Une explication Simple de MapReduce?
8 réponses
qui Va tout le chemin vers les bases de la Map et reduce.
carte est une fonction qui" transforme " des articles dans une sorte de liste à un autre type d'article et les remettre dans le même type de liste.
supposons que j'ai une liste de nombres: [1,2,3] et je veux doubler chaque numéro, dans ce cas, la fonction de "double chaque nombre" est la fonction x = x * 2. Et sans mappages, je pourrais écrivez une boucle simple, dites
A = [1, 2, 3]
foreach (item in A) A[item] = A[item] * 2
et j'aurais A = [2, 4, 6] mais au lieu d'écrire des boucles, si j'ai une fonction de carte je pourrais écrire
A = [1, 2, 3].Map(x => x * 2)
le x => x * 2 est une fonction qui doit être exécutée contre les éléments dans [1,2,3]. Ce qui se passe est que le programme prend chaque élément, exécute (x => x * 2) contre lui en faisant x égale à chaque élément, et produit une liste des résultats.
1 : 1 => 1 * 2 : 2
2 : 2 => 2 * 2 : 4
3 : 3 => 3 * 2 : 6
donc après exécution la fonction map avec (x => x * 2) vous avez [2, 4, 6].
Reduce est une fonction qui" recueille "les articles dans les listes et effectuer un certain calcul sur tous d'entre eux, les réduisant ainsi à une seule valeur.
trouver une somme ou trouver des moyennes sont tous les cas d'une fonction de réduction. Comme si vous aviez une liste de nombres, disons [7, 8, 9] et que vous vouliez les résumer, vous auriez écrivez une boucle comme celle-ci
A = [7, 8, 9]
sum = 0
foreach (item in A) sum = sum + A[item]
Mais, si vous avez accès à une fonction de réduction, vous pouvez l'écrire comme ceci
A = [7, 8, 9]
sum = A.reduce( 0, (x, y) => x + y )
maintenant c'est un peu confus pourquoi il y a 2 arguments (0 et la fonction avec x et y) passés. Pour qu'une fonction de réduction soit utile, elle doit pouvoir prendre 2 éléments, calculer quelque chose et "réduire" ces 2 éléments à une seule valeur, ainsi le programme pourrait réduire chaque paire jusqu'à ce que nous ayons une seule valeur.
l'exécution serait la suivante:
result = 0
7 : result = result + 7 = 0 + 7 = 7
8 : result = result + 8 = 7 + 8 = 15
9 : result = result + 9 = 15 + 9 = 24
mais vous ne voulez pas commencer avec des zéros tout le temps, donc le premier argument est là pour vous permettre de spécifier une valeur de graine spécifiquement la valeur dans la première ligne result = .
dites que vous voulez additionner 2 listes, il pourrait ressembler à ceci:
A = [7, 8, 9]
B = [1, 2, 3]
sum = 0
sum = A.reduce( sum, (x, y) => x + y )
sum = B.reduce( sum, (x, y) => x + y )
ou une version que vous auriez plus de chances de trouver dans le monde réel:
A = [7, 8, 9]
B = [1, 2, 3]
sum_func = (x, y) => x + y
sum = A.reduce( B.reduce( 0, sum_func ), sum_func )
C'est une bonne chose dans un logiciel DB car, avec Map\Reduce support, vous pouvez travailler avec la base de données sans avoir besoin de savoir comment les données sont stockées dans un DB pour l'utiliser, c'est ce à quoi sert un moteur DB.
vous avez juste besoin d'être en mesure de "dire" le moteur ce que vous voulez en leur fournissant soit une carte ou une fonction de réduction et puis le moteur DB pourrait trouver son chemin autour des données, appliquer votre fonction, et de venir avec les résultats que vous voulez tout ça sans que tu saches comment ça tourne sur tous les disques.
il y a des index et des touches et des jointures et des vues et beaucoup de choses qu'une seule base de données pourrait contenir, donc en vous protégeant contre la façon dont les données sont réellement stockées, votre code est rendu plus facile à écrire et à maintenir.
même chose pour la programmation parallèle, si vous spécifiez seulement ce que vous voulez faire avec les données au lieu de réellement mettre en œuvre le code boucle, puis l'infrastructure sous-jacente pourrait "paralléliser" et exécuter votre fonction dans une boucle parallèle simultanée pour vous.
MapReduce est une méthode pour traiter de vastes sommes de données en parallèle sans exiger du développeur d'écrire tout autre code que le mapper et réduire les fonctions.
la fonction map prend des données et produit un résultat, qui est maintenu dans une barrière. Cette fonction peut fonctionner en parallèle avec un grand nombre de la même tâche map . L'ensemble de données peut alors être réduit à une valeur scalaire.
donc si vous pensez à cela comme une déclaration SQL
SELECT SUM(salary)
FROM employees
WHERE salary > 1000
GROUP by deptname
nous pouvons utiliser carte pour obtenir notre sous-ensemble d'employés avec un salaire > 1000 quelle carte émet à la barrière en seaux de taille de groupe.
réduire additionnera chacun de ces groupes. Vous donner vos résultats.
je viens de retirer ceci de mon Université notes d'étude du papier google
- Prendre un tas de données
- effectuer une sorte de transformation qui convertit chaque donnée en une autre sorte de donnée
- combiner ces nouvelles données en des données encore plus simples
L'Étape 2 est une carte. L'étape 3 est de réduire.
par exemple,
- le temps entre deux impulsions sur une paire de pression de mètres sur la route
- Carte ces temps en vitesses basées sur la distance des compteurs
- réduire ces vitesses à une vitesse moyenne
la raison pour laquelle MapReduce est divisé entre Map et Reduce est parce que différentes parties peuvent facilement être faites en parallèle. (Surtout si Réduire a certaines propriétés mathématiques.)
pour une description complexe mais bonne de MapReduce, voir: Google MapReduce Programming Model -- Revisited (PDF) .
Carte et réduire sont de vieilles fonctions de Lisp d'une époque où l'homme a tué les derniers dinosaures.
Imaginez que vous ayez une liste de villes avec des informations sur le nom, le nombre de personnes qui y vivent et la taille de la ville:
(defparameter *cities*
'((a :people 100000 :size 200)
(b :people 200000 :size 300)
(c :people 150000 :size 210)))
Maintenant, vous pouvez vouloir trouver la ville avec la densité de population la plus élevée.
d'abord, nous créons une liste des noms de ville et de la densité de population en utilisant la carte:
(map 'list
(lambda (city)
(list (first city)
(/ (getf (rest city) :people)
(getf (rest city) :size))))
*cities*)
=> ((A 500) (B 2000/3) (C 5000/7))
en utilisant REDUCE nous pouvons maintenant trouver la ville avec la plus forte densité de population.
(reduce (lambda (a b)
(if (> (second a) (second b))
a
b))
'((A 500) (B 2000/3) (C 5000/7)))
=> (C 5000/7)
en combinant les deux parties on obtient le code suivant:
(reduce (lambda (a b)
(if (> (second a) (second b))
a
b))
(map 'list
(lambda (city)
(list (first city)
(/ (getf (rest city) :people)
(getf (rest city) :size))))
*cities*))
introduisons des fonctions:
(defun density (city)
(list (first city)
(/ (getf (rest city) :people)
(getf (rest city) :size))))
(defun max-density (a b)
(if (> (second a) (second b))
a
b))
alors nous pouvons écrire notre code de réduction de carte comme:
(reduce 'max-density
(map 'list 'density *cities*))
=> (C 5000/7)
il appelle MAP et REDUCE (l'évaluation est à l'envers), il est donc appelé carte de réduire .
prenons l'exemple du Google paper . Le but de MapReduce est de pouvoir utiliser efficacement une charge d'unités de traitement travaillant en parallèle pour une sorte d'algorithmes. L'exemple est le suivant: vous voulez extraire tous les mots et leur nombre dans un ensemble de documents.
mise en œuvre typique:
for each document
for each word in the document
get the counter associated to the word for the document
increment that counter
end for
end for
MapReduce mise en œuvre:
Map phase (input: document key, document)
for each word in the document
emit an event with the word as the key and the value "1"
end for
Reduce phase (input: key (a word), an iterator going through the emitted values)
for each value in the iterator
sum up the value in a counter
end for
autour de ça, vous aurez un programme maître qui partitionnera l'ensemble des documents en "splits" qui seront traités en parallèle pour la phase Map. Les valeurs émises sont écrites par le travailleur dans un tampon spécifique au travailleur. Le programme maître délègue ensuite d'autres travailleurs pour effectuer la phase de réduction dès qu'il est notifié que le tampon est prêt à être manipulé.
chaque sortie de travailleur (étant une carte ou un travailleur Réduire) est en fait un fichier stocké sur le système de fichiers distribués (GFS pour Google) ou dans la base de données distribuée pour CouchDB.
vraiment facile , rapide et "pour les nuls" introduction à MapReduce est disponible à: http://www.marcolotz.com/?p=67
affichant une partie de son contenu:
tout d'abord, pourquoi MapReduce a-t-il été créé à l'origine?
fondamentalement Google avait besoin d'une solution pour faire de grands travaux de calcul facilement parallélisable, permettant la distribution des données dans un certain nombre de machines connectées à travers un réseau. En plus de cela, il devait gérer la défaillance de la machine de manière transparente et gérer les problèmes d'équilibrage de la charge.
Qu'est-ce que MapReduce true strengths?
on peut dire que MapReduce magic est basé sur L'application Map and Reduce functions. Je dois avouer compagnon, que je suis en total désaccord. La principale caractéristique qui a fait MapReduce si populaire est sa capacité de parallélisation et de distribution automatique, combiné avec l'interface simple. Ces facteurs se sont additionnés avec la gestion transparente des pannes pour la plupart des erreurs ont rendu ce cadre si populaire.
un peu plus de profondeur sur le papier:
MapReduce a été mentionné à l'origine dans un papier Google (Dean & Ghemawat, 2004 – lien ici) comme une solution pour faire des calculs en Big Data en utilisant une approche parallèle et des grappes d'ordinateurs. Contrairement à Hadoop, qui est écrit en Java, le framework de Google est écrit en C++. Le document décrit comment un cadre parallèle se comporterait en utilisant la carte et réduire les fonctions de la programmation fonctionnelle sur de grands ensembles de données.
dans cette solution il y aurait deux étapes principales – appelées Map et Reduce –, avec une étape facultative entre la première et la deuxième – appelée moissonner. L'étape de la carte fonctionnerait en premier, faire des calculs dans le entrée paire clé-valeur et générer une nouvelle sortie clé-valeur. Il faut garder à l'esprit que le format des paires clé-valeur d'entrée n'a pas nécessairement besoin de correspondre à la paire format de sortie. L'Réduire étape assembler toutes les valeurs de la même clé, d'effectuer d'autres calculs sur elle. Par conséquent, cette dernière étape produirait des paires de valeurs clés. L'une des applications les plus triviales de MapReduce est d'implémenter le comptage de mots.
le pseudo-code pour cette application, est indiqué ci-dessous:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, “1”);
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
Comme on peut le remarquer, la carte lit tous les mots dans un dossier (dans ce cas, un dossier peut être une ligne) et émet le mot clé et le numéro 1 en tant que valeur. Plus tard, le réduire regroupera toutes les valeurs de la même clé. Donnons un exemple: imaginez que le mot "maison" apparaît trois fois dans le dossier. L'entrée du réducteur [de la maison,[1,1,1]]. Dans le réducteur, il va faire la somme de toutes les valeurs pour la maison clé et donner en sortie, la valeur clé suivante: [house, [3]].
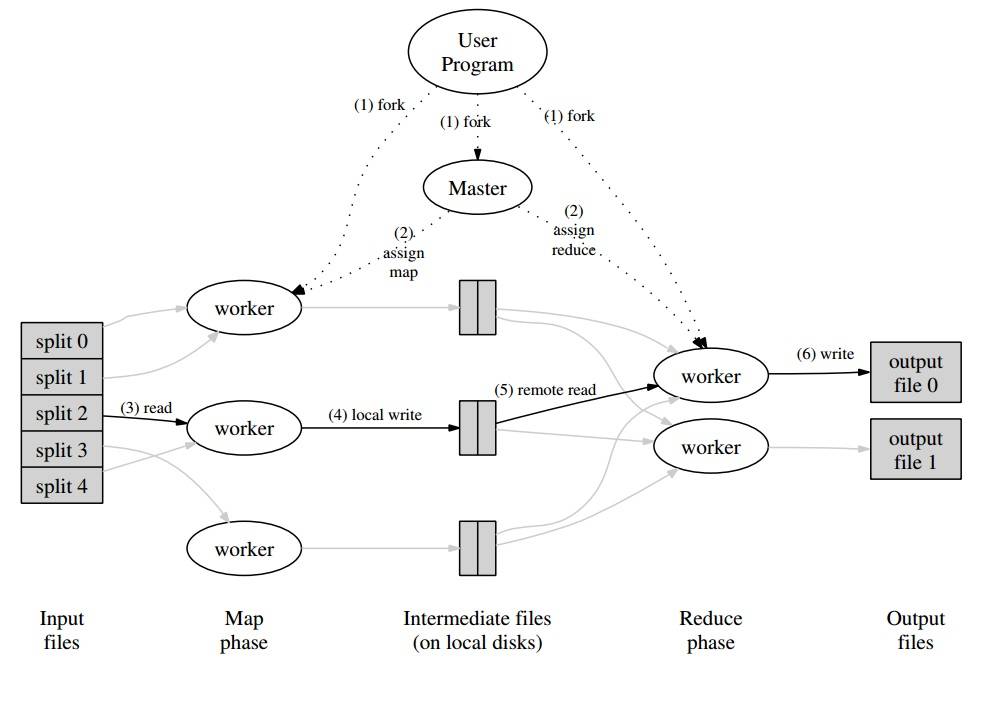
Voici une image de comment cela ressemblerait dans un cadre MapReduce:
Comme quelques autres exemples classiques d'applications MapReduce, on peut dire:
•nombre de URL de la fréquence d'accès
•Reverse Web-lien Graphique
* Grep Distribué 1519100920" "151910920 • * terme Vecteur par hôte
afin d'éviter un trafic trop important sur le réseau, le document décrit comment le cadre devrait essayer de maintenir la localité de données. Cela signifie qu'il doit toujours essayer de s'assurer qu'une machine qui exécute des tâches Map dispose des données dans sa mémoire/stockage local, en évitant de les récupérer sur le réseau. Dans le but de réduire le réseau par la mise d'un mapper, l'étape de combiner optionnelle, décrite précédemment, est utilisée. Le combinateur effectue des calculs sur la les cartographes dans une machine avant de l'envoyer à la Réducteurs – peut-être dans une autre machine.
le document décrit également comment les éléments du cadre doivent se comporter en cas de défauts. Ces éléments, dans le papier, sont appelés ouvrier et maître. Ils seront divisés en éléments plus spécifiques dans les implémentations open source. Depuis que Google a seulement décrit l'approche dans le document et n'a pas publié son logiciel propriétaire, de nombreux cadres open-source ont été créés pour mettre en œuvre le modèle. À titre d'exemple, on peut citer Hadoop ou la fonctionnalité limitée MapReduce en MongoDB.
le temps d'exécution doit prendre en charge les détails des programmeurs non-experts, comme le partitionnement des données d'entrée, la planification de l'exécution du programme à travers le grand ensemble de machines, le traitement des pannes de machines (de manière transparente, bien sûr) et la gestion de la communication inter-machines. Un utilisateur expérimenté peut ajuster ces paramètres, comme la façon dont les données d'entrée être partitionné entre les travailleurs.
Concepts-Clés:
• Tolérance de Panne: Il doit tolérer la défaillance de la machine normalement. Pour ce faire, le maître frappe périodiquement les ouvriers. Si le maître ne reçoit pas de réponse d'un travailleur donné dans un laps de temps déterminé, il définira le travail comme ayant échoué chez ce travailleur. Dans ce cas, toutes les tâches de cartographie effectuées par le travailleur fautif sont jetés et sont donnés à un autre travailleur. Il en est de même si le travailleur était encore en train de traiter une carte ou une tâche de réduction. Notez que si le travailleur a déjà terminé sa partie de réduction, tout le calcul était déjà terminé au moment où il a échoué et n'a pas besoin d'être réinitialisé. Comme premier point d'échec, si le maître échoue, tout le travail échoue. Pour cette raison, on peut définir des points de contrôle périodiques pour le maître, afin de sauvegarder sa structure de données. Tous les calculs qui se produisent entre le dernier point de contrôle et la défaillance du maître sont perdus.
• localité: afin d'éviter le trafic réseau, le framework essaie de s'assurer que toutes les données d'entrée sont disponibles localement pour les machines qui vont effectuer des calculs sur eux. Dans la description originale, il utilise le système de fichiers Google (GFS) avec un facteur de réplication fixé à 3 et des tailles de bloc de 64 Mo. Cela signifie que le même bloc de 64 MO (qui composent un fichier dans le système de fichiers) avoir des copies identiques dans trois machines différentes. Le maître sait où sont les blocs et essaye de programmer les travaux de carte dans cette machine. En cas d'échec, le maître essaie d'attribuer une machine à proximité d'une réplique des tâches entrant des données (c'est-à-dire une machine ouvrière dans le même rack de la machine de données).
• granularité de la tâche: en supposant que chaque phase de la carte est divisée en m morceaux et que chaque phase de réduction est divisée en R morceaux, l'idéal serait que M et R sont beaucoup plus grands que le nombre de machines ouvrières. Cela est dû au fait qu'un travailleur d'effectuer de nombreuses tâches différentes améliore l'équilibrage de charge dynamique. En dehors de cela, il augmente la vitesse de récupération en cas de défaillance du travailleur (puisque les nombreuses tâches de map qu'il a accomplies peuvent être réparties sur toutes les autres machines).
• Backup Tasks: parfois, un Map ou un réducteur peut se comporter beaucoup plus lentement que les autres dans le cluster. Ce peut contenir le temps de traitement total et le rendre égal au temps de traitement de cette machine lente unique. Le document original décrit une alternative appelée tâches de sauvegarde, qui sont programmées par le maître quand une opération MapReduce est sur le point d'être terminée. Ce sont des tâches qui sont programmées par le maître des tâches en cours. Ainsi, L'opération MapReduce se termine lorsque la Primaire ou la sauvegarde se termine.
• Compteurs Parfois, on peut désir de compter les événements occurrences. Pour cette raison, compte où créé. Les contre-valeurs de chaque ouvrier sont périodiquement propagées au maître. Le maître agrège ensuite (Ouep. On dirait que les agrégateurs Pregel sont venus de cet endroit ) les valeurs de compteur d'une carte réussie et réduire la tâche et les retourner au code de l'utilisateur lorsque l'opération MapReduce est terminée. Il y a aussi une contre-valeur courante disponible dans le statut master, de sorte qu'un humain qui regarde le processus peut garder une trace de la façon dont il est comporter.
Eh bien, je suppose qu'avec tous les concepts ci-dessus, Hadoop sera un morceau de gâteau pour vous. Si vous avez des questions au sujet de L'article original de MapReduce ou quelque chose qui s'y rapporte, veuillez me le faire savoir.
Je ne veux pas paraître banal, mais ça m'a tellement aidé, et c'est assez simple:
cat input | map | reduce > output
si vous êtes familier avec Python, voici l'explication la plus simple possible de MapReduce:
In [2]: data = [1, 2, 3, 4, 5, 6]
In [3]: mapped_result = map(lambda x: x*2, data)
In [4]: mapped_result
Out[4]: [2, 4, 6, 8, 10, 12]
In [10]: final_result = reduce(lambda x, y: x+y, mapped_result)
In [11]: final_result
Out[11]: 42
voir comment chaque segment de données brutes a été traité individuellement, dans ce cas, multiplié par 2 (La carte partie de MapReduce). Sur la base du mapped_result , nous avons conclu que le résultat serait 42 (le réduire partie de MapReduce).
exemple est le fait que chaque bloc de traitement ne dépend pas d'un autre bloc. Par exemple , si thread_1 maps [1, 2, 3] , et thread_2 maps [4, 5, 6] , le résultat final des deux threads serait toujours [2, 4, 6, 8, 10, 12] mais nous avons divisé par deux le temps de traitement pour cela. On peut dire la même chose pour l'opération de réduction et c'est l'essence de la façon dont MapReduce fonctionne dans le calcul parallèle.