Suppression des soulignements horizontaux
je tente de tirer du texte de quelques centaines de JPG qui contiennent des informations sur les dossiers de peine capitale; Les JPG sont hébergés par le Texas Department of Criminal Justice (TDCJ). Vous trouverez ci-dessous un exemple d'extrait où des renseignements personnels identifiables ont été supprimés.

j'ai identifié les soulignements comme étant l'obstacle à la ROC appropriée -- si je vais dans, capture d'écran d'un sous-fragment de code manuellement et blanc hors lignes, le résultat de l'OCR par pytesseract est très bon. Mais avec les soulignements présents, c'est extrêmement pauvre.
Comment supprimer au mieux ces lignes horizontales? Ce que j'ai essayé:
- a commencé sur la passerelle D'OpenCV doc: extraire les lignes horizontales et verticales en utilisant des opérations morphologiques . Coincé assez rapidement, parce que je sais zéro C++.
- suivi de suppression des lignes horizontales dans l'image - fini avec une chaîne illisible.
- suivi de enlever de longues lignes horizontales/verticales de l'image de bord en utilisant OpenCV - n'a pas été en mesure d'obtenir l'intuition derrière la taille du tableau de zéros ici.
Marquage de cette question avec le c++ dans l'espoir que quelqu'un pourrait aider à traduire L'Étape 5 du docs walkthrough en Python. J'ai essayé un lot de transformations telles que Hugh Line Transform, mais je me sens dans le noir dans une bibliothèque et une zone avec laquelle je n'ai aucune expérience préalable.
import cv2
# Inverted grayscale
img = cv2.imread('rsnippet.jpg', cv2.IMREAD_GRAYSCALE)
img = cv2.bitwise_not(img)
# Transform inverted grayscale to binary
th = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C,
cv2.THRESH_BINARY, 15, -2)
# An alternative; Not sure if `th` or `th2` is optimal here
th2 = cv2.threshold(img, 170, 255, cv2.THRESH_BINARY)[1]
# Create corresponding structure element for horizontal lines.
# Start by cloning th/th2.
horiz = th.copy()
r, c = horiz.shape
# Lost after here - not understanding intuition behind sizing/partitioning
4 réponses
toutes les réponses jusqu'à présent semblent utiliser des opérations morphologiques. Voici quelque chose d'un peu différent. Cela devrait donner de bons résultats si les lignes sont horizontales .
pour ceci j'utilise une partie de votre image d'échantillon montrée ci-dessous.

chargez l'image, convertissez-la en balance grise et inversez-la.
import cv2
import numpy as np
import matplotlib.pyplot as plt
im = cv2.imread('sample.jpg')
gray = 255 - cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
image inversée à l'échelle grise:

si vous scannez une ligne dans cette image inversée, vous verrez que son profil est différent selon la présence ou l'absence d'une ligne.
plt.figure(1)
plt.plot(gray[18, :] > 16, 'g-')
plt.axis([0, gray.shape[1], 0, 1.1])
plt.figure(2)
plt.plot(gray[36, :] > 16, 'r-')
plt.axis([0, gray.shape[1], 0, 1.1])
profil en vert est une rangée où il n'y a pas de soulignement, rouge est pour une rangée avec soulignement. Si vous faites la moyenne de chaque profil, vous verrez que une rouge est plus élevé moyen.
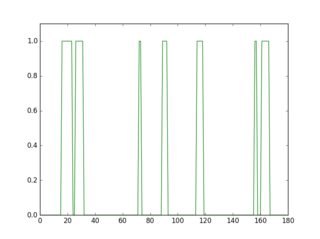
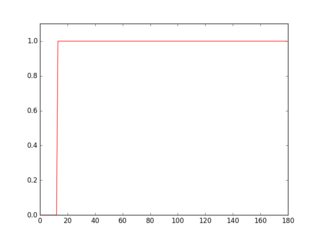
ainsi, en utilisant cette approche, vous pouvez détecter les soulignements et les supprimer.
for row in range(gray.shape[0]):
avg = np.average(gray[row, :] > 16)
if avg > 0.9:
cv2.line(im, (0, row), (gray.shape[1]-1, row), (0, 0, 255))
cv2.line(gray, (0, row), (gray.shape[1]-1, row), (0, 0, 0), 1)
cv2.imshow("gray", 255 - gray)
cv2.imshow("im", im)
Voici les soulignements détectés en rouge, et l'image nettoyée.


sortie tesseract de l'image nettoyée:
Convthed as th(
shot once in the
she stepped fr<
brother-in-lawii
collect on life in
applied for man
to the scheme i|
la raison D'utiliser une partie de l'image doit être claire maintenant. Puisque les informations personnellement identifiables ont été supprimées dans l'image originale, le seuil n'aurait pas fonctionné. Mais cela ne devrait pas être un problème lorsque vous l'appliquez pour le traitement. Parfois, vous devrez ajuster les seuils (16, 0,9).
le résultat ne semble pas très bon avec des parties de la lettres supprimées et quelques lignes à peine visibles. Sera mise à jour si je peux l'améliorer un peu plus.
mise à jour:
Dis quelques améliorations; nettoyage et de lier les parties manquantes des lettres. J'ai commenté le code, donc je crois que le processus est clair. Vous pouvez également vérifier les images intermédiaires pour voir comment il fonctionne. Les résultats sont un peu mieux.


sortie tesseract de l'image nettoyée:
Convicted as th(
shot once in the
she stepped fr<
brother-in-law. ‘
collect on life ix
applied for man
to the scheme i|


sortie tesseract de l'image nettoyée:
)r-hire of 29-year-old .
revolver in the garage ‘
red that the victim‘s h
{2000 to kill her. mum
250.000. Before the kil
If$| 50.000 each on bin
to police.
code python:
import cv2
import numpy as np
import matplotlib.pyplot as plt
im = cv2.imread('sample2.jpg')
gray = 255 - cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
# prepare a mask using Otsu threshold, then copy from original. this removes some noise
__, bw = cv2.threshold(cv2.dilate(gray, None), 128, 255, cv2.THRESH_BINARY or cv2.THRESH_OTSU)
gray = cv2.bitwise_and(gray, bw)
# make copy of the low-noise underlined image
grayu = gray.copy()
imcpy = im.copy()
# scan each row and remove lines
for row in range(gray.shape[0]):
avg = np.average(gray[row, :] > 16)
if avg > 0.9:
cv2.line(im, (0, row), (gray.shape[1]-1, row), (0, 0, 255))
cv2.line(gray, (0, row), (gray.shape[1]-1, row), (0, 0, 0), 1)
cont = gray.copy()
graycpy = gray.copy()
# after contour processing, the residual will contain small contours
residual = gray.copy()
# find contours
contours, hierarchy = cv2.findContours(cont, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_SIMPLE)
for i in range(len(contours)):
# find the boundingbox of the contour
x, y, w, h = cv2.boundingRect(contours[i])
if 10 < h:
cv2.drawContours(im, contours, i, (0, 255, 0), -1)
# if boundingbox height is higher than threshold, remove the contour from residual image
cv2.drawContours(residual, contours, i, (0, 0, 0), -1)
else:
cv2.drawContours(im, contours, i, (255, 0, 0), -1)
# if boundingbox height is less than or equal to threshold, remove the contour gray image
cv2.drawContours(gray, contours, i, (0, 0, 0), -1)
# now the residual only contains small contours. open it to remove thin lines
st = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
residual = cv2.morphologyEx(residual, cv2.MORPH_OPEN, st, iterations=1)
# prepare a mask for residual components
__, residual = cv2.threshold(residual, 0, 255, cv2.THRESH_BINARY)
cv2.imshow("gray", gray)
cv2.imshow("residual", residual)
# combine the residuals. we still need to link the residuals
combined = cv2.bitwise_or(cv2.bitwise_and(graycpy, residual), gray)
# link the residuals
st = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (1, 7))
linked = cv2.morphologyEx(combined, cv2.MORPH_CLOSE, st, iterations=1)
cv2.imshow("linked", linked)
# prepare a msak from linked image
__, mask = cv2.threshold(linked, 0, 255, cv2.THRESH_BINARY)
# copy region from low-noise underlined image
clean = 255 - cv2.bitwise_and(grayu, mask)
cv2.imshow("clean", clean)
cv2.imshow("im", im)
on peut essayer ça.
img = cv2.imread('img_provided_by_op.jpg', 0)
img = cv2.bitwise_not(img)
# (1) clean up noises
kernel_clean = np.ones((2,2),np.uint8)
cleaned = cv2.erode(img, kernel_clean, iterations=1)
# (2) Extract lines
kernel_line = np.ones((1, 5), np.uint8)
clean_lines = cv2.erode(cleaned, kernel_line, iterations=6)
clean_lines = cv2.dilate(clean_lines, kernel_line, iterations=6)
# (3) Subtract lines
cleaned_img_without_lines = cleaned - clean_lines
cleaned_img_without_lines = cv2.bitwise_not(cleaned_img_without_lines)
plt.imshow(cleaned_img_without_lines)
plt.show()
cv2.imwrite('img_wanted.jpg', cleaned_img_without_lines)
Démo

la méthode est basée sur la réponse par Zaw Lin. Il / elle a identifié les lignes dans l'image et a juste fait une soustraction pour se débarrasser d'eux. Toutefois , nous ne pouvons pas juste soustraire lignes ici parce que nous avons des lettres e , t , E , T , - contenant des lignes aussi bien! Si nous soustrayons les lignes horizontales de l'image, e sera presque identique à c . - disparaîtra...
Q: Comment trouver des lignes?
pour trouver des lignes, nous pouvons utiliser la fonction erode . Pour utiliser erode , nous nécessité de définir un noyau. (Vous pouvez penser à un noyau comme une fenêtre / forme qui fonctionne.)
le kernel glisse à travers l'image (comme dans la convolution 2D). un pixel dans l'image originale (soit 1 ou 0) ne sera considéré comme 1 que si tous les pixels le noyau est 1, sinon il est érodé (fait à zéro). -- (Source).
Pour extraire les lignes, nous définissons un noyau, kernel_line comme np.ones((1, 5)) , [1, 1, 1, 1, 1] . Ce noyau va glisser à travers l'image et éroder les pixels qui ont 0 sous le noyau.
plus précisément, alors que le noyau est appliqué à un pixel, il capturera les deux pixels à sa gauche et les deux à sa droite.
[X X Y X X]
^
|
Applied to Y, `kernel_line` captures Y's neighbors. If any of them is not
0, Y will be set to 0.
les lignes horizontales seront préservées sous ce noyau tandis que les pixels qui n'ont pas de voisins horizontaux seront disparaître. C'est ainsi que nous capturons les lignes avec la ligne suivante.
clean_lines = cv2.erode(cleaned, kernel_line, iterations=6)
Q: Comment éviter d'extraire des lignes à l'intérieur de e, E, t, T, et -?
nous allons combiner erosion et dilation avec itération paramètre.
clean_lines = cv2.erode(cleaned, kernel_line, iterations=6)
vous avez peut-être remarqué la partie iterations=6 . L'effet de ce paramètre fera l' partie plate dans E, E, t, T, - disparaître. C'est parce que bien que nous appliquions la même opération plusieurs fois, la partie limite de ces lignes se rétrécirait. (En appliquant le même noyau, seule la partie limite rencontrera 0s et deviendra 0 comme résultat. Nous utilisons cette astuce pour faire disparaître les lignes de ces caractères.
cela, cependant, vient avec un effet secondaire que la longue partie de soulignement que nous voulons nous débarrasser se rétrécit également. Nous pouvons pousser avec dilate !
clean_lines = cv2.dilate(clean_lines, kernel_line, iterations=6)
contrairement à l'érosion qui rétrécit une image, la dilatation rend l'image plus grande. Alors que nous avons toujours le même noyau, kernel_line , si n'importe quelle partie sous le noyau est 1, le pixel cible sera 1. En appliquant cela, la limite repoussera. (La partie dans e, E, t, T, - ne repoussera pas si nous choisissons le paramètre soigneusement tel qu'il disparaît à la partie d'érosion.)
avec ce complément trick, nous pouvons avec succès se débarrasser des lignes sans blesser e, E, t, T, et -.
quelques suggestions:
- étant donné que vous commencez par un JPEG, n'aggravez pas la perte. Enregistrez vos fichiers intermédiaires comme PNGs. Tesseract s'adapte avec ceux qui viennent d'amende.
- l'Échelle de l'image 2x (à l'aide de
cv2.resize) de la remise de Tesseract. - essayez de détecter et d'enlever le soulignement noir. ( cette question pourrait aider). Faire cela tout en préservant les descentes pourrait être délicat.
- Explore les options de ligne de commande de Tesseract, dont il existe de nombreuses (et elles sont horriblement documentées, certaines nécessitant des plongées dans C++ source pour essayer de les comprendre). On dirait que les ligatures causent du chagrin. IIRC (ça fait longtemps), il y a un ou deux endroits qui pourraient aider.
comme la plupart des lignes à détecter dans votre source sont horizontales-longues lignes, similaire à mon autre réponse, qui est trouver une seule couleur, les espaces horizontaux dans l'image
C'est la source de l'image:
Voici mes deux principales étapes pour supprimer la longue ligne horizontale:
- Ne morph-fermer avec de longues noyau de ligne sur l'image grise
kernel = np.ones((1,40), np.uint8)
morphed = cv2.morphologyEx(gray, cv2.MORPH_CLOSE, kernel)
alors, obtenez l'image Morphée contient les longues lignes:

- Inverser l'image Morphée, et ajouter à l'image source:
dst = cv2.add(gray, (255-morphed))
puis obtenir l'image avec de longues lignes supprimé:

C'est assez Simple, non? Et il existe aussi small line segments , je pense qu'il a peu d'effets sur la ROC. Remarquez, presque tous les chars gardent l'original, sauf g , j , p , q , y , Q , peut-être un peu diffente. Mais les outils OCR de mordern tels que Tesseract (avec la technologie LSTM ) a la capacité de traiter avec une telle confusion simple.
0123456789abcdef g hi j klmno pq rstuvwx y zABCDEFGHIJKLMNOP Q RSTUVWXYZ
code Total pour sauvegarder l'image enlevée comme line_removed.png :
#!/usr/bin/python3
# 2018.01.21 16:33:42 CST
import cv2
import numpy as np
## Read
img = cv2.imread("img04.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
## (1) Create long line kernel, and do morph-close-op
kernel = np.ones((1,40), np.uint8)
morphed = cv2.morphologyEx(gray, cv2.MORPH_CLOSE, kernel)
cv2.imwrite("line_detected.png", morphed)
## (2) Invert the morphed image, and add to the source image:
dst = cv2.add(gray, (255-morphed))
cv2.imwrite("line_removed.png", dst)
Update @ 2018.01.23 13 :15: 15 CST:
Tesseract est un outil puissant pour faire de l'OCR. Aujourd'hui, j'installe le Tesseract-4.0 et le pytesseract. Puis je fais ocr en utilisant pytesseract sur le mon résultat line_removed.png .
import cv2
import pytesseract
img = cv2.imread("line_removed.png")
print(pytesseract.image_to_string(img, lang="eng"))
C'est la reuslt, bien pour moi.
Convicted as the triggerman in the murder—for—hire of 29—year—old .
shot once in the head with a 357 Magnum revolver in the garage of her home at ..
she stepped from her car. Police discovered that the victim‘s husband,
brother—in—law, _ ______ paid _ ,000 to kill her, apparently so .. _
collect on life insurance policies totaling 0,000. Before the killing, .
applied for additional life insurance policies of 0,000 each on himself and his wife
to the scheme in three different statements to police.
was
and
could
had also
. confessed