Scrapy-comment gérer les cookies / sessions
je suis un peu confus quant à la façon dont les cookies fonctionnent avec Scrapy, et comment vous gérez ces cookies.
il s'agit essentiellement d'une version simplifiée de ce que j'essaie de faire:
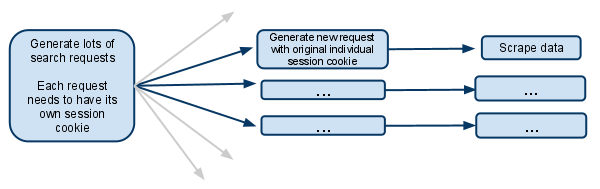
Le fonctionnement du site:
Lorsque vous visitez le site, vous obtenez un cookie de session.
quand vous faites une recherche, le site se souvient de ce que vous avez cherché, donc quand vous faites quelque chose comme aller à la page suivante des résultats, il sait la recherche qu'il a à gérer.
mon script:
Mon araignée a une url de démarrage de searchpage_url
la page de recherche est demandée par parse() et la recherche de la réponse du formulaire est transmis à search_generator()
search_generator()yields beaucoup de requêtes de recherche utilisant FormRequest et la réponse du formulaire de recherche.
chacune de ces demandes de formulaire, et les demandes subséquentes d'enfant doivent avoir sa propre session, donc doit avoir son propre individu cookiejar et son cookie de session.
j'ai vu la section des documents qui parle d'une méta-option qui empêche les cookies d'être fusionnés. Que veut réellement dire? Signifie-t-il l'araignée qui fait la demande a ses propres cookiejar pour le reste de sa vie?
Si les cookies sont ensuite par Spider niveau, alors comment fonctionne lorsque plusieurs araignées sont générés? Est-il possible de faire seulement le premier générateur de requête spawn nouveau spiders et s'assurer qu'à partir de ce moment-là seulement cette araignée traite des demandes futures?
je suppose que je dois désactiver plusieurs demandes simultanées.. dans le cas contraire, une araignée effectuerait des recherches multiples sous le même cookie de session, et les demandes futures ne concerneront que la recherche la plus récente effectuée?
je suis confus, toute clarification serait grandement reçu!
EDIT:
une autre option à laquelle je viens de penser est gérer le cookie de session complètement manuellement, et le transmettre d'une requête à l'autre.
je suppose que cela signifierait désactiver les cookies.. ensuite, il saisit le cookie de session dans la réponse de recherche et le transmet à chaque requête suivante.
Est-ce ce que vous devriez faire dans cette situation?
4 réponses
Trois ans plus tard, je pense que c'est exactement ce que vous cherchez: http://doc.scrapy.org/en/latest/topics/downloader-middleware.html#std:reqmeta-cookiejar
il suffit D'utiliser quelque chose comme ceci dans la méthode start_requests de votre araignée:
for i, url in enumerate(urls):
yield scrapy.Request("http://www.example.com", meta={'cookiejar': i},
callback=self.parse_page)
et rappelez-vous que pour les requêtes suivantes, vous devez explicitement rattacher le cookiejar à chaque fois:
def parse_page(self, response):
# do some processing
return scrapy.Request("http://www.example.com/otherpage",
meta={'cookiejar': response.meta['cookiejar']},
callback=self.parse_other_page)
from scrapy.http.cookies import CookieJar
...
class Spider(BaseSpider):
def parse(self, response):
'''Parse category page, extract subcategories links.'''
hxs = HtmlXPathSelector(response)
subcategories = hxs.select(".../@href")
for subcategorySearchLink in subcategories:
subcategorySearchLink = urlparse.urljoin(response.url, subcategorySearchLink)
self.log('Found subcategory link: ' + subcategorySearchLink), log.DEBUG)
yield Request(subcategorySearchLink, callback = self.extractItemLinks,
meta = {'dont_merge_cookies': True})
'''Use dont_merge_cookies to force site generate new PHPSESSID cookie.
This is needed because the site uses sessions to remember the search parameters.'''
def extractItemLinks(self, response):
'''Extract item links from subcategory page and go to next page.'''
hxs = HtmlXPathSelector(response)
for itemLink in hxs.select(".../a/@href"):
itemLink = urlparse.urljoin(response.url, itemLink)
print 'Requesting item page %s' % itemLink
yield Request(...)
nextPageLink = self.getFirst(".../@href", hxs)
if nextPageLink:
nextPageLink = urlparse.urljoin(response.url, nextPageLink)
self.log('\nGoing to next search page: ' + nextPageLink + '\n', log.DEBUG)
cookieJar = response.meta.setdefault('cookie_jar', CookieJar())
cookieJar.extract_cookies(response, response.request)
request = Request(nextPageLink, callback = self.extractItemLinks,
meta = {'dont_merge_cookies': True, 'cookie_jar': cookieJar})
cookieJar.add_cookie_header(request) # apply Set-Cookie ourselves
yield request
else:
self.log('Whole subcategory scraped.', log.DEBUG)
je pense que l'approche la plus simple serait d'exécuter plusieurs instances de la même araignée en utilisant la requête de recherche comme argument araignée (qui serait reçu dans le constructeur), afin de réutiliser la fonctionnalité de gestion des cookies de Scrapy. Vous aurez donc plusieurs instances spider, chacune rampant une requête de recherche spécifique et ses résultats. Mais vous devez exécuter les araignées vous-même avec:
scrapy crawl myspider -a search_query=something
ou vous pouvez utiliser Scrapyd pour exécuter toutes les araignées à travers le JSON API.
def parse(self, response):
# do something
yield scrapy.Request(
url= "http://new-page-to-parse.com/page/4/",
cookies= {
'h0':'blah',
'taeyeon':'pretty'
},
callback= self.parse
)