Enregistrer la sortie PL/pgSQL de PostgreSQL dans un fichier CSV
Quelle est la meilleure façon de sauvegarder les sorties PL/pgSQL à partir d'une base de données PostgreSQL dans un fichier CSV?
J'utilise PostgreSQL 8.4 avec pgAdmin III et le plugin PSQL d'où j'exécute des requêtes.
14 réponses
voulez-vous que le fichier résultant sur le serveur ou sur le client?
Côté Serveur
si vous voulez quelque chose de facile à réutiliser ou à automatiser, vous pouvez utiliser la commande COPY de Postgresql. par exemple
Copy (Select * From foo) To '/tmp/test.csv' With CSV DELIMITER ',';
cette approche fonctionne entièrement sur le serveur distant - il ne peut pas écrire sur votre PC local. Il doit également être exécuté comme un "superutilisateur" Postgrés (normalement appelé "root") parce que Postgres ne peut pas l'empêcher de faire des choses désagréables avec le système de fichiers local de cette machine.
cela ne signifie pas réellement que vous devez être connecté en tant que super-utilisateur (automatisant qui serait un risque de sécurité d'un type différent), parce que vous pouvez utiliser l'option SECURITY DEFINER à CREATE FUNCTION pour faire une fonction qui fonctionne comme si vous étiez un super-utilisateur .
l'essentiel est que votre fonction est là pour effectuer des vérifications supplémentaires, Pas seulement contourner la sécurité-de sorte que vous pourriez écrire une fonction qui exporte les données exactes dont vous avez besoin, ou vous pourriez écrire quelque chose qui peut accepter diverses options tant qu'ils répondent à une liste blanche stricte. Vous devez vérifier deux choses:
- Qui fichiers l'utilisateur doit être autorisé à lire/écrire sur le disque? Cela pourrait être un répertoire particulier, par exemple, et le nom de fichier peut avoir un préfixe approprié ou l'extension.
- Qui tables l'utilisateur doit être capable de lire/écrire dans la base de données? Cela serait normalement défini par
GRANTs dans la base de données, mais la fonction est maintenant en cours d'exécution en tant que super-utilisateur, de sorte que les tables qui seraient normalement" hors limites " sera entièrement accessible. Vous ne voulez probablement pas laisser quelqu'un invoquer votre fonction et ajouter des lignes à la fin de votre table "utilisateurs" ...
j'ai écrit un billet de blog dans le prolongement de cette approche , y compris certains exemples de fonctions d'exportation (ou importer) des fichiers et des tables de réunion, des conditions strictes.
côté Client
l'autre approche est de faire le traitement de fichier du côté du client , c.-à-d. dans votre application ou script. Le serveur Postgres n'a pas besoin de savoir à quel fichier vous copiez, il crache juste les données et le client les met quelque part.
la syntaxe sous-jacente pour cela est la commande COPY TO STDOUT , et les outils graphiques comme pgAdmin l'envelopperont pour vous dans un dialogue agréable.
le psql client en ligne de commande a une "méta-commande" spéciale appelée \copy , qui prend toutes les mêmes options que le" réel " COPY , mais est exécuté à l'intérieur du client:
\copy (Select * From foo) To '/tmp/test.csv' With CSV
notez qu'il n'y a pas de terminaison ; , car les méta-commandes sont terminées par newline, contrairement aux commandes SQL.
à Partir de les docs :
ne pas confondre la copie avec l'instruction psql \copy. \copy appelle COPY FROM STDIN ou COPY TO STDOUT, puis récupère/stocke les données dans un fichier accessible au client psql. Ainsi, le fichier de l'accessibilité et de l'accès les droits dépendent du client plutôt que du serveur lorsque \copy est utilisé.
votre langage de programmation d'application peut ont également un support pour pousser ou récupérer les données, mais vous ne pouvez généralement pas utiliser COPY FROM STDIN / TO STDOUT dans un énoncé SQL standard, parce qu'il n'y a aucun moyen de connecter le flux d'entrée/sortie. Le handler PostgreSQL de PHP ( pas AOP) inclut très basique pg_copy_from et pg_copy_to fonctions qui copient à/à partir d'un tableau PHP, qui peuvent ne pas être efficaces pour les grands ensembles de données.
il y a plusieurs solutions:
1 psql commande
psql -d dbname -t -A -F"," -c "select * from users" > output.csv
cela a le grand avantage que vous pouvez l'utiliser via SSH, comme ssh postgres@host command - vous permettant d'obtenir
2 postgres copy command
COPY (SELECT * from users) To '/tmp/output.csv' With CSV;
3 psql interactif (ou pas)
>psql dbname
psql>\f ','
psql>\a
psql>\o '/tmp/output.csv'
psql>SELECT * from users;
psql>\q
tous peuvent être utilisés dans les scripts, mais Je préfère le #1.
4 pgadmin mais ce n'est pas scriptable.
Dans le terminal (pendant la connexion à la db) de sortie pour le fichier cvs
1) placer le séparateur de champ à ',' :
\f ','
2) Définir le format de sortie non aligné:
\a
3) Afficher uniquement les n-uplets:
\t
4) sortie définie:
\o '/tmp/yourOutputFile.csv'
5) exécutez votre requête:
:select * from YOUR_TABLE
6) Sortie:
\o
vous pourrez alors trouver votre fichier csv à cet endroit:
cd /tmp
copier en utilisant la commande scp ou éditer en utilisant nano:
nano /tmp/yourOutputFile.csv
si vous êtes intéressé par tous les colonnes d'une table particulière avec des en-têtes, vous pouvez utiliser
COPY table TO '/some_destdir/mycsv.csv' WITH CSV HEADER;
c'est un peu plus simple que
COPY (SELECT * FROM table) TO '/some_destdir/mycsv.csv' WITH CSV HEADER;
qui, à ma connaissance, sont équivalents.
j'ai dû utiliser la copie \car j'ai reçu le message d'erreur:
ERROR: could not open file "/filepath/places.csv" for writing: Permission denied
donc j'ai utilisé:
\Copy (Select address, zip From manjadata) To '/filepath/places.csv' With CSV;
et il fonctionne
psql peut le faire pour vous:
edd@ron:~$ psql -d beancounter -t -A -F"," \
-c "select date, symbol, day_close " \
"from stockprices where symbol like 'I%' " \
"and date >= '2009-10-02'"
2009-10-02,IBM,119.02
2009-10-02,IEF,92.77
2009-10-02,IEV,37.05
2009-10-02,IJH,66.18
2009-10-02,IJR,50.33
2009-10-02,ILF,42.24
2009-10-02,INTC,18.97
2009-10-02,IP,21.39
edd@ron:~$
Voir man psql pour obtenir de l'aide sur les options utilisées ici.
dans pgAdmin III il y a une option pour exporter vers le fichier à partir de la fenêtre de requête. Dans le menu principal C'est Query -> Execute to file ou il y a un bouton qui fait la même chose (c'est un triangle vert avec une disquette bleue par opposition au triangle vert simple qui exécute juste la requête). Si vous n'exécutez pas la requête depuis la fenêtre de requête, je ferais ce que IMSoP a suggéré et j'utiliserais la commande Copier.
je travaille sur AWS Redshift, qui ne supporte pas la fonctionnalité COPY TO .
mon outil BI prend en charge les CSVs délimités par tabulation, donc j'ai utilisé ce qui suit:
psql -h dblocation -p port -U user -d dbname -F $'\t' --no-align -c " SELECT * FROM TABLE" > outfile.csv
cette information n'est pas vraiment bien représentée. Comme c'est la deuxième fois que j'ai besoin de dériver ceci, je vais mettre ceci ici pour me rappeler si rien d'autre.
la meilleure façon de faire cela (sortir CSV de postgres) est D'utiliser la commande COPY ... TO STDOUT . Bien que vous ne vouliez pas le faire de la manière indiquée dans les réponses ici. La bonne façon d'utiliser la commande est:
COPY (select id, name from groups) TO STDOUT WITH CSV HEADER
rappelez-vous une seule commande!
C'est idéal pour une utilisation au-dessus de ssh:
$ ssh psqlserver.example.com 'psql -d mydb "COPY (select id, name from groups) TO STDOUT WITH CSV HEADER"' > groups.csv
C'est idéal pour une utilisation à l'intérieur de docker via ssh:
$ ssh pgserver.example.com 'docker exec -tu postgres postgres psql -d mydb -c "COPY groups TO STDOUT WITH CSV HEADER"' > groups.csv
C'est même très bien sur la machine locale:
$ psql -d mydb -c 'COPY groups TO STDOUT WITH CSV HEADER' > groups.csv
ou docker intérieur sur la machine locale?:
docker exec -tu postgres postgres psql -d mydb -c 'COPY groups TO STDOUT WITH CSV HEADER' > groups.csv
ou sur un cluster de kubernetes, en docker, au-dessus de HTTPS??:
kubectl exec -t postgres-2592991581-ws2td 'psql -d mydb -c "COPY groups TO STDOUT WITH CSV HEADER"' > groups.csv
Si polyvalent, beaucoup de virgules!
tu veux bien?
Oui je l'ai fait, voici mes notes:
The COPYses
L'utilisation de /copy exécute efficacement des opérations de fichier sur n'importe quel système sur lequel la commande psql est en cours d'exécution, comme l'utilisateur qui l'exécute 1 . Si vous vous connectez à un serveur distant, il est simple de copier des fichiers de données sur le système en exécutant psql vers/depuis le serveur distant.
COPY exécute les opérations de fichier sur le serveur comme le compte d'utilisateur du processus d'arrière-plan (par défaut postgres ), les chemins de fichier et les permissions sont vérifiés et appliqués en conséquence. Si vous utilisez TO STDOUT , alors les vérifications de permissions de fichiers sont contournées.
ces deux options nécessitent un déplacement de fichier subséquent si psql n'est pas exécuté sur le système où vous voulez que le CSV résultant réside finalement. C'est probablement le cas, dans mon expérience, lorsque vous travaillez surtout avec des serveurs distants.
il est plus complexe de configurer quelque chose comme un tunnel TCP/IP sur SSH vers un système distant pour une sortie CSV simple, mais pour d'autres formats de sortie (binaire) il peut être préférable de /copy sur une connexion tunnel, en exécutant un local psql . Dans le même ordre d'idées, pour les importations importantes, le déplacement du fichier source vers le serveur et l'utilisation de COPY est probablement l'option la plus performante.
PSQL Paramètres
avec les paramètres psql vous pouvez formater la sortie comme CSV mais il y a des inconvénients comme devoir se rappeler de désactiver le pager et ne pas obtenir les en-têtes:
$ psql -P pager=off -d mydb -t -A -F',' -c 'select * from groups;'
2,Technician,Test 2,,,t,,0,,
3,Truck,1,2017-10-02,,t,,0,,
4,Truck,2,2017-10-02,,t,,0,,
Autres Outils
Non, Je veux juste sortir CSV de mon serveur sans compiler et/ou installer un outil.
j'ai écrit un petit outil appelé psql2csv qui encapsule le modèle COPY query TO STDOUT , résultant en CSV approprié. Son interface est similaire à psql .
psql2csv [OPTIONS] < QUERY
psql2csv [OPTIONS] QUERY
la requête est supposée être le contenu de STDIN, s'il est présent, ou le dernier argument. Tous les autres arguments sont transmis à psql sauf ceux-ci:
-h, --help show help, then exit
--encoding=ENCODING use a different encoding than UTF8 (Excel likes LATIN1)
--no-header do not output a header
si vous avez une requête plus longue et que vous aimez utiliser psql, alors mettez votre requête dans un fichier et utilisez la commande suivante:
psql -d my_db_name -t -A -F";" -f input-file.sql -o output-file.csv
j'ai essayé plusieurs choses, mais peu d'entre elles ont pu me donner le csv désiré avec des détails d'en-tête.
VOILÀ CE QUI A MARCHÉ POUR MOI.
psql-d dbame-U username-C "COPY ( SELECT * FROM TABLE ) TO STDOUT WITH CSV HEADER" > OUTPUT_CSV_FILE.csv
JackDB , un client de base de données dans votre navigateur web, rend cela vraiment facile. Surtout si vous êtes sur Heroku.
il vous permet de vous connecter à des bases de données distantes et d'exécuter des requêtes SQL sur elles.
Source jackdb-heroku http://static.jackdb.com/assets/img/blog/jackdb-heroku-oauth-connect.gif
{kind=link}
une fois votre base de données connectée, vous pouvez lancer une requête et exporter vers CSV ou TXT (voir en bas à droite).
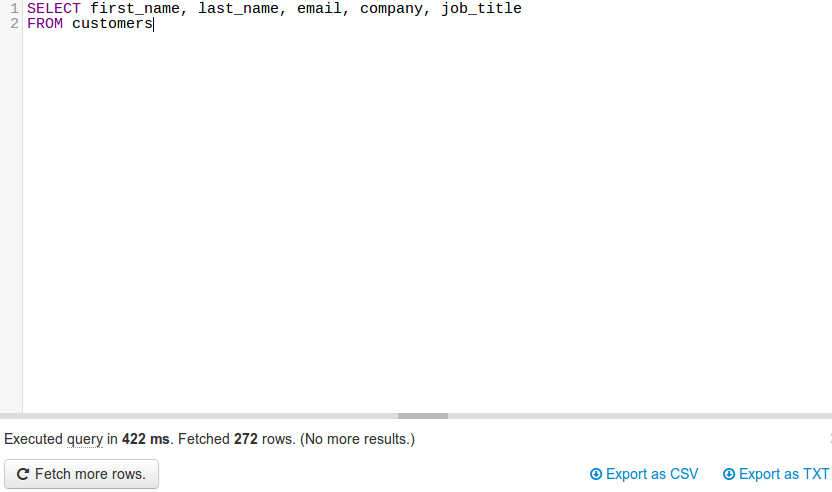
Note: Je ne suis en aucune façon affilié à JackDB. Actuellement, je utiliser leurs services gratuitement et pense que c'est un très bon produit.
import json
cursor = conn.cursor()
qry = """ SELECT details FROM test_csvfile """
cursor.execute(qry)
rows = cursor.fetchall()
value = json.dumps(rows)
with open("/home/asha/Desktop/Income_output.json","w+") as f:
f.write(value)
print 'Saved to File Successfully'