Contours De Nuage De Points Dans Matplotlib
j'ai un scatterplot massif (~100,000 points) que je génère en matplotlib. Chaque point a un emplacement dans cet espace x/y, et j'aimerais générer des contours contenant certains centiles du nombre total de points.
y a-t-il une fonction dans matplotlib qui fera cela? J'ai regardé dans contour(), mais je devrais écrire ma propre fonction pour travailler de cette façon.
Merci!
2 réponses
en gros, vous voulez une estimation de la densité. Il y a plusieurs façons de faire cela:
utilisez un histogramme 2D d'une certaine façon (par exemple
matplotlib.pyplot.hist2doumatplotlib.pyplot.hexbin) (vous pouvez aussi afficher les résultats sous forme de contours--utilisez simplementnumpy.histogram2dpuis contour le tableau résultant.)faites une estimation de la densité du grain (KDE) et contourez les résultats. Un KDE est essentiellement un histogramme lissé. Au lieu d'un point tombant dans une corbeille particulière, il ajoute un poids par rapport aux bacs environnants (habituellement en forme de "courbe en cloche"gaussienne).
L'utilisation d'un histogramme 2D est simple et facile à comprendre, mais donne des résultats "blocky".
il y a quelques rides à faire le deuxième "correctement" (c.-à-d. il n'y a pas une seule façon correcte). Je ne vais pas entrer dans les détails ici, mais si vous voulez interpréter les résultats statistiquement, vous devez lire sur elle (en particulier la sélection de bande passante).
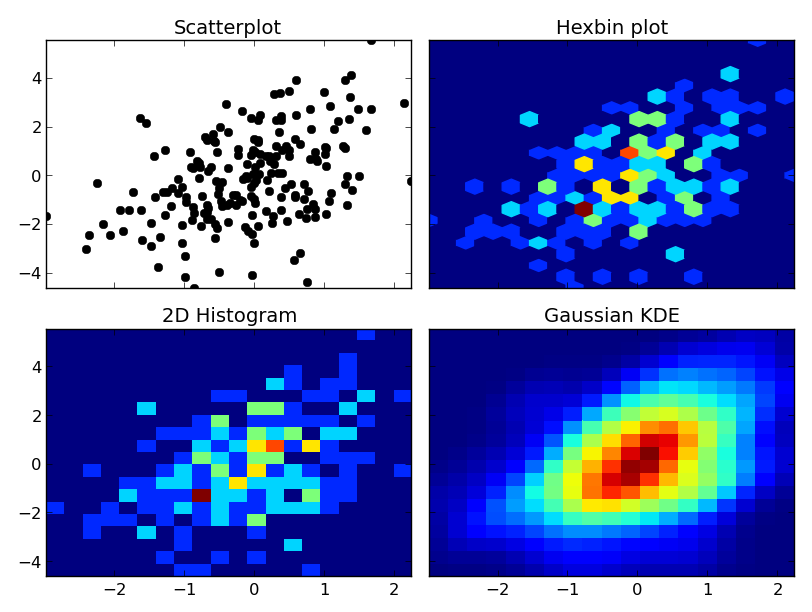
À tout cas, voici un exemple des différences. Je vais tracer chacun d'eux de la même façon, donc je n'utiliserai pas les contours, mais vous pourriez aussi facilement tracer l'histogramme 2D ou le KDE gaussien en utilisant un tracé de contour:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import kde
np.random.seed(1977)
# Generate 200 correlated x,y points
data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200)
x, y = data.T
nbins = 20
fig, axes = plt.subplots(ncols=2, nrows=2, sharex=True, sharey=True)
axes[0, 0].set_title('Scatterplot')
axes[0, 0].plot(x, y, 'ko')
axes[0, 1].set_title('Hexbin plot')
axes[0, 1].hexbin(x, y, gridsize=nbins)
axes[1, 0].set_title('2D Histogram')
axes[1, 0].hist2d(x, y, bins=nbins)
# Evaluate a gaussian kde on a regular grid of nbins x nbins over data extents
k = kde.gaussian_kde(data.T)
xi, yi = np.mgrid[x.min():x.max():nbins*1j, y.min():y.max():nbins*1j]
zi = k(np.vstack([xi.flatten(), yi.flatten()]))
axes[1, 1].set_title('Gaussian KDE')
axes[1, 1].pcolormesh(xi, yi, zi.reshape(xi.shape))
fig.tight_layout()
plt.show()
une mise en garde: avec un très grand nombre de points, scipy.stats.gaussian_kde deviendra très lent. Il est assez facile de l'accélérer en faisant une approximation--il suffit de prendre l'histogramme 2D et flou avec un guassian filtre de bon rayon et covariance. Je peux donner un exemple si vous voulez.
une autre mise en garde: Si vous faites cela dans un système de coordonnées Non cartésien, aucune de ces méthodes ne s'appliquent! Obtenir des estimations de densité sur une coquille Sphérique est un peu plus compliqué.
j'ai la même question. Si vous voulez tracer les contours, qui contiennent une partie des points que vous pouvez utiliser l'algorithme suivant:
créer un histogramme 2d
h2, xedges, yedges = np.histogram2d(X, Y, bibs = [30, 30])
H2 est maintenant la matrice 2d contenant des entiers qui est le nombre de points dans un rectangle
hravel = np.sort(np.ravel(h2))[-1] #all possible cases for rectangles
hcumsum = np.sumsum(hravel)
moche hack,
donnons pour chaque point de la matrice 2d h2 le nombre cumulatif de points pour le rectangle qui contiennent le nombre de points égal ou supérieur à ce que nous analysons actuellement.
hunique = np.unique(hravel)
hsum = np.sum(h2)
for h in hunique:
h2[h2 == h] = hcumsum[np.argwhere(hravel == h)[-1]]/hsum
maintenant tracez le contour pour h2, ce sera le contour qui contient une certaine quantité de tous les points