Accélérer des millions de remplacements regex en Python 3
j'utilise Python 3.5.2
j'ai deux listes
- une liste d'environ 750 000 "phrases" (longues chaînes)
- une liste d'environ 20 000 "mots" que je voudrais supprimer de mes 750 000 phrases
ainsi, je dois boucler à travers 750.000 phrases et effectuer environ 20.000 remplacements, mais seulement si mes mots sont réellement des "mots" et ne font pas partie d'un plus grand chaîne de caractères.
je le fais par pré-compilation mes mots pour qu'ils soient flanqués par le b metacharacter
compiled_words = [re.compile(r'b' + word + r'b') for word in my20000words]
puis je boucle à travers mes "phrases
import re
for sentence in sentences:
for word in compiled_words:
sentence = re.sub(word, "", sentence)
# put sentence into a growing list
cette boucle emboîtée traite environ 50 phrases par seconde , ce qui est agréable, mais il faut encore plusieurs heures pour traiter toutes mes phrases.
-
y a-t-il un moyen d'utiliser la méthode
str.replace(qui, je crois, est plus rapide), mais qui exige tout de même que les remplacements ne se produisent qu'à des limites de mots ? -
alternativement, y a-t-il un moyen d'accélérer la méthode
re.sub? J'ai déjà amélioré la vitesse légèrement en sautant surre.subsi la longueur de ma parole est > que la longueur de ma phrase, mais il n'est pas beaucoup de amélioration.
Merci pour toutes les suggestions.
9 réponses
une chose que vous pouvez essayer est de compiler un modèle unique comme "\b(word1|word2|word3)\b" .
comme re utilise le code C pour effectuer l'appariement, les économies peuvent être considérables.
@pvg souligné dans les commentaires, il bénéficie également d'une seule passe correspondant.
si vos mots ne sont pas regex, la réponse D'Eric est plus rapide.
TLDR
utilisez cette méthode (avec la recherche définie) si vous voulez la solution la plus rapide. Pour un ensemble de données similaire à celui de L'OP, c'est environ 2000 fois plus rapide que la réponse acceptée.
si vous insistez pour utiliser un regex pour la recherche, utilisez cette version basée sur trie , qui est encore 1000 fois plus rapide qu'une union regex.
théorie
si vos phrases ne sont pas humongous les cordes, il est probablement possible de traiter beaucoup plus de 50 par seconde.
si vous sauvegardez tous les mots bannis dans un ensemble, il sera très rapide de vérifier si un autre mot est inclus dans cet ensemble.
Pack la logique dans une fonction, de donner à cette fonction comme argument re.sub et vous avez terminé!
Code
import re
with open('/usr/share/dict/american-english') as wordbook:
banned_words = set(word.strip().lower() for word in wordbook)
def delete_banned_words(matchobj):
word = matchobj.group(0)
if word.lower() in banned_words:
return ""
else:
return word
sentences = ["I'm eric. Welcome here!", "Another boring sentence.",
"GiraffeElephantBoat", "sfgsdg sdwerha aswertwe"] * 250000
word_pattern = re.compile('\w+')
for sentence in sentences:
sentence = word_pattern.sub(delete_banned_words, sentence)
les phrases converties sont:
' . !
.
GiraffeElephantBoat
sfgsdg sdwerha aswertwe
Note que:
- la recherche n'est pas sensible à la casse (grâce à
lower()) - remplacer un mot par
""pourrait laisser deux espaces (comme dans votre code) - avec python3,
\w+correspond aussi aux caractères accentués (par exemple"ångström"). - tout caractère non-word (tab, espace, newline, marks,...) restera intacte.
Performance
il y a un million de phrases, banned_words a presque 100000 mots et le script fonctionne en moins de 7s.
en comparaison, Liteye's answer avait besoin de 160s pour 10 mille phrases.
avec n étant le nombre total de mots et m le nombre de mots interdits, OP's et Liteye's code sont O(n*m) .
en comparaison, mon code devrait être O(n+m) . Étant donné qu'il y a beaucoup plus de phrases que de mots interdits, l'algorithme devient O(n) .
Regex union test
Quelle est la complexité d'une recherche regex avec un motif '\b(word1|word2|...|wordN)\b' ? Est-ce O(N) ou O(1) ?
il est assez difficile de comprendre la façon dont le moteur regex fonctionne, alors écrivons un test simple.
ce code extrait 10**i des mots anglais aléatoires dans un liste. Elle crée l'union regex correspondante, et la teste avec des mots différents :
- un n'est clairement pas un mot (il commence par
#) - est le premier mot dans la liste
- est le dernier mot dans la liste
- on ressemble à un mot, mais n'est pas
import re
import timeit
import random
with open('/usr/share/dict/american-english') as wordbook:
english_words = [word.strip().lower() for word in wordbook]
random.shuffle(english_words)
print("First 10 words :")
print(english_words[:10])
test_words = [
("Surely not a word", "#surely_NöTäWORD_so_regex_engine_can_return_fast"),
("First word", english_words[0]),
("Last word", english_words[-1]),
("Almost a word", "couldbeaword")
]
def find(word):
def fun():
return union.match(word)
return fun
for exp in range(1, 6):
print("\nUnion of %d words" % 10**exp)
union = re.compile(r"\b(%s)\b" % '|'.join(english_words[:10**exp]))
for description, test_word in test_words:
time = timeit.timeit(find(test_word), number=1000) * 1000
print(" %-17s : %.1fms" % (description, time))
sorties informatiques:
First 10 words :
["geritol's", "sunstroke's", 'fib', 'fergus', 'charms', 'canning', 'supervisor', 'fallaciously', "heritage's", 'pastime']
Union of 10 words
Surely not a word : 0.7ms
First word : 0.8ms
Last word : 0.7ms
Almost a word : 0.7ms
Union of 100 words
Surely not a word : 0.7ms
First word : 1.1ms
Last word : 1.2ms
Almost a word : 1.2ms
Union of 1000 words
Surely not a word : 0.7ms
First word : 0.8ms
Last word : 9.6ms
Almost a word : 10.1ms
Union of 10000 words
Surely not a word : 1.4ms
First word : 1.8ms
Last word : 96.3ms
Almost a word : 116.6ms
Union of 100000 words
Surely not a word : 0.7ms
First word : 0.8ms
Last word : 1227.1ms
Almost a word : 1404.1ms
il ressemble donc à la recherche d'un seul mot avec un '\b(word1|word2|...|wordN)\b' modèle a:
-
O(1)meilleur des cas -
O(n/2)cas moyen, qui est toujoursO(n) -
O(n)pire des cas
ces résultats concordent avec une simple recherche en boucle.
une alternative beaucoup plus rapide à un regex union est de créer le modèle regex à partir d'un .
TLDR
utilisez cette méthode si vous voulez la solution basée sur regex la plus rapide. Pour un ensemble de données similaire à celui de L'OP, c'est environ 1000 fois plus rapide que la réponse acceptée.
si vous ne vous souciez pas de regex, utilisez cette version , qui est 2000 fois plus rapide qu'une union regex.
Optimisé Regex avec Trie
A simple Regex union approche devient lente avec de nombreux mots interdits, parce que le moteur regex ne fait pas un très bon travail de l'optimisation du modèle.
il est possible de créer un Trie avec tous les mots interdits et écrire le regex correspondant. Le tri ou le regex qui en résulte ne sont pas vraiment lisibles par les humains, mais ils permettent une recherche et une correspondance très rapide.
exemple
['foobar', 'foobah', 'fooxar', 'foozap', 'fooza']
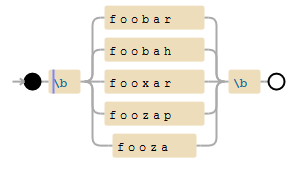
la liste est convertie en un tri:
{'f': {'o': {'o': {'x': {'a': {'r': {'': 1}}}, 'b': {'a': {'r': {'': 1}, 'h': {'': 1}}}, 'z': {'a': {'': 1, 'p': {'': 1}}}}}}}
et puis à ce motif regex:
r"\bfoo(?:ba[hr]|xar|zap?)\b"
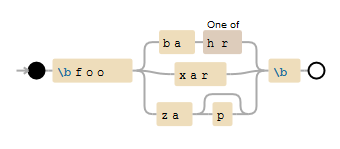
l'énorme avantage est que pour tester si zoo correspond, le moteur de regex seulement a besoin de comparer le premier caractère (il ne match), au lieu de en essayant les 5 mots . Il s'agit d'une préprocession excessive pour 5 mots, mais il montre des résultats prometteurs pour plusieurs milliers de mots.
noter que (?:) les groupes non capturables sont utilisés parce que:
-
foobar|bazcorrespondrait àfoobaroubaz, mais pasfoobaz -
foo(bar|baz)économiserait informations inutiles à un capture d'un groupe .
Code
Voici une bibliothèque légèrement modifiée gist , que nous pouvons utiliser comme une trie.py bibliothèque:
import re
class Trie():
"""Regex::Trie in Python. Creates a Trie out of a list of words. The trie can be exported to a Regex pattern.
The corresponding Regex should match much faster than a simple Regex union."""
def __init__(self):
self.data = {}
def add(self, word):
ref = self.data
for char in word:
ref[char] = char in ref and ref[char] or {}
ref = ref[char]
ref[''] = 1
def dump(self):
return self.data
def quote(self, char):
return re.escape(char)
def _pattern(self, pData):
data = pData
if "" in data and len(data.keys()) == 1:
return None
alt = []
cc = []
q = 0
for char in sorted(data.keys()):
if isinstance(data[char], dict):
try:
recurse = self._pattern(data[char])
alt.append(self.quote(char) + recurse)
except:
cc.append(self.quote(char))
else:
q = 1
cconly = not len(alt) > 0
if len(cc) > 0:
if len(cc) == 1:
alt.append(cc[0])
else:
alt.append('[' + ''.join(cc) + ']')
if len(alt) == 1:
result = alt[0]
else:
result = "(?:" + "|".join(alt) + ")"
if q:
if cconly:
result += "?"
else:
result = "(?:%s)?" % result
return result
def pattern(self):
return self._pattern(self.dump())
Test
voici un petit test (le même que celui-ci ):
# Encoding: utf-8
import re
import timeit
import random
from trie import Trie
with open('/usr/share/dict/american-english') as wordbook:
banned_words = [word.strip().lower() for word in wordbook]
random.shuffle(banned_words)
test_words = [
("Surely not a word", "#surely_NöTäWORD_so_regex_engine_can_return_fast"),
("First word", banned_words[0]),
("Last word", banned_words[-1]),
("Almost a word", "couldbeaword")
]
def trie_regex_from_words(words):
trie = Trie()
for word in words:
trie.add(word)
return re.compile(r"\b" + trie.pattern() + r"\b", re.IGNORECASE)
def find(word):
def fun():
return union.match(word)
return fun
for exp in range(1, 6):
print("\nTrieRegex of %d words" % 10**exp)
union = trie_regex_from_words(banned_words[:10**exp])
for description, test_word in test_words:
time = timeit.timeit(find(test_word), number=1000) * 1000
print(" %s : %.1fms" % (description, time))
C'sorties:
TrieRegex of 10 words
Surely not a word : 0.3ms
First word : 0.4ms
Last word : 0.5ms
Almost a word : 0.5ms
TrieRegex of 100 words
Surely not a word : 0.3ms
First word : 0.5ms
Last word : 0.9ms
Almost a word : 0.6ms
TrieRegex of 1000 words
Surely not a word : 0.3ms
First word : 0.7ms
Last word : 0.9ms
Almost a word : 1.1ms
TrieRegex of 10000 words
Surely not a word : 0.1ms
First word : 1.0ms
Last word : 1.2ms
Almost a word : 1.2ms
TrieRegex of 100000 words
Surely not a word : 0.3ms
First word : 1.2ms
Last word : 0.9ms
Almost a word : 1.6ms
pour info, le regex commence comme ceci:
c'est vraiment illisible, mais pour une liste de 100000 mots interdits, ce Trie regex est 1000 fois plus rapide qu'une simple union regex!
voici un diagramme du tri complet, exporté avec trie-python-graphviz et graphviz twopi :

une chose que vous pourriez vouloir essayer est de pré-traiter les phrases pour coder les limites du mot. Essentiellement transformer chaque phrase en une liste de mots en se divisant sur les limites de mots.
cela devrait être plus rapide, parce que pour traiter une phrase, vous devez juste passer à travers chacun des mots et vérifier si c'est une correspondance.
actuellement, la recherche regex doit passer par la chaîne entière à chaque fois, à la recherche de limites de mots, et puis "écarter" le résultat de ce travail avant le prochain passage.
Eh bien, voici une solution rapide et facile, avec jeu d'essai.
stratégie gagnante:
re.sub ("\w+", repl,phrase) recherche les mots.
"repl" peut être un appelable. J'ai utilisé une fonction qui effectue un dict de recherche, et le dict contient les mots à rechercher et remplacer.
il s'agit de la solution la plus simple et la plus rapide (Voir la fonction remplaçe4 dans l'exemple de code ci-dessous).
Second best
l'idée est de diviser les phrases en mots, en utilisant re.split, tout en conservant les séparateurs pour reconstruire les phrases plus tard. Ensuite, les remplacements se font avec une simple recherche de dict.
(voir la fonction remplaçe3 dans l'exemple de code ci-dessous).
Timings par exemple des fonctions:
replace1: 0.62 sentences/s
replace2: 7.43 sentences/s
replace3: 48498.03 sentences/s
replace4: 61374.97 sentences/s (...and 240.000/s with PyPy)
...et code:
#! /bin/env python3
# -*- coding: utf-8
import time, random, re
def replace1( sentences ):
for n, sentence in enumerate( sentences ):
for search, repl in patterns:
sentence = re.sub( "\b"+search+"\b", repl, sentence )
def replace2( sentences ):
for n, sentence in enumerate( sentences ):
for search, repl in patterns_comp:
sentence = re.sub( search, repl, sentence )
def replace3( sentences ):
pd = patterns_dict.get
for n, sentence in enumerate( sentences ):
#~ print( n, sentence )
# Split the sentence on non-word characters.
# Note: () in split patterns ensure the non-word characters ARE kept
# and returned in the result list, so we don't mangle the sentence.
# If ALL separators are spaces, use string.split instead or something.
# Example:
#~ >>> re.split(r"([^\w]+)", "ab céé? . d2eéf")
#~ ['ab', ' ', 'céé', '? . ', 'd2eéf']
words = re.split(r"([^\w]+)", sentence)
# and... done.
sentence = "".join( pd(w,w) for w in words )
#~ print( n, sentence )
def replace4( sentences ):
pd = patterns_dict.get
def repl(m):
w = m.group()
return pd(w,w)
for n, sentence in enumerate( sentences ):
sentence = re.sub(r"\w+", repl, sentence)
# Build test set
test_words = [ ("word%d" % _) for _ in range(50000) ]
test_sentences = [ " ".join( random.sample( test_words, 10 )) for _ in range(1000) ]
# Create search and replace patterns
patterns = [ (("word%d" % _), ("repl%d" % _)) for _ in range(20000) ]
patterns_dict = dict( patterns )
patterns_comp = [ (re.compile("\b"+search+"\b"), repl) for search, repl in patterns ]
def test( func, num ):
t = time.time()
func( test_sentences[:num] )
print( "%30s: %.02f sentences/s" % (func.__name__, num/(time.time()-t)))
print( "Sentences", len(test_sentences) )
print( "Words ", len(test_words) )
test( replace1, 1 )
test( replace2, 10 )
test( replace3, 1000 )
test( replace4, 1000 )
peut-être que Python n'est pas le bon outil ici. En voici un avec la chaîne Unix
sed G file |
tr ' ' '\n' |
grep -vf blacklist |
awk -v RS= -v OFS=' ' '{=}1'
en supposant que votre fichier de liste noire est pré-traité avec les limites de mot ajoutées. Les étapes sont les suivantes: convertir le fichier en double interligne, diviser chaque phrase en un mot par ligne, mass supprimer les mots de la liste noire du fichier, et fusionner en arrière les lignes.
cela devrait être au moins un ordre de grandeur plus rapide.
pour prétraitement du fichier de la liste noire à partir de mots (un mot par ligne)
sed 's/.*/\b&\b/' words > blacklist
Que pensez-vous de ceci:
#!/usr/bin/env python3
from __future__ import unicode_literals, print_function
import re
import time
import io
def replace_sentences_1(sentences, banned_words):
# faster on CPython, but does not use \b as the word separator
# so result is slightly different than replace_sentences_2()
def filter_sentence(sentence):
words = WORD_SPLITTER.split(sentence)
words_iter = iter(words)
for word in words_iter:
norm_word = word.lower()
if norm_word not in banned_words:
yield word
yield next(words_iter) # yield the word separator
WORD_SPLITTER = re.compile(r'(\W+)')
banned_words = set(banned_words)
for sentence in sentences:
yield ''.join(filter_sentence(sentence))
def replace_sentences_2(sentences, banned_words):
# slower on CPython, uses \b as separator
def filter_sentence(sentence):
boundaries = WORD_BOUNDARY.finditer(sentence)
current_boundary = 0
while True:
last_word_boundary, current_boundary = current_boundary, next(boundaries).start()
yield sentence[last_word_boundary:current_boundary] # yield the separators
last_word_boundary, current_boundary = current_boundary, next(boundaries).start()
word = sentence[last_word_boundary:current_boundary]
norm_word = word.lower()
if norm_word not in banned_words:
yield word
WORD_BOUNDARY = re.compile(r'\b')
banned_words = set(banned_words)
for sentence in sentences:
yield ''.join(filter_sentence(sentence))
corpus = io.open('corpus2.txt').read()
banned_words = [l.lower() for l in open('banned_words.txt').read().splitlines()]
sentences = corpus.split('. ')
output = io.open('output.txt', 'wb')
print('number of sentences:', len(sentences))
start = time.time()
for sentence in replace_sentences_1(sentences, banned_words):
output.write(sentence.encode('utf-8'))
output.write(b' .')
print('time:', time.time() - start)
ces solutions se divisent sur les limites de mots et regarde chaque mot dans un ensemble. Ils devraient être plus rapides que les ré.sub of word alternates (Liteyes' solution) car ces solutions sont O(n) où n est la taille de l'entrée en raison de la recherche amortized O(1) mis en place, tandis que l'utilisation d'alternats regex entraînerait le moteur de regex pour avoir à vérifier les correspondances de mot sur chaque caractère plutôt que juste sur les limites de mot. Mon solutiona prendre attention supplémentaire pour préserver les espaces blancs qui ont été utilisés dans le texte original (i.e. il ne compresse pas les espaces blancs et préserve les onglets, les nouvelles lignes, et d'autres caractères d'espace), mais si vous décidez que vous ne vous souciez pas de lui, il devrait être assez simple de les supprimer de la sortie.
j'ai testé sur corpus.txt, qui est une concaténation de plusieurs eBooks téléchargés à partir du Projet Gutenberg, et banned_words.txt est 20000 mots choisis au hasard dans Ubuntu liste de mots (/usr/share/dict/américain-anglais). Il faut environ 30 secondes pour traiter 862462 phrases (dont la moitié sur PyPy). J'ai défini les phrases comme n'importe quoi séparé par ". ".
$ # replace_sentences_1()
$ python3 filter_words.py
number of sentences: 862462
time: 24.46173644065857
$ pypy filter_words.py
number of sentences: 862462
time: 15.9370770454
$ # replace_sentences_2()
$ python3 filter_words.py
number of sentences: 862462
time: 40.2742919921875
$ pypy filter_words.py
number of sentences: 862462
time: 13.1190629005
PyPy bénéficient particulièrement plus de la deuxième approche, tandis que CPython s'en est mieux tiré lors de la première approche. Le code ci-dessus devrait fonctionner sur Python 2 et 3.
approche pratique
une solution décrite ci-dessous utilise beaucoup de mémoire pour stocker tout le texte à la même chaîne et pour réduire le niveau de complexité. Si la mémoire vive est un problème, pensez-y à deux fois avant de l'utiliser.
avec join / split astuces vous pouvez éviter les boucles à tous ce qui devrait accélérer l'algorithme.
merged_sentences = ' * '.join(sentences)
| " ou "déclaration regex: regex = re.compile(r'\b({})\b'.format('|'.join(words)), re.I) # re.I is a case insensitive flag
clean_sentences = re.sub(regex, "", merged_sentences).split(' * ')
Performance
"".join la complexité est O (n). C'est assez intuitif mais de toute façon il y a une citation abrégée d'une source:
for (i = 0; i < seqlen; i++) {
[...]
sz += PyUnicode_GET_LENGTH(item);
donc avec join/split vous avez O(mots) + 2*O(phrases) qui est encore complexité linéaire vs 2*O(N 2 ) avec l'approche initiale.
B. T. w. n'utilisez pas le multithreading. GIL va bloquer chaque opération parce que votre tâche est strictement lié CPU donc GIL n'ont aucune chance d'être libéré, mais chaque fil enverra des tiques en même temps qui causent un effort supplémentaire et même conduire l'opération à l'infini.
concaténez toutes vos phrases en un seul document. Utilisez n'importe quelle implémentation de L'algorithme Aho-Corasick ( en voici une ) pour localiser tous vos "mauvais" mots. Parcourir le fichier, remplacer chaque mauvais mot, mettre à jour les offsets des mots trouvés qui suivent, etc.