Partage de données entre bases de données SQL
j'essaie de résoudre un problème, que pour une fois, je n'ai pas créé.
je travaille dans un environnement avec de nombreuses applications web soutenues par différentes bases de données sur différents serveurs.
chaque base de données est assez unique dans sa conception et son application, mais il reste encore des données communes dans chacune que j'aimerais faire abstraction. Chaque base de données, par exemple, a une table Fournisseurs, une table utilisateurs, etc...
je voudrais faire un résumé cette donnée commune à une base de données unique, mais encore laisser les autres bases de données se joindre sur ces tables, ont même des clés pour renforcer les contraintes, etc... Je suis dans un environnement MsSql.
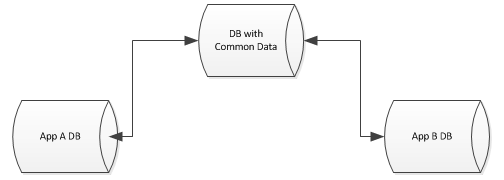
quelles sont les options disponibles? De la façon dont je le vois, j'ai les options suivantes:
- serveurs reliés
- ouvrir une session en lecture seule pour donner accès aux vues
Est-il autre chose à prendre en considération?
5 réponses
il y a plusieurs façons de s'attaquer à ce problème. Je recommande fortement les solutions 1, 2 ou 3 selon vos besoins:
-
réplication transactionnelle : si la base de données commune est l'enregistrement de Compte et que vous voulez fournir des versions en lecture seule des données à des applications distinctes, alors vous pouvez répliquer les tables de base, peut-être même juste les colonnes de base des tables, à chaque serveur. Un avantage de cette approche est que vous pouvez répliquer à autant de bases de données d'abonnés que vous le souhaitez. Cela signifie également que vous pouvez personnaliser quelles tables et quels champs sont disponibles pour les abonnés en fonction de leurs besoins. Ainsi, si une application a besoin de tables d'utilisateurs et non de tables de fournisseurs, alors vous ne vous abonnez qu'aux tables d'utilisateurs. Si un autre n'a besoin que de tableaux fournisseurs et non de tableaux utilisateurs, alors vous pouvez vous abonner uniquement aux tableaux fournisseurs. Un autre avantage est que la réplication reste synchronisée et vous pouvez toujours réinitialiser un abonnement si un problème se présente.
j'ai utilisé la réplication transactionnelle pour sortir plus de 100 tableaux d'un entrepôt de données afin de séparer les applications en aval qui avaient besoin d'accéder à des données agrégées provenant de plusieurs systèmes. Étant donné que notre entrepôt de données a été mis à jour sur une base horaire à partir des sources de données d'expédition de miroirs et de journaux, les applications de production avaient des données provenant de nombreux systèmes dans une fenêtre mobile de 20 à 80 minutes chaque heure.
réplication transactionnelle poste à poste comme type de publication peut être mieux adapté pour le cas d'utilisation que vous avez fourni. Cela peut être vraiment utile si vous voulez déployer des changements de schéma ou de réplication noeud par noeud. La réplication transactionnelle Standard présente certaines limites dans ce domaine.
les types de publication à réplication instantanée ont plus de latence que les publications transactionnelles, mais vous pourriez vouloir considérer si un certain degré de la latence est acceptable.
même si vous avez mentionné que vous êtes un magasin de Serveur SQL de Microsoft, s'il vous plaît garder à l'esprit d'autres RDBMs ont des technologies similaires. Étant donné que vous parlez spécifiquement DE MS SQL Server, Veuillez noter que la réplication transactionnelle vous permet également de vous répliquer dans les bases de données Oracle. Donc, si vous en avez quelques - uns dans votre organisation, cette solution peut encore fonctionner.
un inconvénient à l'utilisation de la réplication transactionnelle est que si vous centralisez le serveur descend vous pouvez commencer à éprouver de la latence avec des données dans les copies en aval des objets répliqués. Si les objets répliqués (articles) sont vraiment grands et que vous avez besoin de réinitialiser une table, alors cela peut prendre beaucoup de temps à faire, aussi.
-
miroirs : si vous voulez rendre la base de données accessible en temps quasi réel sur les serveurs en aval, vous pouvez configurer jusqu'à deux miroirs asychronous. J'ai intégré des données avec une application CRM de cette manière. Toutes les lectures sont venus de jointures vers le miroir. Toutes les Écritures ont été placées dans une file d'attente de messages qui a ensuite appliqué les modifications au serveur central de production. L'inconvénient de cette approche est que vous ne pouvez pas créer plus de 2 asynchrone miroirs. Vous ne voulez pas utiliser de miroirs synchrones à cette fin, sauf si vous prévoyez d'utiliser les miroirs pour la récupération après sinistre, aussi.
-
Systèmes De Messagerie : si vous prévoyez d'avoir de nombreuses applications séparées qui ont besoin de données à partir d'une seule base de données centrale, alors vous pouvez envisager des systèmes de messagerie d'entreprise comme IBM Web Sphere, Microsoft BizTalk, Vitria, TIBCO, etc. Ces applications sont conçues spécifiquement pour résoudre ce problème. Ils ont tendance à être coûteux et encombrants à mettre en œuvre et à maintenir, mais ils peuvent prendre de l'ampleur si vous avez des systèmes distribués à l'échelle mondiale ou des douzaines d'applications distinctes qui ont tous besoin de partager des données un certain degré.
-
serveurs reliés : on dirait que vous avez déjà pensé à celui-ci. Vous pouvez exposer les données via des serveurs liés. Je ne crois pas que ce soit une bonne solution. Si vous voulez vraiment suivre cette voie, alors envisagez de configurer un miroir asynchrone à partir de la base de données centrale vers un autre serveur et ensuite configurer les connexions de serveur liées au miroir. Cela permettra au moins d'atténuer le risque qu'une requête sur le web les applications causeront des problèmes de blocage ou de performance avec votre base de données centrale de production.
IMO, serveurs liés ont tendance à être une méthode dangereuse pour le partage des données pour les applications. Cette approche traite les données comme un citoyen de seconde classe dans votre base de données. Cela conduit à de très mauvaises habitudes de codage, d'autant plus que vos développeurs peuvent travailler sur différents serveurs dans différentes langues avec des méthodes de connexion différentes. Vous ne savez pas si quelqu'un va pour écrire une requête vraiment henious contre vos données de base. Si vous définissez un standard qui nécessite de pousser une copie complète des données partagées vers le serveur non-core, alors vous n'avez pas à vous soucier de savoir si oui ou non un développeur écrit du mauvais code. Au moins du point de vue que leur mauvais code ne va pas gâcher la performance d'autres systèmes bien écrits.
il y a beaucoup, beaucoup de ressources là-bas qui expliquent pourquoi l'utilisation de serveurs liés peut être mauvaise dans ce contexte. Un la liste non-exhaustive des raisons comprend: (a) le compte utilisé pour le serveur lié doit avoir des permissions D'affichage de statistiques DBCC ou les requêtes ne seront pas en mesure de faire usage des statistiques existantes , (b) les indices de requête ne peuvent pas être uesd à moins d'être soumis comme une OPENQUERY, (c) les paramètres ne peuvent pas être passés quand utilisé avec OPENQUERY, (d) le serveur ne dispose pas de statistiques suffisantes sur le serveur lié, par conséquent, crée des plans de requête assez terribles, (e) connectivité réseau des problèmes peuvent entraîner des défaillances, (f) de l'une de ces cinq problèmes de performances , et (g) le redoutable SSPI contexte de l'erreur lors de la tentative d'authentification windows informations d'identification active directory dans un double saut scénario . Les serveurs reliés peuvent être utiles pour certains scénarios spécifiques, mais il n'est pas recommandé de construire un accès à une base de données centrale autour de cette fonctionnalité, bien que cela soit techniquement possible.
-
en Vrac ETL Processus: si un haut degré de latence est acceptable pour les applications web, alors vous pouvez écrire des processus ETL en vrac avec SSIS (lots of good links in this StackOverflow question) qui sont exécutés par des tâches D'agent de serveur SQL pour déplacer des données entre les serveurs. Il existe également d'autres outils ETL alternatifs comme Informatica, Pentaho, etc. utilisez ce qui fonctionne le mieux pour vous.
Ce n'est pas une bonne solution si vous avez besoin d'un faible degré de latence. J'ai utilisé cette solution lors de la synchronisation vers une solution CRM hébergée par une tierce partie pour les champs qui pourraient tolérer une latence élevée. Pour les champs qui ne pouvaient tolérer une latence élevée (données de création de compte de base), nous nous sommes appuyés sur la création de doublons dans le CRM par des appels de service web au point de génération de Compte.
-
Nuit De Sauvegarde et de restauration: si vos données peuvent tolérer des degrés élevés de latence (jusqu'à un jour) et des périodes d'indisponibilité, alors vous pouvez sauvegarder et restaurer la base de données dans les environnements. Ce n'est pas une bonne solution pour les applications web qui nécessitent 100% de temps de fonctionnement. L'idée est que vous prenez une sauvegarde de base, la restaurer à un nom de restauration séparé, puis renommer la base de données originale et la nouvelle dès que le nouveau est prêt à l'emploi. J'ai vu Cela fait pour certaines applications Web internes, mais je ne recommande généralement pas cette approche. C'est mieux adapté à un environnement de développement plus faible, pas à un environnement de production.
-
Log Shipping Secondaries : vous pouvez configurer l'expédition de log entre le primaire et un nombre quelconque de secondaires. Ceci est similaire au processus de sauvegarde et de restauration nocturne, sauf que vous pouvez mettre à jour la base de données plus fréquemment. Dans un cas, cette solution a été utilisée pour exposer des données provenant de l'un de nos principaux systèmes de base pour les utilisateurs en aval en passant entre deux destinataires d'expédition de grumes. Il y avait un autre serveur pointé vers les deux bases de données et basculé entre elles chaque fois que la nouvelle était disponible. Je déteste vraiment cette solution, mais la seule fois où j'ai vu cette mise en œuvre il a répondu aux besoins de l'entreprise.
vous pouvez également envisager l'utilisation de la réplication de serveur SQL intégrée entre le stockage de données commun et app DBs. D'après mon expérience, il est bien adapté pour le transfert de données bidirectionnel, et il ya une instance des tables dans chaque db permettant l'utilisation de clés étrangères (Je ne pense pas que FKs sont possibles via un serveur lié).
il peut y avoir d'autres options, mais pensez que vous êtes la bonne piste pour la meilleure option avec une combinaison de serveurs liés et de vues. Cela pourrait être aussi simple que de créer une nouvelle base de données, d'ajouter deux serveurs liés, de définir vos permissions et ensuite de créer la vue nécessaire.
si vos objectifs sont abstract out this common data to a single database but still let the other databases join on these tables, even have keys to enforce constraints alors cette solution devrait fonctionner très bien.
du côté du bas, vous pouvez rencontrer des problèmes de performance avec serveurs liés, donc si vous prévoyez que la base de données reçoit beaucoup de trafic, alors vous pourriez vouloir regarder dans le déplacement des données réellement en utilisant les méthodes que Doug ou mwebber suggéré.
si vous suivez la route du serveur lié, je vous recommande reading up sur OPENQUERY . Il ya un bon article sur OPENQUERY vs 4 partie identificateurs ici .
regardez le Microsoft Sync Framework . Vous aurez à écrire une application de synchronisation, mais il pourrait vous donner la flexibilité dont vous avez besoin.
je pense que vous devriez avoir un bon regard sur la réplication, comme de nombreuses réponses l'ont indiqué, en particulier dans un environnement high-TPS ou vous voulez cela sur de nombreuses tables. Cependant, je vais vous proposer du code sur la façon dont j'atteins vos objectifs déclarés dans certains de mes systèmes en utilisant des serveurs liés, des synonymes et des contraintes de vérification.
je voudrais abstraire ces données communes à une base de données unique, mais encore laisser les autres bases de données se joindre sur ces tables, ont même des clés pour appliquer les contraintes, etc
vous pouvez configurer une vue ou synonyme dans vos bases de données à une table commune dans un serveur lié (ou autre DB locale). Je préfère les synonymes si la vue avait été select * from table de toute façon.
un synonyme de table vous permettra d'exécuter DML sur l'élément distant si vous avez des permissions.
à ce point, cependant, vous ne pouvez pas avoir une clé étrangère à votre point de vue ou synonyme, mais nous peut accomplir quelque chose de similaire avec une contrainte de vérification.
voyons un peu de code:
create synonym MyCentralTable for MyLinkedServer.MyCentralDB.dbo.MyCentralTable
go
create function dbo.MyLocalTableFkConstraint (
@PK int
)
returns bit
as begin
declare @retVal bit
select @retVal = case when exists (
select null from MyCentralTable where PK = @PK
) then 1 else 0 end
return @retVal
end
go
create table MyLocalTable (
FK int check (dbo.MyLocalTableFKConstraint(FK) = 1)
)
go
-- Will fail: -1 not in MyLinkedServer.MyRemoteDatabase.dbo.MyCentralTable
insert into MyLocalTable select -1
-- Will succeed: RI on a remote table w/o triggers
insert into MyLocalTable select FK from MyCentralTable
bien sûr, il est important de noter que vous n'obtiendrez pas d'erreur si vous supprimez un enregistrement référencé dans votre table centrale.