Les bases de données OLAP devraient-elles être dénormalisées pour les performances de lecture?
j'ai toujours pensé que les bases de données devraient être dénormalisées pour la performance de lecture, comme il est fait pour la conception de base de données OLAP, et pas exagéré plus loin 3NF pour la conception OLTP.
PerformanceDBA dans divers postes, par exemple: dans la Performance des différents aproaches à la fois base de données , défend le modèle de base de données doit toujours être bien conçu par la normalisation de 5NF et 6NF (Forme Normale).
Ai-Je bien compris (et qu'avais-je bien compris)?
Quel est le problème avec le traditionnel dénormalisation de l'approche d'un paradigme de conception de bases de données OLAP (ci-dessous 3FN) et les conseils que 3FN est suffisant pour la plupart des cas pratiques, des bases de données OLTP?
par exemple:
- "la simple vérité ... c'est que 6NF, exécutée correctement, est l'entrepôt de données" (PerformanceDBA)
je dois avouer que je n'ai jamais pu saisir les théories que la dénormalisation facilite la performance en lecture. Est-ce que quelqu'un peut me donner des références avec de bonnes explications logiques de ceci et des croyances contraires?
quelles sont les sources auxquelles je peux me référer lorsque j'essaie de convaincre mes intervenants que les bases de données du programme D'entreposage des données devraient être normalisées?
pour améliorer la visibilité j'ai copié ici des commentaires:
"Ce serait bien si les participants ajouter (divulguer) combien de vie réelle (non projets scientifiques inclus) implémentations d'entrepôt de données en 6NF ils ont vu ou participé. Une sorte de rapide de la piscine. Me = 0."- Damir Sudarevic
article de L'entrepôt de données de Wikipedia dit:
"L'approche normalisée [vs dimensionnel par Ralph Kimball], aussi appelé le modèle 3NF (troisième forme normale) dont les partisans sont appelé "Inmonites", croire en L'approche de Bill Inmon il est indiqué que l'entrepôt de données devrait être modélisé à l'aide D'un E-R modèle/modèle normalisé."
il semble que L'approche de l'entreposage normalisé des données (par Bill Inmon) ne soit pas perçue comme dépassant 3NF (?)
je veux juste comprendre quelle est l'origine du mythe (ou croyance axiomatique omniprésente) que l'entreposage de données/OLAP est synonyme de dénormalisation?
Damir Sudarevic a répondu qu'il s'agit d'une approche bien pavée. Permettez-moi de revenir à la question suivante: Pourquoi croit-on que la dénormalisation facilite la lecture?
9 réponses
Mythologie
j'ai toujours pensé que les bases de données devraient être dénormalisées pour la lecture, comme il est fait pour la conception de base de données OLAP, et pas exagéré beaucoup plus loin 3NF pour la conception OLTP.
il y a un mythe à cet effet. Dans le contexte de la base de données relationnelle, j'ai ré-mis en œuvre six très grandes "bases de données" dites "de-normalisées"; et exécuté plus de quatre-vingts tâches corriger des problèmes sur d'autres, simplement en les normalisant, en appliquant des normes et des principes d'ingénierie. Je n'ai jamais vu aucune preuve pour le mythe. Seulement les gens qui répètent le mantra comme si c'était une sorte de prière magique.
Normalisation vs non-normalisation
("dénormalisation" est un terme frauduleux que je refuse d'utiliser.)
il s'agit d'une industrie scientifique (au moins le peu que fournit des logiciels qui ne cassent pas, qui mettent les gens sur la Lune, qui font fonctionner des systèmes bancaires, etc.). Il est régi par les lois de la physique, pas de la magie. Les ordinateurs et les logiciels sont tous des objets finis, tangibles, physiques qui sont soumis aux lois de la physique. Selon l'enseignement secondaire et supérieur que j'ai reçu:
-
il n'est pas possible pour un objet plus gros, moins organisé d'effectuer mieux qu'un plus petit, plus mince, plus organisé objet.
-
la Normalisation produit plus de tableaux, Oui, mais chaque tableau est beaucoup plus petit. Et même s'il y a plus de tables, il y a en fait (A) moins de jointures et (b) les jointures sont plus rapides parce que les ensembles sont plus petits. Dans l'ensemble, il faut moins d'Indices, car chaque tableau plus petit a besoin de moins d'indices. Les tableaux normalisés donnent aussi des rangs beaucoup plus courts.
-
pour tout ensemble de ressources, Tableaux normalisés:
- insérer plus de lignes dans la même taille de page
- s'adapte donc à plus de lignes dans le même espace de cache, donc le débit global est augmenté)
- s'adapte donc à plus de lignes dans le même espace disque, donc le no de I/Os est réduit; et quand I/O est demandé, chaque I/O est plus efficace.
.
- il n'est pas possible pour un objet qui est fortement dupliqué à faire mieux qu'un objet qui est stockée qu'une seule version de la vérité. Par exemple. lorsque j'ai supprimé la duplication 5 x au niveau de la table et de la colonne, Toutes les transactions ont été réduites en taille; le verrouillage a été réduit; les Anomalies de mise à jour ont disparu. Cela a considérablement réduit la prétention et donc augmenté l'utilisation concurrente.
le résultat global est donc beaucoup, beaucoup plus élevé.
d'après mon expérience, qui fournit à la fois OLTP et OLAP à partir de la même base de données, il n'a jamais été nécessaire de" dénormaliser " mes structures normalisées, pour obtenir une vitesse plus élevée pour les requêtes en lecture seule (OLAP). C'est un mythe.
- non, la" désormalisation " demandée par d'autres à vitesse réduite, et il a été éliminé. Cela ne me surprend pas, mais encore une fois, les demandeurs ont été surpris.
de nombreux livres ont été écrit par des gens, vendant le mythe. Il faut reconnaître qu'il s'agit de gens non techniques; puisqu'ils vendent de la magie, la magie qu'ils vendent n'a pas de base scientifique, et ils évitent commodément les lois de la physique dans leur discours de vente.
(pour quiconque souhaite contester la science physique ci-dessus, le simple fait de répéter le mantra n'aura aucun effet, veuillez fournir des preuves spécifiques à l'appui du mantra.)
pourquoi le mythe Prévalente ?
Eh bien, d'abord, il n'est pas répandu parmi les types scientifiques, qui ne cherchent pas les moyens de surmonter les lois de la physique.
D'après mon expérience, j'ai identifié trois principales raisons de la prévalence:
-
pour les personnes qui ne peuvent pas normaliser leurs données, c'est une justification commode pour ne pas le faire. Ils peuvent se référer au livre de magie et sans aucune preuve pour l' par magie, ils peuvent dire avec révérence"voir un écrivain célèbre valider ce que j'ai fait". Pas Fait, avec le plus de précision.
-
de nombreux codeurs SQL ne peuvent écrire que du SQL simple, à un seul niveau. Les structures normalisées nécessitent un peu de capacité SQL. S'ils n'ont pas cela; s'ils ne peuvent pas produire SELECTs sans utiliser des tables temporaires; s'ils ne peuvent pas écrire des sous-requêtes, ils seront psychologiquement collés à la hanche à des fichiers plats (ce qui est ce que " dés-normalisé" structures sont), qu'ils can processus.
-
les Gens amour pour lire des livres, et à discuter les théories. Sans expérience. Surtout de re de la magie. C'est un tonique, un substitut à l'expérience réelle. Quiconque a effectivement normalisé correctement une base de données n'a jamais déclaré que "la dénormalisation est plus rapide que la normalisation". Pour toute personne déclarant l'mantra, je dis simplement "montrez-moi la preuve", et ils ont jamais produit. Ainsi, la réalité est, les gens répètent la mythologie pour ces raisons, sans aucune expérience de Normalisation . Nous sommes des animaux du troupeau, et l'inconnu est une de nos plus grandes peurs.
C'est pourquoi J'ai toujours inclus le SQL" avancé " et le mentorat sur n'importe quel projet.
Ma Réponse
cette réponse sera ridiculement longue si je réponds chaque partie de votre question ou si je réponds aux éléments incorrects de certaines autres réponses. Par exemple. ce qui précède n'a répondu qu'à un seul point. Par conséquent, je vais répondre à votre question dans son ensemble sans aborder les éléments spécifiques, et adopter une approche différente. Je ne traiterai que de la science liée à votre question, pour laquelle je suis qualifié et très expérimenté.
Permettez-moi de vous présenter la science dans des segments gérables.
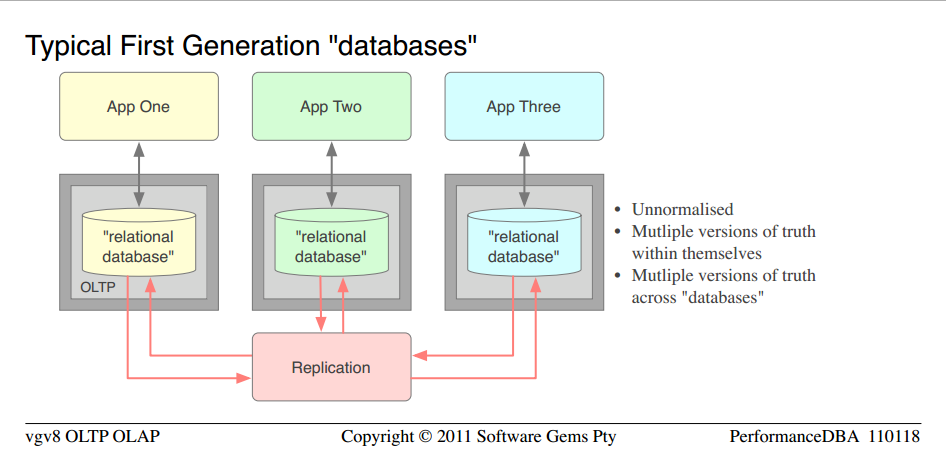
Le modèle typique des six missions de mise en oeuvre complète à grande échelle.
- il s'agit des "bases de données" fermées que l'on trouve couramment dans les petites entreprises, et les organisations sont de grandes banques
- très agréable pour une première génération, l'application get-the-running mindset, mais un échec complet en termes de performance, d'intégrité et de qualité
- ils ont été conçus pour chaque application, séparément
- la déclaration n'était pas possible, ils ne pouvaient déclarer que via chaque application
- puisque "dénormalisé" est un mythe, La définition technique précise est, ils étaient non-normalisé
- pour "dé-normaliser" il faut D'abord normaliser; puis inverser un peu le processus dans tous les cas où les gens m'ont montré leurs modèles de données "dé-normalisés", le simple fait était qu'ils n'avaient pas du tout normalisé; ainsi, la "dé-normalisation" était pas possible; il était tout simplement non-normalisé
- puisqu'ils n'avaient pas beaucoup de technologie relationnelle, ou les structures et le contrôle des bases de données, mais ils ont été passés au loin en tant que" bases de données", j'ai placé ces mots entre guillemets
- comme cela est scientifiquement garanti pour les structures non normalisées, ils ont souffert de multiples versions de la vérité (duplication des données) et donc de forte discorde et de faible concurrence, à l'intérieur de chaque d'entre eux
- ils ont eu un problème supplémentaire de duplication des données à travers les "bases de données "
- l'organisation essayait de garder tous ces doublons synchronisés, donc ils ont mis en place la réplication; ce qui bien sûr signifiait un serveur supplémentaire; ETL et des scripts de synchronisation à développer; et maintenu; etc
- inutile de dire que le synchronisme n'a jamais été suffisant et qu'ils l'ont changé à jamais
- avec toute cette assertion et le faible débit, il n'y avait aucun problème à justifier un serveur distinct pour chaque "base de données". Il n'a pas beaucoup d'aide.
ainsi nous avons contemplé les lois de la physique, et nous avons appliqué un peu de science.
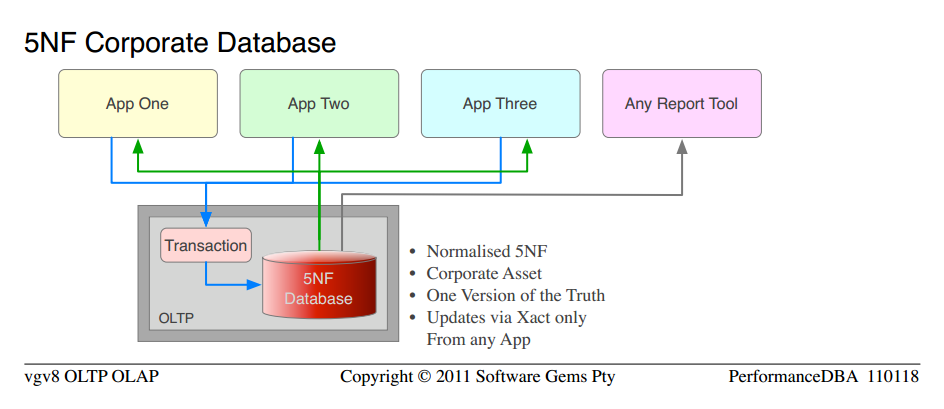
Nous avons mis en œuvre le concept Standard selon lequel les données appartiennent à la société (et non aux ministères) et la société voulait une version de la vérité. La base de données était purement relationnelle, normalisée à 5NF. Pure Architecture ouverte, de sorte que n'importe quelle application ou outil de rapport pourrait y accéder. Toutes les transactions dans les procs stockés (par opposition aux chaînes non contrôlées de SQL sur tout le réseau). Les mêmes développeurs pour chaque application ont codé les nouvelles applications, après notre formation "avancée".
de toute évidence, la science a fonctionné. Ce n'était pas ma science privée ou ma magie, c'était l'ingénierie ordinaire et les lois de la physique. Tout a fonctionné sur une base de données plate-forme Serveur; deux paires de serveurs (production et RD) ont été déclassées et confiées à un autre ministère. Les 5" bases de données " totalisant 720GB ont été normalisées en une seule base de données totalisant 450GB. Environ 700 tableaux (beaucoup de doubles et de colonnes dupliquées) ont été normalisés en 500 tableaux Non dupliqués. Il a fonctionné beaucoup plus vite, comme dans 10 fois plus rapide dans l'ensemble, et plus de 100 fois plus rapide dans certaines fonctions. Cela ne me surprend pas, parce que c'était mon intention, et la science prédit, mais il a surpris les gens avec le mantra.
Plus De Normalisation
Eh bien, ayant eu du succès avec la Normalisation dans chaque projet, et la confiance avec la science impliquée , il a été une progression naturelle pour normaliser plus , pas moins. Dans le passé, 3NF était assez bon, et plus tard NFs n'ont pas encore été identifiés. Au cours des 20 dernières années, je n'ai fourni que des bases de données qui n'avaient aucune anomalie de mise à jour., il s'avère donc par les définitions d'aujourd'hui de NFs, j'ai toujours livré 5NF.
de même, 5NF est grand mais il a ses limites. Par exemple. Les tables pivotantes de grande taille (pas de petits ensembles de résultats selon L'Extension de PIVOT MS) étaient lentes. Ainsi, j'AI (et d'autres) développé un moyen de fournir des tables normalisées de telle sorte que pivoter était (a) facile et (b) très rapide. Il s'avère maintenant que 6NF a été défini, que ces tables sont 6NF.
puisque je fournis OLAP et OLTP de la même base de données, j'ai constaté que, en accord avec la science, les structures plus normalisées sont:
-
le plus rapide qu'ils effectuent
-
et ils peuvent être utilisés de plusieurs façons (par exemple Pivots)
donc oui, j'ai une expérience cohérente et constante, que non seulement est normalisée beaucoup, beaucoup plus rapide que non-normalisée ou "débormalisée"; plus normalisé est encore plus rapide que moins normalisé.
un signe de succès est la croissance de la fonctionnalité (le signe de l'échec est la croissance de la taille sans croissance de la fonctionnalité). Ce qui signifie qu'ils nous ont immédiatement demandé plus de fonctionnalité de rapport, ce qui signifie que nous normalisé encore plus , et fourni plus de ces tableaux spécialisés (qui s'est avéré des années plus tard, pour être 6NF).
Progressing sur ce thème. J'ai toujours été un spécialiste des bases de données, pas un spécialiste des entrepôts de données, de sorte que mes premiers projets avec des entrepôts n'étaient pas des mises en œuvre complètes, mais plutôt, ils étaient des affectations substantielles de réglage de performance. Ils étaient dans mon domaine, sur des produits que je me suis spécialisé.
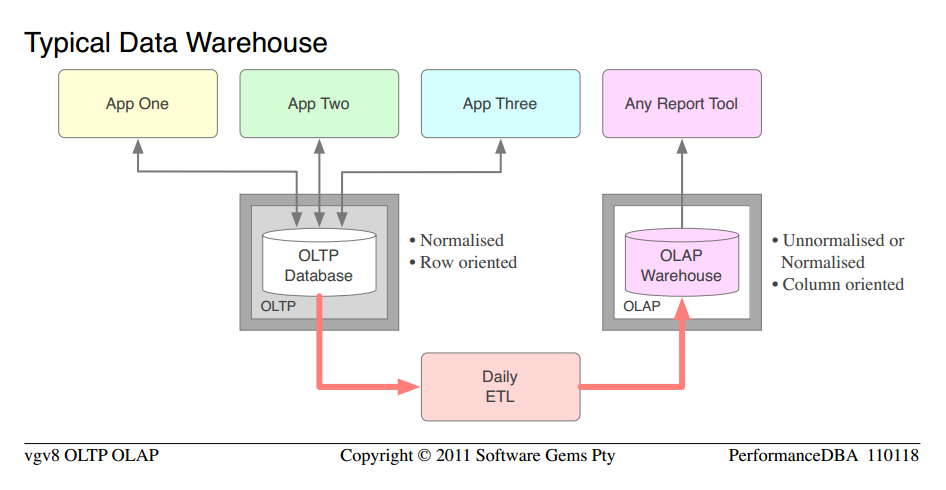
Ne nous soucions pas du niveau exact de normalisation, etc., car nous examinons le cas typique. Nous pouvons le prendre comme étant donné que la base de données OLTP a été raisonnablement normalisé, mais pas capable de L'OLAP, et l'organisation avait acheté une plate-forme OLAP complètement séparée, du matériel, investi dans le développement et le maintien de masses de code ETL, etc. Après la mise en œuvre, ils ont passé la moitié de leur vie à gérer les doublons qu'ils avaient créés. Ici, les rédacteurs de livres et les vendeurs doivent être blâmés, pour le gaspillage massif de matériel et séparé licences de logiciels de plate-forme qu'ils poussent les organisations à acheter.
- si vous ne l'avez pas encore observé, je vous demanderais de noter les similitudes entre la base de données première génération typique " et le entrepôt de données typique "
pendant ce temps, de retour à la ferme (les 5NF bases de données ci-dessus) nous avons juste continué à ajouter de plus en plus de fonctionnalités OLAP. Bien sûr, la fonctionnalité de l'application a augmenté, mais c'était peu, l'entreprise a eu pas changé. Ils demanderaient plus de 6NF et c'était facile à fournir (5NF à 6NF est un petit pas; 0NF à n'importe quoi, et encore moins 5NF, est un grand pas; une architecture organisée est facile à étendre).
une différence majeure entre OLTP et OLAP, la justification de base de séparé logiciel de plate-forme OLAP, est que L'OLTP est orienté vers les lignes, il a besoin de lignes sécurisées transactionnellement, et rapide; et L'OLAP ne se soucie pas des questions transactionnelles, il a besoin les colonnes, et rapide. C'est la raison pour laquelle tous les bi haut de gamme ou OLAP plates-formes sont orientés colonne, et c'est pourquoi les OLAP modèles (schéma D'Étoile, Dimension-fait) sont orientés colonne.
mais avec les tableaux 6NF:
-
il n'y a pas de lignes, seulement des colonnes; nous servons des lignes et des colonnes à la même vitesse d'aveuglement
-
les tables (c'est à dire. le 5NF vue des structures 6NF) sont déjà organisés en Dimension-faits. En fait, ils sont organisés en plus de Dimensions que n'importe quel modèle OLAP ne pourrait jamais identifier, parce qu'ils sont toutes Dimensions.
-
pivoter des tables entières avec agrégation à la volée (par opposition au PIVOT D'un petit nombre de colonnes dérivées) est (a) sans effort, code simple et (b) très rapide
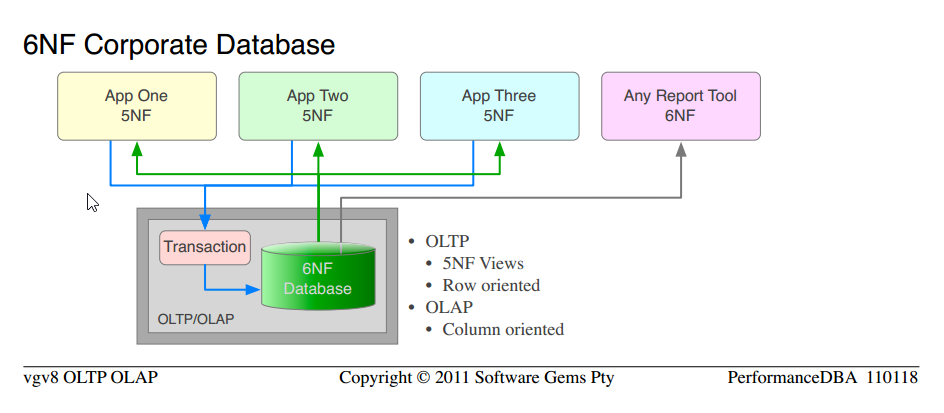
ce que nous fournissons depuis de nombreuses années, par définition, sont des bases de données relationnelles avec au moins 5NF pour L'utilisation OLTP, et 6NF pour les exigences OLAP.
-
notez que c'est la même science que nous avons utilisée dès le début; pour passer de des" bases de données typiques non normalisées " à 5NF Corporate Database . Nous appliquons simplement plus de la science éprouvée, et obtenir des ordres plus élevés de fonctionnalité et de performance.
-
remarque la similitude entre 5NF Base de données d'Entreprise et 6NF Base de données d'Entreprise
-
le coût total du matériel OLAP séparé, du logiciel de plate-forme, de L'ETL, de l'administration, de la maintenance, sont tous éliminés.
-
il n'y a qu'une seule version des données, pas d'anomalies de mise à jour ou de leur maintenance; les mêmes données servies pour OLTP que les lignes, et pour OLAP que les colonnes
la seule chose que nous n'avons pas faite, est de commencer sur un nouveau projet, et de déclarer pur 6NF dès le début. C'est ce que j'ai alignés suivant.
Qu'est-ce que la sixième forme normale ?
en supposant que vous avez un contrôle sur Normalisation (je ne vais pas définissent pas ici), la non-définitions académiques pertinentes à ce fil sont comme suit. Notez qu'il s'applique au niveau de la table, donc vous pouvez avoir un mélange de 5NF et 6NF tables dans la même base de données:
- cinquième forme normale : toutes les dépendances fonctionnelles résolues dans la base de données
- en plus de 4NF /BCNF
- chaque colonne non-PK est 1:: 1 avec son PK
- et à aucune autre PK
- Pas De Mise À Jour Des Anomalies
.
- sixième forme normale : est le NF irréductible, le point auquel les données ne peuvent plus être réduites ou normalisées (il N'y aura pas de 7NF)
- en plus de 5NF
- la rangée se compose d'une clé primaire et, au plus, d'une colonne sans clé.
- élimine le problème nul
à quoi ressemble le 6NF ?
les Modèles de données appartiennent aux clients, et notre propriété intellectuelle n'est pas disponible pour la publication gratuite. Mais je suis présent sur ce site web et je donne des réponses précises aux questions. Vous avez besoin d'un exemple réel, donc je vais publier le Modèle de Données pour l'un de nos utilitaires interne.
celui-ci est pour la collecte de données de surveillance de serveur (enterprise class database server and OS) pour tout nombre de clients, pour n'importe quelle période. Nous nous en servons pour analyser les problèmes de performance à distance et pour vérifier tout réglage de performance que nous faisons. La structure n'a pas changé en plus de dix ans (ajouté à, Sans changement aux structures existantes), il est typique de la 5NF spécialisée que de nombreuses années plus tard a été identifié comme 6NF. Permet un pivotement complet; n'importe quelle carte ou graphique pour être dessiné, sur n'importe quelle Dimension (22 Pivots sont fournis mais ce n'est pas une limite); tranche et dés; mélange et match. Notez qu'ils sont toutes les Dimensions.
les données de surveillance ou les mesures ou les vecteurs peuvent changer (changements de version du serveur; nous voulons prendre quelque chose de plus) sans affecter le modèle (vous pouvez vous rappeler dans un autre post j'ai déclaré EAV est le fils bâtard de 6NF; Eh bien C'est complet 6NF, le père non-dilué, et fournit donc toutes les fonctionnalités de EAV, sans sacrifier aucune norme, intégrité ou puissance relationnelle); vous ajoutez simplement des lignes.
▶Les Statistiques De La Surveillance Du Modèle De Données◀ . (trop grand pour inline; certains navigateurs ne peuvent pas charger inline; cliquez sur le lien)
il me permet de produire ces cartes comme cette փ , six touches après avoir reçu un fichier de stats de suivi brut du client. Remarquez le mix-and-match; OS et server sur le même graphique; une variété de Pivots. (Utilisé avec permission.)
les lecteurs qui ne sont pas familiers avec la norme pour la modélisation des bases de données relationnelles peuvent trouver le փ idef1x notation փ utile.
6NF Entrepôt de Données
Cela a été récemment validé par Modélisation d'Ancrage , en ce que ils présentent maintenant 6NF comme le modèle OLAP de" nouvelle génération " pour les entrepôts de données. (Ils ne fournissent pas L'OLTP et L'OLAP à partir de la version unique des données, qui est la nôtre seule).
Entrepôt De Données (Seulement) De L'Expérience
mon expérience avec les entrepôts de données seulement (pas les bases de données OLTP-OLAP de 6NF ci-dessus), a été plusieurs missions importantes, par opposition à des projets de mise en œuvre complète. Les résultats ont été, sans surprise:
-
conformément à la science, les structures normalisées fonctionnent beaucoup plus rapidement, sont plus faciles à entretenir et nécessitent moins de synchronisation des données. Inmon, pas Kimball.
-
en accord avec la magie, après que j'ai normalisé un tas de tables, et de fournir des performances considérablement améliorées par l'application des lois de la physique, les seules personnes surprises sont les magiciens avec leurs mantras.
les gens à l'esprit scientifique ne font pas cela; ils ne croient pas aux balles d'argent et à la magie, et ne comptent pas sur elles; ils utilisent et travaillent dur la science pour résoudre leurs problèmes.
Valide Les Données De L'Entrepôt De La Justification
C'est pourquoi j'ai déclaré dans d'autres postes, le seul valable justification pour une plate-forme D'entrepôt de données séparée, matériel, ETL, la maintenance, etc, est où il ya de nombreuses bases de données ou "bases de données", toutes fusionnées dans un entrepôt central, pour les rapports et OLAP.
Kimball
un mot sur Kimball est nécessaire, car il est le principal promoteur de la" normalisation pour la performance " dans les entrepôts de données. Selon mes définitions ci-dessus, il est l'une de ces personnes qui ont évidemment jamais normalisé dans leurs vies; son point de départ a été non-normalisé (camouflé comme "dé-normalisé") et il a simplement mis en œuvre cela dans une Dimension-modèle de fait.
-
bien sûr, pour obtenir n'importe quelle performance, il a dû" dé-normaliser " encore plus, et créer de nouveaux doublons, et justifier tout cela.
-
il est donc vrai, d'une manière schizophrénique, que la "dénormalisation"des structures non normalisées, par la réalisation de copies plus spécialisées, "améliore la performance de lecture". Il n'est pas vrai quand le tout est pris en compte, il n'est vrai qu'à l'intérieur de ce petit asile, pas à l'extérieur.
-
de même, il est vrai, de cette manière folle, que là où toutes les" tables "sont des monstres, que" les jointures sont coûteuses " et quelque chose à éviter. Ils n'ont jamais eu l'expérience de joindre des tables et des ensembles plus petits, de sorte qu'ils ne peuvent pas croire le fait scientifique que plus, plus petites tables sont plus rapides.
-
ils ont l'expérience que créer duplicate " tables "est plus rapide, de sorte qu'ils ne peuvent pas croire que éliminer duplicates est encore plus rapide que cela.
-
-
ses Dimensions sont ajouté aux données non normalisées. Les données ne sont pas normalisées, donc aucune dimension n'est exposée. Alors que dans un modèle normalisé, les Dimensions sont déjà exposées, en tant que partie intégrante des données, no ajout est nécessaire.
-
ce sentier bien pavé de Kimball mène à la falaise, où plus de lemmings tombent à leur mort, plus vite. Les Lemmings sont des animaux de troupeau, tant qu'ils marchent ensemble sur le chemin, et meurent ensemble, ils meurent heureux. Les Lemmings ne cherchent pas d'autres chemins.
toutes les histoires justes, les parties de la mythologie unique qui traînent ensemble et se soutenir les uns les autres.
Votre Mission
si vous choisissez de l'accepter. Je vous demande de penser par vous-même, et d'arrêter de divertir toute pensée qui contredit la science et les lois de la physique. Peu importe à quel point ils sont communs ou mystiques ou mythologiques. Cherchez des preuves pour quoi que ce soit avant de lui faire confiance. Soyez scientifique, vérifiez de nouvelles croyances pour vous-même. Répéter le mantra " dés-normalisé pour la performance" ne va pas rendre votre base de données plus rapide, il va juste vous faire sentir mieux à ce sujet. Comme le gros qui se dit qu'il peut courir plus vite que tous les autres.
- sur cette base, même le concept" normaliser pour OLTP "mais faire le contraire," de-normaliser pour OLAP " est une contradiction. Comment les lois de la physique peuvent-elles fonctionner comme indiqué sur un ordinateur, mais travailler à l'inverse sur un autre ordinateur ? Le affolants. Il n'est tout simplement pas possible, le travail de la même façon sur chaque ordinateur.
Questions ?
la dénormalisation et l'agrégation sont les deux principales stratégies utilisées pour atteindre la performance dans un entrepôt de données. Il est juste stupide de suggérer qu'il n'améliore pas la performance de lecture! Certes, je doit avoir missunderstood quelque chose ici?
agrégation: Considérons une table contenant 1 milliard d'achats. Comparez-le à un tableau comportant une rangée avec la somme des achats. Maintenant, ce qui est le plus rapide? Sélectionnez somme (montant) dans le tableau d'un milliard de lignes ou un montant choisi dans la table à une rangée? C'est un exemple stupide, bien sûr, mais il illustre le principe de l'agrégation assez clairement. Pourquoi est-il plus rapide? Car quel que soit le modèle magique/le matériel/le logiciel/la religion que nous utilisons, Lire 100 octets est plus rapide que lire 100 gigaoctets. Simple que cela.
dénormalisation: Une dimension de produit typique dans un entrepôt de données de détail a des tas de colonnes. Certaines colonnes sont des trucs faciles comme "nom" ou "Couleur", mais il a aussi quelques trucs compliqués, comme les hiérarchies. Hiérarchies multiples (gamme de produits (5 niveaux), acheteur prévu (3 niveaux), matières premières (8 niveaux), mode de production (8 niveaux) ainsi que plusieurs nombres calculés tels que le délai moyen de livraison (depuis le début de l'année), mesures de poids/emballage etcetera et cetera. J'ai maintenu une table de dimension de produit avec plus de 200 colonnes qui a été construit à partir de ~70 tables de 5 systèmes de source différents. Il est tout simplement stupide le débat de savoir si une requête sur le modèle normalisé (ci-dessous)
select product_id
from table1
join table2 on(keys)
join (select average(..)
from one_billion_row_table
where lastyear = ...) on(keys)
join ...table70
where function_with_fuzzy_matching(table1.cola, table37.colb) > 0.7
and exists(select ... from )
and not exists(select ...)
and table20.version_id = (select max(v_id from product_ver where ...)
and average_price between 10 and 20
and product_range = 'High-Profile'
... est plus rapide que la requête équivalente sur le modèle dénormalisé:
select product_id
from product_denormalized
where average_price between 10 and 20
and product_range = 'High-Profile';
pourquoi? En partie pour la même raison que le scénario agrégé. Mais aussi parce que, les requêtes sont juste "compliqué". Ils sont si horriblement compliqués que l'optimiseur (et maintenant je vais Oracle spécificités) se confond et Foire les plans d'exécution. Les plans d'exécution sous-optimaux ne peuvent être une grosse affaire, si la requête concerne une petite quantité de données. Mais dès que nous commençons à rejoindre dans les grandes Tables, c'est crucial que la base de données obtient le bon plan d'exécution. Ayant dénormalisé les données dans un tableau avec une seule touche syntétique (heck, pourquoi ne pas ajouter plus de carburant à ce feu en cours), les filtres deviennent des filtres simples de gamme/égalité sur les colonnes précuites. Après avoir dupliqué le dans de nouvelles colonnes nous permet de recueillir des statistiques sur les colonnes qui aidera l'optimiseur à estimer les sélectivités et nous fournir ainsi un plan d'exécution approprié (Eh bien,...).
de toute évidence, l'utilisation de la dénormalisation et de l'agrégation rend plus difficile l'adaptation des changements de schéma, ce qui est une mauvaise chose. D'autre part, ils offre des performances de lecture, ce qui est une bonne chose.
alors, devriez-vous dénormaliser votre base de données afin d'obtenir des performances de lecture? L'enfer non! Il ajoute tant de complexités à votre système qu'il n'y a pas de fin à toutes les façons dont il vous fera tomber avant que vous ayez livré. Est-il utile? Oui, parfois vous devez le faire pour répondre à une exigence de rendement spécifique.
"151950920 mise à jour" Update 1
PerformanceDBA: 1 ligne serait mis à jour un milliard de fois par jour
, ce qui impliquerait une exigence (proche) en temps réel (qui, à son tour, générerait un ensemble complètement différent d'exigences techniques). Beaucoup (si pas plus) entrepôts de données n'a pas cette exigence. J'ai choisi un exemple d'agrégation irréaliste juste pour expliquer pourquoi l'agrégation fonctionne. Je n'ai pas envie d'expliquer cumulatif des stratégies de trop :)
aussi, on doit comparer les besoins de l'utilisateur typique d'un entrepôt de données et l'utilisateur typique du système OLTP sous-jacent. Un utilisateur qui cherche à comprendre quels sont les facteurs qui déterminent les coûts de transport, s'en fiche si 50% des données d'aujourd'hui sont manquantes ou si 10 camions a explosé et tué les pilotes. Effectuer l'analyse des données sur deux ans aboutirait toujours à la même conclusion, même s'il devait disposer de la seconde information à jour.
Contraste avec les besoins des conducteurs de camion (ceux qui ont survécu). Ils ne peuvent pas attendre 5 heures à un point de transit juste parce qu'un stupide processus d'agrégation a le finnois. Avoir deux copies des données de résoudre les besoins.
Un autre obstacle majeur au partage du même ensemble de données pour les systèmes opérationnels et les systèmes de rapports est que les cycles de publication, Q&A, déploiement, ans et ce que vous avez, sont très différents. Encore une fois, le fait d'avoir deux copies distinctes rend la manipulation plus facile.
par" OLAP " je comprends que vous voulez dire une base de données relationnelle / SQL orientée sujet utilisé pour le soutien de décision-alias un entrepôt de données.
La forme normale(typiquement la forme normale 5 / 6) est généralement le meilleur modèle pour un entrepôt de données. Les raisons pour normaliser un entrepôt de données sont exactement les mêmes que n'importe quelle autre base de données: il réduit la redondance et évite les anomalies de mise à jour potentielles; il évite le biais intégré et est donc la façon la plus facile de supporter le changement de schéma et les nouvelles exigences. L'utilisation de la forme normale dans un entrepôt de données permet également de garder le processus de charge de données simple et cohérente.
il n'y a pas d'approche" traditionnelle " de dénormalisation. Bon entrepôts de données ont toujours été normalisé.
une base de données ne devrait-elle pas être dénormalisée pour les performances de lecture?
D'accord, voici un total "votre kilométrage peut varier", "Cela dépend", "utilisez L'outil approprié pour chaque travail"," une taille ne convient pas tous "réponse, avec un peu de" ne pas réparer si elle N'est pas cassée "jeté dans:
la dénormalisation est une façon d'améliorer les performances de requête dans certaines situations. Dans d'autres situations, il peut en fait réduire la performance (parce que de l'augmentation de l'utilisation du disque). Cela rend certainement les mises à jour plus difficiles.
il ne doit être considéré que lorsque vous rencontrez un problème de performance (parce que vous donnez les avantages de la normalisation et introduisez la complexité).
les inconvénients de la dénormalisation sont moins un problème avec les données qui ne sont jamais mises à jour, ou seulement mises à jour dans les travaux par lots, c.-à-d. pas les données OLTP.
si la dénormalisation résout un problème de performance dont vous avez besoin résolu, et que les techniques moins invasives (comme les index ou les caches ou l'achat d'un serveur plus grand) ne résolvent pas, alors oui, vous devriez le faire.
D'abord mes opinions, puis quelques analyses
Avis
La dénormalisation est perçue comme une aide à la lecture des données parce que l'utilisation courante du mot dénormalisation inclut souvent non seulement briser les formes normales, mais aussi introduire toute dépendance d'insertion, de mise à jour et de suppression dans le système.
ceci, à proprement parler ,est false , voir ce question / réponse , la dénormalisation au sens strict signifie casser n'importe laquelle des formes normales de 1NF-6NF, d'autres dépendances d'insertion, de mise à jour et de suppression sont abordées avec principe de la conception orthogonale .
donc, ce qui se passe est que les gens prennent le espace vs le principe de compromis du temps et se rappeler le terme redondance (associée à la dénormalisation, toujours pas égale à elle) et de conclure que vous devriez avoir avantage. Il s'agit d'une implication erronée, mais de fausses implications ne vous permettent pas de conclure le contraire.
Casser les formes normales peut en effet accélérer certains récupération de données (plus de détails dans l'analyse ci-dessous), mais en règle générale, il sera également à la même époque:
- ne favorisent que les types spécifiques de requêtes et ralentissent tous les autres chemins d'accès
- augmentation de la complexité de l' système (qui influence non seulement la mise à jour de la base de données elle-même, mais augmente également la complexité des applications qui consomment les données)
- obscurcir et affaiblir la clarté sémantique de la base de données
- point principal des systèmes de base de données, comme les données centrales représentant l'espace de problème doit être impartial dans l'enregistrement des faits, de sorte que lorsque les besoins changent, vous ne devez pas reconcevoir les parties du système (données et applications) qui sont indépendant dans la réalité. pour être en mesure de faire ces dépendances artificielles devrait être minimisé - l'exigence "critique" d'aujourd'hui pour accélérer une requête assez souvent devient seulement marginalement important.
analyse
donc, j'ai fait une réclamation que parfois rupture formes normales peut aider à la récupération. Le temps de donner quelques arguments
1) rupture 1NF
supposons que vous avez des documents financiers dans 6NF. À partir de cette base de données, vous pouvez certainement obtenir un rapport sur ce qui est un solde pour chaque compte pour chaque mois.
en supposant qu'une requête qui aurait à calculer un tel rapport devrait passer par n enregistrements vous pourriez faire une table
account_balances(month, report)
qui contiendrait des soldes structurés en XML pour chaque compte. Cela rompt 1FN (voir notes plus loin), mais permet une requête spécifique à exécuter avec minimum I/O .
en même temps, en supposant qu'il soit possible de mettre à jour n'importe quel mois avec des insertions, des mises à jour ou des suppressions de documents financiers, la performance des requêtes de mise à jour sur le système pourrait être ralentie par le temps proportionnel à une certaine fonction de n pour chaque mise à jour . (le cas ci-dessus illustre un principe, en réalité, vous ne avoir de meilleures options et l'avantage d'obtenir un minimum I/O apporter de telles pénalités que pour système réaliste qui met à jour les données souvent, vous obtiendriez de mauvaises performances, même pour votre requête ciblée selon le type de charge de travail réelle; peut expliquer plus en détail si vous voulez)
Note: C'est effectivement un exemple trivial et il y a un problème avec la définition de 1FN. Hypothèse selon laquelle le modèle ci-dessus casse 1NF exigence que les valeurs d'un attribut contiennent exactement une valeur du domaine applicable ".
cela vous permet de dire que le domaine du rapport d'attribut est un ensemble de tous les rapports possibles et que de chacun d'eux il y a exactement une valeur et une revendication que 1NF n'est pas cassé (similaire à l'argument que le stockage de mots ne casse pas 1NF même si vous pourriez avoir letters relation quelque part dans votre modèle).
On d'un autre côté, il existe de bien meilleures façons de modéliser ce tableau, ce qui serait plus utile pour un plus large éventail de requêtes (par exemple pour récupérer les soldes pour un seul compte pour tous les mois de l'année). Dans ce cas, vous justifieriez cette amélioration en disant que ce domaine n'est pas dans 1NF.
de toute façon, cela explique pourquoi les gens prétendent que briser NFs pourrait améliorer les performances.
2) rupture 3NF
en supposant tableaux en 3NF
CREATE TABLE `t` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`member_id` int(10) unsigned NOT NULL,
`status` tinyint(3) unsigned NOT NULL,
`amount` decimal(10,2) NOT NULL,
`opening` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `member_id` (`member_id`),
CONSTRAINT `t_ibfk_1` FOREIGN KEY (`member_id`) REFERENCES `m` (`id`) ON DELETE CASCADE ON UPDATE CASCADE
) ENGINE=InnoDB
CREATE TABLE `m` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
avec données d'échantillon (lignes 1M en t, 100k en m)
supposons une requête commune que vous voulez améliorer
mysql> select sql_no_cache m.name, count(*)
from t join m on t.member_id = m.id
where t.id between 100000 and 500000 group by m.name;
+-------+----------+
| name | count(*) |
+-------+----------+
| omega | 11 |
| test | 8 |
| test3 | 399982 |
+-------+----------+
3 rows in set (1.08 sec)
vous pouvez trouver des suggestions pour déplacer l'attribut name dans le tableau m qui casse 3NF (il a un FD: member_id - > nom et member_id n'est pas une clé de t)
après
alter table t add column varchar(255);
update t inner join m on t.member_id = t.id set t.name = m.name;
running
mysql> select sql_no_cache name, count(*)
from t where id
between 100000 and 500000
group by name;
+-------+----------+
| name | count(*) |
+-------+----------+
| omega | 11 |
| test | 8 |
| test3 | 399982 |
+-------+----------+
3 rows in set (0.41 sec)
Note: Le temps d'exécution de la requête ci-dessus est coupé en deux , mais
- la table n'était pas en 5NF/6NF pour commencer
- le test a été fait avec no_sql_cache donc la plupart des mécanismes de cache ont été évités (et dans des situations réelles ils jouent un rôle dans la performance du système)
- la consommation d'espace est augmentée d'environ 9x la taille de la colonne Nom x 100k rangées
- il devrait y avoir déclencheurs sur t pour garder l'intégrité des données, ce qui ralentirait considérablement toutes les mises à jour à nommer et ajouter des vérifications supplémentaires que les inserts dans t devraient passer par
- probablement de meilleurs résultats pourraient être obtenus en abandonnant les clés de Substitution et en passant aux clés naturelles, et / ou en indexant, ou en redessinant vers des NFs plus élevés
la normalisation est la bonne façon à long terme. Mais vous n'avez pas toujours la possibilité de reconcevoir L'ERP de l'entreprise (qui est par exemple déjà seulement la plupart du temps 3NF) - parfois, vous devez accomplir certaines tâches dans les ressources données. Bien sûr, faire cela n'est qu'une "solution" à court terme.
Bas de ligne
je pense que la réponse la plus pertinente à votre question Est que vous trouverez l'industrie et l'éducation en utilisant le terme "dénormalisation" dans
- , au sens strict, pour la rupture de NFs
- lâchement, pour l'introduction de toute insertion, mise à jour et suppression des dépendances (original Codd citation de commentaires sur la normalisation en disant: indésirables (!) Ajouter, Mettre à jour et supprimer des dépendances', voir quelques détails ici )
ainsi, selon une définition stricte, l'agrégation (Tableaux sommaires) n'est pas considérée la dénormalisation et ils peuvent aider beaucoup en termes de performances (comme n'importe quel cache, qui n'est pas perçu comme une dénormalisation).
l'usage vague englobe à la fois la rupture des formes normales et le principe de conception orthogonale , comme dit plus haut.
une autre chose qui pourrait faire la lumière est qu'il y a une différence très importante entre le modèle logique et le " modèle physique .
par exemple, les indices stockent des données redondantes, mais personne ne les considère comme dénormalisées, pas même les gens qui utilisent le terme de manière lâche et il ya deux raisons (connectés) pour cette
- ils ne font pas partie du modèle logique
- ils sont transparents et garantis de ne pas briser l'intégrité de votre modèle""
si vous ne parvenez pas à modéliser votre modèle logique vous finirez avec une base de données incohérente - mauvais types de relations entre vos entités (incapacité de représenter l'espace de problème), des faits contradictoires (capacité de perdre de l'information) et vous devriez employer toutes les méthodes que vous pouvez pour obtenir un modèle logique correct, il est une base pour toutes les applications qui seront construits sur elle.
Normalisation, sémantique orthogonale et claire de vos prédicats, attributs bien définis, correctement les dépendances fonctionnelles identifiées jouent toutes un rôle pour éviter les pièges.
quand il s'agit de l'implémentation physique, les choses se relâchent dans le sens où ok, colonne calculée matérialisée qui dépend de non key pourrait casser 3NF, mais s'il y a des mécanismes qui garantissent la cohérence, il est autorisé dans le modèle physique de la même manière que les index sont autorisés, mais vous devez très soigneusement le justifier parce que normaliser sera produire les mêmes ou de meilleures améliorations dans l'ensemble et aura pas ou moins d'impact négatif et gardera la conception claire (ce qui réduit les coûts de développement et de maintenance de l'application) résultant en des économies que vous pouvez facilement dépenser sur la mise à niveau du matériel pour améliorer la vitesse encore plus que ce qui est atteint avec la rupture NFs.
les deux méthodes les plus populaires pour construire un entrepôt de données (DW) semblent être celles de Bill Inmon et Ralph Kimball.
la méthodologie D'Inmon utilise une approche normalisée, tandis que celle de Kimball utilise une modélisation dimensionnelle -- un schéma stellaire dénormalisé.
les Deux sont bien documentés aux petits détails et les deux ont de nombreuses implémentations réussies. Les deux présentent une "large route bien pavée" vers une destination de DW.
Je ne peux pas commentez sur L'approche 6NF ou sur la modélisation D'ancrage parce que je n'ai jamais vu ou participé à un projet DW utilisant cette méthodologie. Quand il s'agit d'implémentations, j'aime voyager bien testé les chemins de -- mais, c'est juste moi.
donc, pour résumer, devrait-on normaliser ou dénormaliser L'eau potable? Dépend de la méthode que vous choisissez -- simplement en choisir un et de s'y tenir, au moins jusqu'à la fin du projet.
EDIT - un exemple
à l'endroit où je travaille actuellement, nous avions un rapport d'héritage qui a été lancé depuis toujours sur le serveur de production. Pas un simple rapport, mais une collection de 30 sous-rapports envoyés à tout le monde et sa fourmi tous les jours.
récemment, nous avons mis en place un DW. Avec deux serveurs de rapports et un tas de rapports en place, j'espérais qu'on pourrait oublier l'héritage. Mais non, legs de legs, nous avons toujours eu, si nous le voulons, il faut, ne peut pas vivre sans elle, etc.
la chose est que le gâchis d'un script python et SQL a pris huit heures (Oui, e-i-g-h-t heures) à courir chaque jour. Inutile de dire que la base de données et l'application ont été construites au cours des années par quelques lots de développeurs -- donc, pas exactement votre 5NF.
il était temps de recréer l'héritage de la DW. Ok, pour être bref c'est fait et ça prend 3 minutes (t-h-r-E-E minutes) pour le produire, 6 secondes par le sous-rapport. Et j'étais pressé de livrer, donc je n'optimisais même pas toutes les requêtes. C'est un facteur de 8 * 60 / 3 = 160 fois plus rapide -- sans parler des avantages de supprimer un travail de huit heures d'un serveur de production. Je pense que je peux encore me raser une minute ou deux, mais pour l'instant, tout le monde s'en fout.
comme point d'intérêt, j'ai utilisé la méthode de Kimball (modélisation dimensionnelle) pour la DW et tout ce qui est utilisé dans cette histoire est open-source.
C'est ce que tout cela (entrepôt de données) est supposé être, je pense. Est-ce que la méthode utilisée (normalisée ou désormalisée) importe?
EDIT 2
comme point d'intérêt, Bill Inmon a un beau papier écrit sur son site web -- un conte de deux Architectures .
Le problème avec le mot "anormale", c'est qu'il ne précise pas dans quelle direction aller. C'est comme essayer D'aller à San Francisco depuis Chicago en s'éloignant de New York.
un schéma d'étoile ou un schéma de flocon de neige n'est certainement pas normalisé. Et il fonctionne certainement mieux qu'un schéma normalisé dans certains modèles d'utilisation. Mais il y a des cas de dénormalisation où le concepteur ne suivait aucune discipline du tout, mais composait juste tables par intuition. Parfois, ces efforts ne marchent pas.
en bref, ne dénormalisez pas. Ne suivez une discipline de conception différente si vous êtes sûr de ses avantages, et même si elle n'est pas d'accord avec la conception normalisée. Mais n'utilisez pas la dénormalisation comme excuse pour un design au hasard.
La réponse courte est ne permettent pas de résoudre un problème de performances que vous n'avez pas !
comme pour les tables basées sur le temps, le pardigm généralement accepté doit avoir valid_ From et valid_to dates dans chaque rangée. C'est toujours en 3FN, car il ne modifie la sémantique de "c'est la seule et unique verision de cette entité" à "c'est la seule et unique version de cette entité en ce moment "
Simplification:
une base de données OLTP devrait être normalisée (dans la mesure où cela a du sens).
un entrepôt de données OLAP doit être dénormalisé en tableaux de fait et de Dimension (pour minimiser les jointures).