. L'application exécute plusieurs grandes requêtes, comme celle ci-dessous, qui peuvent prendre plus d'une heure à exécuter. Le remplacement de l' DISTINCT avec un GROUP BY la clause dans la requête ci-dessous réduit le temps d'exécution de 100 minutes à 10 Secondes. Ma compréhension était que SELECT DISTINCT et GROUP BY exploité dans à peu près de la même façon. Pourquoi une telle disparité entre temps d'exécution? Quelle est la différence dans la façon dont la requête est exécutée à la fin? Est-il jamais une situation où SELECT DISTINCT court plus vite?
Remarque: Dans la requête suivante, WHERE TASK_INVENTORY_STEP.STEP_TYPE = 'TYPE A' ne représente qu'une des nombreuses façons dont les résultats peuvent être filtrés. Cet exemple a été fourni pour montrer le raisonnement pour joindre toutes les tables qui n'ont pas de colonnes incluses dans le SELECT et résulterait en environ un dixième de toutes les données disponibles
SQL à l'aide de DISTINCT:
SELECT DISTINCT
ITEMS.ITEM_ID,
ITEMS.ITEM_CODE,
ITEMS.ITEMTYPE,
ITEM_TRANSACTIONS.STATUS,
(SELECT COUNT(PKID)
FROM ITEM_PARENTS
WHERE PARENT_ITEM_ID = ITEMS.ITEM_ID
) AS CHILD_COUNT
FROM
ITEMS
INNER JOIN ITEM_TRANSACTIONS
ON ITEMS.ITEM_ID = ITEM_TRANSACTIONS.ITEM_ID
AND ITEM_TRANSACTIONS.FLAG = 1
LEFT OUTER JOIN ITEM_METADATA
ON ITEMS.ITEM_ID = ITEM_METADATA.ITEM_ID
LEFT OUTER JOIN JOB_INVENTORY
ON ITEMS.ITEM_ID = JOB_INVENTORY.ITEM_ID
LEFT OUTER JOIN JOB_TASK_INVENTORY
ON JOB_INVENTORY.JOB_ITEM_ID = JOB_TASK_INVENTORY.JOB_ITEM_ID
LEFT OUTER JOIN JOB_TASKS
ON JOB_TASK_INVENTORY.TASKID = JOB_TASKS.TASKID
LEFT OUTER JOIN JOBS
ON JOB_TASKS.JOB_ID = JOBS.JOB_ID
LEFT OUTER JOIN TASK_INVENTORY_STEP
ON JOB_INVENTORY.JOB_ITEM_ID = TASK_INVENTORY_STEP.JOB_ITEM_ID
LEFT OUTER JOIN TASK_STEP_INFORMATION
ON TASK_INVENTORY_STEP.JOB_ITEM_ID = TASK_STEP_INFORMATION.JOB_ITEM_ID
WHERE
TASK_INVENTORY_STEP.STEP_TYPE = 'TYPE A'
ORDER BY
ITEMS.ITEM_CODE
SQL à l'aide de GROUP BY:
SELECT
ITEMS.ITEM_ID,
ITEMS.ITEM_CODE,
ITEMS.ITEMTYPE,
ITEM_TRANSACTIONS.STATUS,
(SELECT COUNT(PKID)
FROM ITEM_PARENTS
WHERE PARENT_ITEM_ID = ITEMS.ITEM_ID
) AS CHILD_COUNT
FROM
ITEMS
INNER JOIN ITEM_TRANSACTIONS
ON ITEMS.ITEM_ID = ITEM_TRANSACTIONS.ITEM_ID
AND ITEM_TRANSACTIONS.FLAG = 1
LEFT OUTER JOIN ITEM_METADATA
ON ITEMS.ITEM_ID = ITEM_METADATA.ITEM_ID
LEFT OUTER JOIN JOB_INVENTORY
ON ITEMS.ITEM_ID = JOB_INVENTORY.ITEM_ID
LEFT OUTER JOIN JOB_TASK_INVENTORY
ON JOB_INVENTORY.JOB_ITEM_ID = JOB_TASK_INVENTORY.JOB_ITEM_ID
LEFT OUTER JOIN JOB_TASKS
ON JOB_TASK_INVENTORY.TASKID = JOB_TASKS.TASKID
LEFT OUTER JOIN JOBS
ON JOB_TASKS.JOB_ID = JOBS.JOB_ID
LEFT OUTER JOIN TASK_INVENTORY_STEP
ON JOB_INVENTORY.JOB_ITEM_ID = TASK_INVENTORY_STEP.JOB_ITEM_ID
LEFT OUTER JOIN TASK_STEP_INFORMATION
ON TASK_INVENTORY_STEP.JOB_ITEM_ID = TASK_STEP_INFORMATION.JOB_ITEM_ID
WHERE
TASK_INVENTORY_STEP.STEP_TYPE = 'TYPE A'
GROUP BY
ITEMS.ITEM_ID,
ITEMS.ITEM_CODE,
ITEMS.ITEMTYPE,
ITEM_TRANSACTIONS.STATUS
ORDER BY
ITEMS.ITEM_CODE
voici le plan de requête Oracle pour la requête en utilisant DISTINCT:
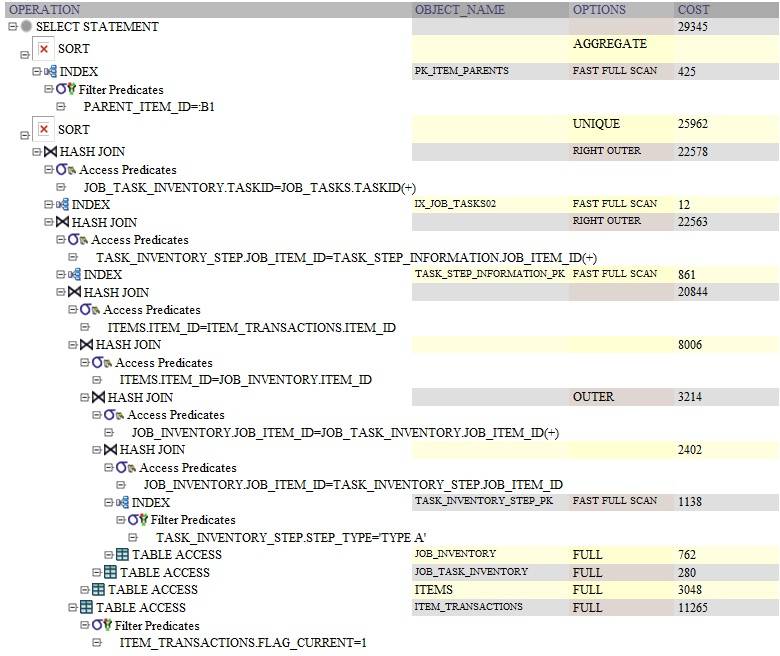
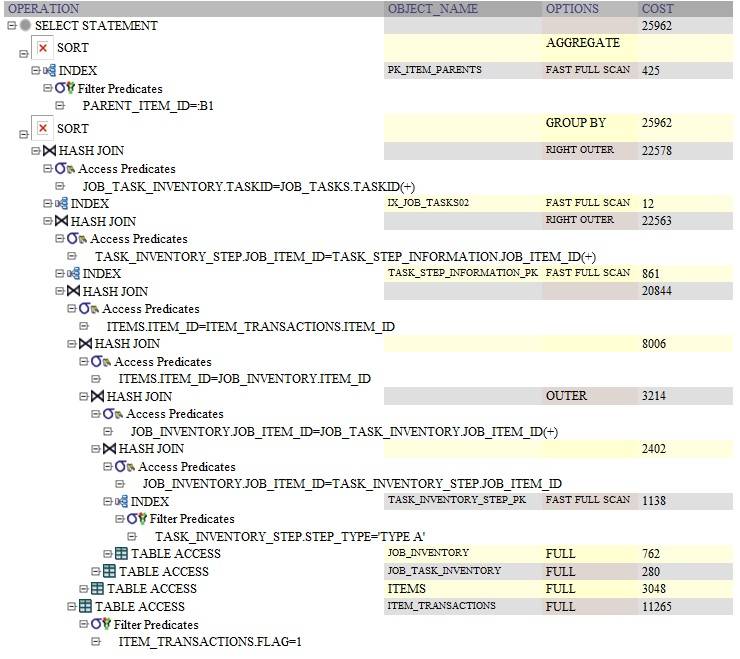
voici le plan de requête Oracle pour la requête en utilisant GROUP BY:
4 réponses
la différence de performance est probablement due à l'exécution du sous-jeu dans le SELECT l'article. Je devine qu'il est en train de ré-exécuter cette requête pour chaque ligne avant l'distinctes. Pour l' group by, il exécute une fois après le groupe de par.
essayez de le remplacer par une jointure, à la place:
select . . .,
parentcnt
from . . . left outer join
(SELECT PARENT_ITEM_ID, COUNT(PKID) as parentcnt
FROM ITEM_PARENTS
) p
on items.item_id = p.parent_item_id
je suis assez sûr que GROUP BY et DISTINCT ont à peu près le même plan d'exécution.
la différence ici puisque nous devons deviner (puisque nous n'avons pas les plans d'explication) est IMO que le sous-jeu en ligne est exécuté aprèsGROUP BY mais avantDISTINCT.
donc si votre requête retourne des lignes 1M et est agrégée à des lignes 1k:
GROUP BYla requête aurait exécuté le sous-jeu 1000 fois,- alors que le
DISTINCTla requête aurait exécuté le sous-jeu 1000000 fois.
le plan d'explication de tkprof permettrait de démontrer cette hypothèse.
pendant que nous discutons de cela, je pense qu'il est important de noter que la façon dont la requête est écrite est trompeuse à la fois pour le lecteur et pour l'optimiseur: vous voulez évidemment trouver toutes les lignes de item / item_transactions qui ont un TASK_INVENTORY_STEP.STEP_TYPE avec une valeur de "TYPE A".
IMO votre requête aurait un meilleur plan et serait plus facilement lisible si écrit comme ceci:
SELECT ITEMS.ITEM_ID,
ITEMS.ITEM_CODE,
ITEMS.ITEMTYPE,
ITEM_TRANSACTIONS.STATUS,
(SELECT COUNT(PKID)
FROM ITEM_PARENTS
WHERE PARENT_ITEM_ID = ITEMS.ITEM_ID) AS CHILD_COUNT
FROM ITEMS
JOIN ITEM_TRANSACTIONS
ON ITEMS.ITEM_ID = ITEM_TRANSACTIONS.ITEM_ID
AND ITEM_TRANSACTIONS.FLAG = 1
WHERE EXISTS (SELECT NULL
FROM JOB_INVENTORY
JOIN TASK_INVENTORY_STEP
ON JOB_INVENTORY.JOB_ITEM_ID=TASK_INVENTORY_STEP.JOB_ITEM_ID
WHERE TASK_INVENTORY_STEP.STEP_TYPE = 'TYPE A'
AND ITEMS.ITEM_ID = JOB_INVENTORY.ITEM_ID)
dans de nombreux cas, un DISTINCT peut être un signe que la requête n'est pas écrite correctement (parce qu'une bonne requête ne devrait pas retourner les doublons).
Notez aussi que 4 tableaux ne sont pas utilisés dans votre select original.
la première chose à noter est l'utilisation de Distinct indique une odeur de code, alias anti-pattern. Cela signifie généralement qu'il y a une jointure manquante ou une jointure supplémentaire qui génère des données dupliquées. En regardant votre requête ci-dessus, je devine que la raison pourquoi group by est plus rapide( sans voir la requête), est que l'emplacement du group by réduit le nombre d'enregistrements qui finissent par être renvoyé. Alors que les distinct est soufflant sur le jeu de résultats et faisant ligne par ligne comparaison.
mise à Jour à l'approche de
Désolé, j'aurais dû être plus clair. Les enregistrements sont générés lorsque les utilisateurs exécutent certaines tâches dans le système, il n'y a donc pas de calendrier. Un l'utilisateur peut générer un seul enregistrement en une journée ou des centaines par heure. Le ce qui est important, c'est que chaque fois qu'un utilisateur lance une recherche, il est à jour. les dossiers doivent être retournés, ce qui me fait douter qu'une la vue fonctionnerait ici, surtout si la requête le remplissage il faudrait de temps à s'exécuter.
je crois que c'est l'exacte raison de l'utilisation d'une vue matérialisée. Donc le processus fonctionnerait de cette façon. Vous prenez la longue requête en cours d'exécution comme la pièce qui construit votre vue matérialisée, puisque nous savons que l'utilisateur se soucie seulement de "nouvelles" données après qu'ils accomplissent quelque tâche arbitraire dans le système. Donc, ce que vous voulez faire est d'interroger cette vue matérialisée de base, qui peut être rafraîchie en permanence sur la fin, la persistance la stratégie ne doit pas étouffer la vision matérialisée (la persistance de quelques centaines de disques à la fois ne détruira rien). Ce que cela permettra est Oracle pour saisir un verrou de lecture (notez que nous ne nous soucions pas combien de sources lisent nos données, nous ne nous soucions que des rédacteurs). Dans le pire des cas, un utilisateur aura des données "périmées" pour des microsecondes, donc à moins qu'il s'agisse d'un système de trading financier sur Wall Street ou d'un système pour un réacteur nucléaire, ces "blips" devraient passer inaperçus même par les utilisateurs les plus optimistes.
exemple de Code de la façon de faire ceci:
create materialized view dept_mv FOR UPDATE as select * from dept;
maintenant la clé pour cela est aussi longtemps que vous n'invoquez pas refresh vous ne perdrez aucune des données persistened. Ce sera à vous de déterminer quand vous voulez "ligne de base" de votre vue matérialisée à nouveau (minuit, peut-être?)
vous devez utiliser GROUP BY pour appliquer les opérateurs aggregate à chaque groupe et DISTINCT si vous n'avez besoin de supprimer que les doublons.
je pense que la performance est la même.
dans votre cas, je pense que vous devriez utiliser GROUP BY.