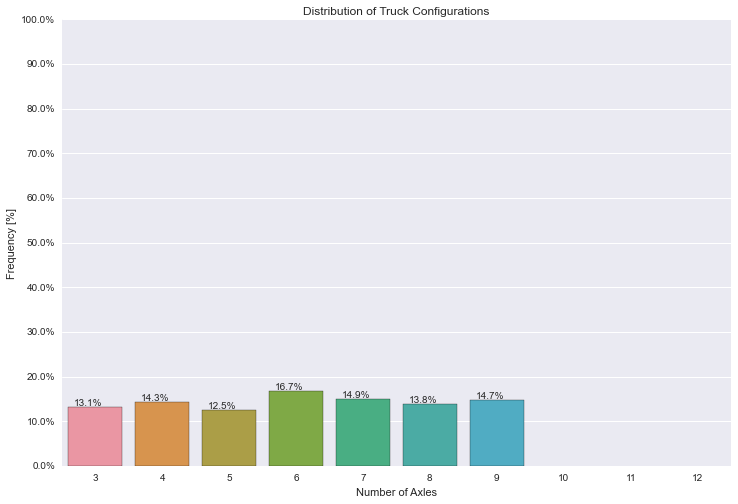
Seaborn: countplot () avec des fréquences
J'ai une base de données Pandas avec une colonne appelée "AXLES", qui peut prendre une valeur entière entre 3-12. J'essaie d'utiliser l'option countplot() de Seaborn pour obtenir le tracé suivant:
- l'axe des y gauche montre les fréquences de ces valeurs apparaissant dans les données. L'axe s'étend [0%-100%], les graduations à 10%.
- l'axe des y à droite montre les nombres réels, les valeurs correspondent aux marques de tique déterminées par l'axe des y à gauche (marquées à chaque 10%.)
- l'axe x montre les catégories pour les placettes à barres[3, 4, 5, 6, 7, 8, 9, 10, 11, 12].
- les annotations en haut des barres indiquent le pourcentage réel de cette catégorie.
le code suivant me donne le tracé ci-dessous, avec des comptes réels, mais je n'ai pas pu trouver un moyen de les convertir en fréquences. Je peux obtenir les fréquences à l'aide de df.AXLES.value_counts()/len(df.index) mais je ne suis pas sûr de la façon de brancher cette information dans Seaborn countplot().
j'ai aussi trouvé un contournez les annotations, mais je ne suis pas sûr que ce soit la meilleure mise en œuvre.
Toute aide serait appréciée!
Merci
plt.figure(figsize=(12,8))
ax = sns.countplot(x="AXLES", data=dfWIM, order=[3,4,5,6,7,8,9,10,11,12])
plt.title('Distribution of Truck Configurations')
plt.xlabel('Number of Axles')
plt.ylabel('Frequency [%]')
for p in ax.patches:
ax.annotate('%{:.1f}'.format(p.get_height()), (p.get_x()+0.1, p.get_height()+50))
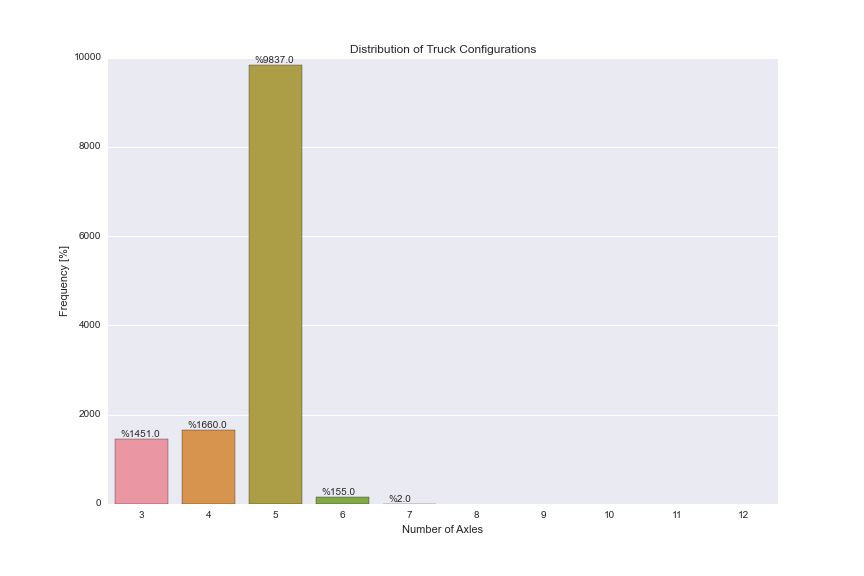
EDIT:
je me suis rapproché de ce dont j'avais besoin avec le code suivant, en utilisant le tracé en barres de Pandas, en laissant tomber Seaborn. J'ai l'impression d'utiliser tant de solutions de rechange, et il doit y avoir un moyen plus facile de le faire. Le problème avec cette approche:
- Il n'y a pas de
ordermot-clé dans la fonction de tracé de barre de Pandas comme l'a fait countplot() de Seaborn, donc je ne peux pas tracer toutes les catégories de 3 à 12 Comme je l'ai fait dans countplot(). Je dois les montrer même s'il n'y a pas de données dans cette catégorie. l'axe des y secondaire abîme les barres et l'annotation pour une raison quelconque (voir les lignes blanches dessinées sur le texte et bars.)
plt.figure(figsize=(12,8)) plt.title('Distribution of Truck Configurations') plt.xlabel('Number of Axles') plt.ylabel('Frequency [%]') ax = (dfWIM.AXLES.value_counts()/len(df)*100).sort_index().plot(kind="bar", rot=0) ax.set_yticks(np.arange(0, 110, 10)) ax2 = ax.twinx() ax2.set_yticks(np.arange(0, 110, 10)*len(df)/100) for p in ax.patches: ax.annotate('{:.2f}%'.format(p.get_height()), (p.get_x()+0.15, p.get_height()+1))
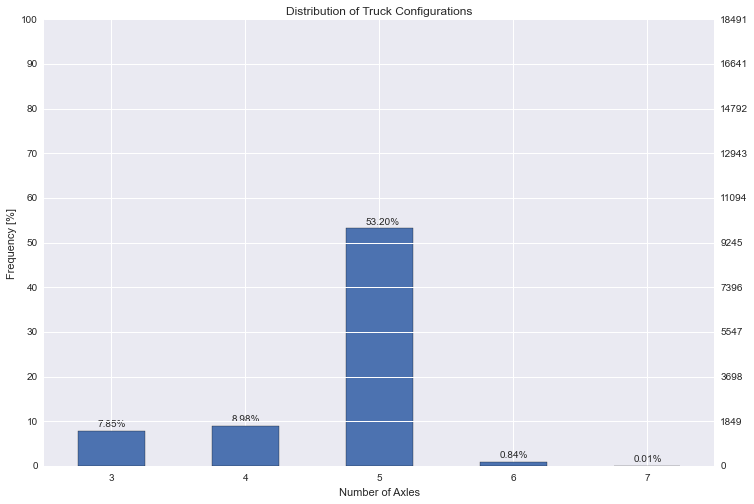
3 réponses
Vous pouvez le faire en faisant un twinx axes pour les fréquences. Vous pouvez commuter les deux axes de y autour de sorte que les fréquences restent sur la gauche et les comptes sur la droite, mais sans avoir à recalculer l'axe des comptes (ici, nous utilisons tick_left() et tick_right() pour déplacer les tiques et set_label_position pour déplacer les étiquettes de l'axe
vous pouvez ensuite définir les tiques en utilisant le matplotlib.ticker module, plus précisément ticker.MultipleLocator et ticker.LinearLocator.
comme pour vos annotations, vous pouvez obtenir les emplacements x et y pour les 4 coins de la barre avec patch.get_bbox().get_points(). Ceci, avec le réglage de l'alignement horizontal et vertical correctement, signifie que vous n'avez pas besoin d'ajouter des décalages arbitraires à l'emplacement de l'annotation.
enfin, vous devez désactiver la grille pour l'axe jumelé, pour éviter que des lignes de grille apparaissent sur le dessus des barres (ax2.grid(None))
voici un script de travail:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import matplotlib.ticker as ticker
# Some random data
dfWIM = pd.DataFrame({'AXLES': np.random.normal(8, 2, 5000).astype(int)})
ncount = len(dfWIM)
plt.figure(figsize=(12,8))
ax = sns.countplot(x="AXLES", data=dfWIM, order=[3,4,5,6,7,8,9,10,11,12])
plt.title('Distribution of Truck Configurations')
plt.xlabel('Number of Axles')
# Make twin axis
ax2=ax.twinx()
# Switch so count axis is on right, frequency on left
ax2.yaxis.tick_left()
ax.yaxis.tick_right()
# Also switch the labels over
ax.yaxis.set_label_position('right')
ax2.yaxis.set_label_position('left')
ax2.set_ylabel('Frequency [%]')
for p in ax.patches:
x=p.get_bbox().get_points()[:,0]
y=p.get_bbox().get_points()[1,1]
ax.annotate('{:.1f}%'.format(100.*y/ncount), (x.mean(), y),
ha='center', va='bottom') # set the alignment of the text
# Use a LinearLocator to ensure the correct number of ticks
ax.yaxis.set_major_locator(ticker.LinearLocator(11))
# Fix the frequency range to 0-100
ax2.set_ylim(0,100)
ax.set_ylim(0,ncount)
# And use a MultipleLocator to ensure a tick spacing of 10
ax2.yaxis.set_major_locator(ticker.MultipleLocator(10))
# Need to turn the grid on ax2 off, otherwise the gridlines end up on top of the bars
ax2.grid(None)
plt.savefig('snscounter.pdf')
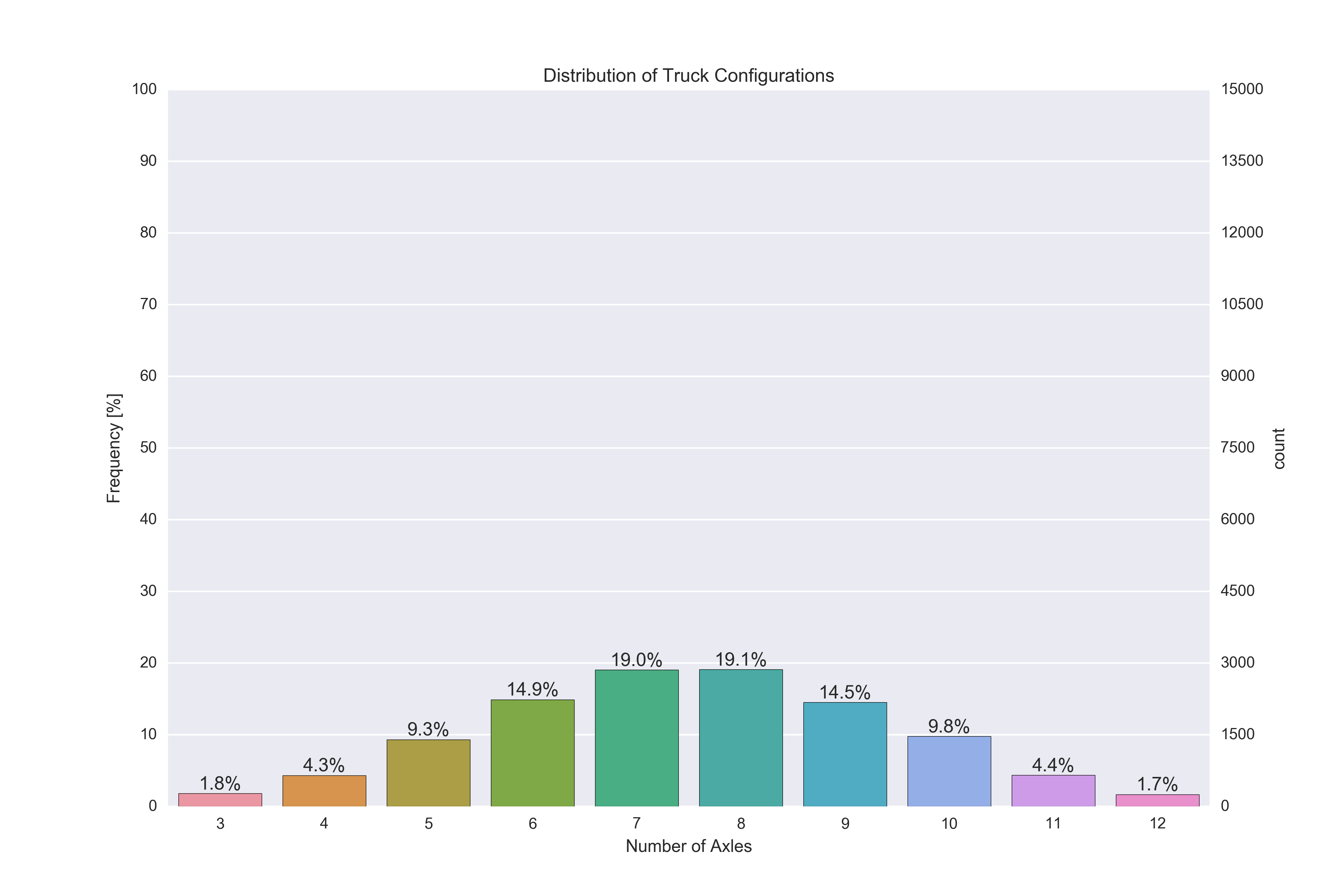
je l'ai eu à travailler à l'aide de core matplotlib's bar de la parcelle. Je n'avais pas vos données évidemment, mais l'adapter à la vôtre devrait être simple.
Approche
j'ai utilisé matplotlibjumeaux de l'axe et représenter graphiquement les données que les bars sur le deuxième Axes objet. Le reste n'est qu'un jeu d'enfant pour corriger les tiques et faire des annotations.
J'espère que cela vous aidera.
Code
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from mpl_toolkits.mplot3d import Axes3D
import seaborn as sns
tot = np.random.rand( 1 ) * 100
data = np.random.rand( 1, 12 )
data = data / sum(data,1) * tot
df = pd.DataFrame( data )
palette = sns.husl_palette(9, s=0.7 )
### Left Axis
# Plot nothing here, autmatically scales to second axis.
fig, ax1 = plt.subplots()
ax1.set_ylim( [0,100] )
# Remove grid lines.
ax1.grid( False )
# Set ticks and add percentage sign.
ax1.yaxis.set_ticks( np.arange(0,101,10) )
fmt = '%.0f%%'
yticks = matplotlib.ticker.FormatStrFormatter( fmt )
ax1.yaxis.set_major_formatter( yticks )
### Right Axis
# Plot data as bars.
x = np.arange(0,9,1)
ax2 = ax1.twinx()
rects = ax2.bar( x-0.4, np.asarray(df.loc[0,3:]), width=0.8 )
# Set ticks on x-axis and remove grid lines.
ax2.set_xlim( [-0.5,8.5] )
ax2.xaxis.set_ticks( x )
ax2.xaxis.grid( False )
# Set ticks on y-axis in 10% steps.
ax2.set_ylim( [0,tot] )
ax2.yaxis.set_ticks( np.linspace( 0, tot, 11 ) )
# Add labels and change colors.
for i,r in enumerate(rects):
h = r.get_height()
r.set_color( palette[ i % len(palette) ] )
ax2.text( r.get_x() + r.get_width()/2.0, \
h + 0.01*tot, \
r'%d%%'%int(100*h/tot), ha = 'center' )
je pense que vous pouvez commencer par définir l'axe des graduations principales manuellement, puis modifier chaque étiquette
dfWIM = pd.DataFrame({'AXLES': np.random.randint(3, 10, 1000)})
total = len(dfWIM)*1.
plt.figure(figsize=(12,8))
ax = sns.countplot(x="AXLES", data=dfWIM, order=[3,4,5,6,7,8,9,10,11,12])
plt.title('Distribution of Truck Configurations')
plt.xlabel('Number of Axles')
plt.ylabel('Frequency [%]')
for p in ax.patches:
ax.annotate('{:.1f}%'.format(100*p.get_height()/total), (p.get_x()+0.1, p.get_height()+5))
#put 11 ticks (therefore 10 steps), from 0 to the total number of rows in the dataframe
ax.yaxis.set_ticks(np.linspace(0, total, 11))
#adjust the ticklabel to the desired format, without changing the position of the ticks.
_ = ax.set_yticklabels(map('{:.1f}%'.format, 100*ax.yaxis.get_majorticklocs()/total))