Supprimer les lignes avec tout ou partie des NAs (valeurs manquantes) dans les données.cadre
j'aimerais supprimer les lignes dans ce cadre de données que:
a) contenir NA s à travers toutes les colonnes. ci-dessous est mon exemple de base de données.
gene hsap mmul mmus rnor cfam
1 ENSG00000208234 0 NA NA NA NA
2 ENSG00000199674 0 2 2 2 2
3 ENSG00000221622 0 NA NA NA NA
4 ENSG00000207604 0 NA NA 1 2
5 ENSG00000207431 0 NA NA NA NA
6 ENSG00000221312 0 1 2 3 2
en gros, j'aimerais obtenir une base de données comme celle-ci.
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
6 ENSG00000221312 0 1 2 3 2
b) contenir NA s dans seulement certaines colonnes , donc je peux aussi obtenir ce résultat:
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
4 ENSG00000207604 0 NA NA 1 2
6 ENSG00000221312 0 1 2 3 2
15 réponses
vérifier aussi complete.cases :
> final[complete.cases(final), ]
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
6 ENSG00000221312 0 1 2 3 2
na.omit est plus juste de retirer tous les NA . complete.cases permet la sélection partielle en incluant seulement certaines colonnes de la dataframe:
> final[complete.cases(final[ , 5:6]),]
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
4 ENSG00000207604 0 NA NA 1 2
6 ENSG00000221312 0 1 2 3 2
votre solution ne peut pas fonctionner. Si vous insistez pour utiliser is.na , alors vous devez faire quelque chose comme:
> final[rowSums(is.na(final[ , 5:6])) == 0, ]
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
4 ENSG00000207604 0 NA NA 1 2
6 ENSG00000221312 0 1 2 3 2
mais utiliser complete.cases est beaucoup plus clair et plus rapide.
Essayer na.omit(your.data.frame) . Pour ce qui est de la deuxième question, essayez de l'afficher comme une autre question (pour plus de clarté).
je préfère la manière suivante pour vérifier si les lignes contiennent un NAs:
row.has.na <- apply(final, 1, function(x){any(is.na(x))})
renvoie un vecteur logique avec des valeurs indiquant S'il y a des NA dans une rangée. Vous pouvez l'utiliser pour voir combien de lignes vous devrez laisser tomber:
sum(row.has.na)
et finissent par
final.filtered <- final[!row.has.na,]
pour filtrer les lignes avec une certaine partie du NAs, cela devient un peu plus délicat (par exemple,vous pouvez alimenter 'final [, 5:6]' pour "appliquer"). En général, la solution de Joris Meys semble plus élégante.
si vous aimez les pipes ( %>% ), tidyr 's nouveau drop_na est votre ami:
library(tidyr)
df %>% drop_na()
# gene hsap mmul mmus rnor cfam
# 2 ENSG00000199674 0 2 2 2 2
# 6 ENSG00000221312 0 1 2 3 2
df %>% drop_na(rnor, cfam)
# gene hsap mmul mmus rnor cfam
# 2 ENSG00000199674 0 2 2 2 2
# 4 ENSG00000207604 0 NA NA 1 2
# 6 ENSG00000221312 0 1 2 3 2
une autre option si vous voulez plus de contrôle sur la façon dont les lignes sont jugées invalides est
final <- final[!(is.na(final$rnor)) | !(is.na(rawdata$cfam)),]
en utilisant ce qui précède, ceci:
gene hsap mmul mmus rnor cfam
1 ENSG00000208234 0 NA NA NA 2
2 ENSG00000199674 0 2 2 2 2
3 ENSG00000221622 0 NA NA 2 NA
4 ENSG00000207604 0 NA NA 1 2
5 ENSG00000207431 0 NA NA NA NA
6 ENSG00000221312 0 1 2 3 2
devient:
gene hsap mmul mmus rnor cfam
1 ENSG00000208234 0 NA NA NA 2
2 ENSG00000199674 0 2 2 2 2
3 ENSG00000221622 0 NA NA 2 NA
4 ENSG00000207604 0 NA NA 1 2
6 ENSG00000221312 0 1 2 3 2
...où seule la ligne 5 est supprimée puisqu'il s'agit de la seule ligne contenant des NAs pour rnor et cfam . La logique booléenne peut alors être modifiée pour s'adapter à des exigences spécifiques.
si vous voulez contrôler combien de NAs sont valides pour chaque ligne, essayez cette fonction. Pour de nombreux ensembles de données d'enquête, un trop grand nombre de réponses à des questions Vierges peut ruiner les résultats. Ils sont donc supprimés après un certain seuil. Cette fonction vous permettra de choisir combien de NAs la ligne peut avoir avant d'être supprimée:
delete.na <- function(DF, n=0) {
DF[rowSums(is.na(DF)) <= n,]
}
par défaut, il éliminera tous les NAs:
delete.na(final)
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
6 ENSG00000221312 0 1 2 3 2
ou préciser le nombre maximum de NAs permis:
delete.na(final, 2)
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
4 ENSG00000207604 0 NA NA 1 2
6 ENSG00000221312 0 1 2 3 2
renvoie les lignes qui ont au moins une valeur non-NA.
final[rowSums(is.na(final))<length(final),]
ceci retournera les lignes qui ont au moins deux valeurs non-NA.
final[rowSums(is.na(final))<(length(final)-1),]
en utilisant le paquet dplyr nous pouvons filtrer NA comme suit:
dplyr::filter(df, !is.na(columnname))
nous pouvons également utiliser la fonction de sous-ensemble pour cela.
finalData<-subset(data,!(is.na(data["mmul"]) | is.na(data["rnor"])))
cela ne donnera que les lignes qui n'ont pas de NA à la fois dans mmul et rnor
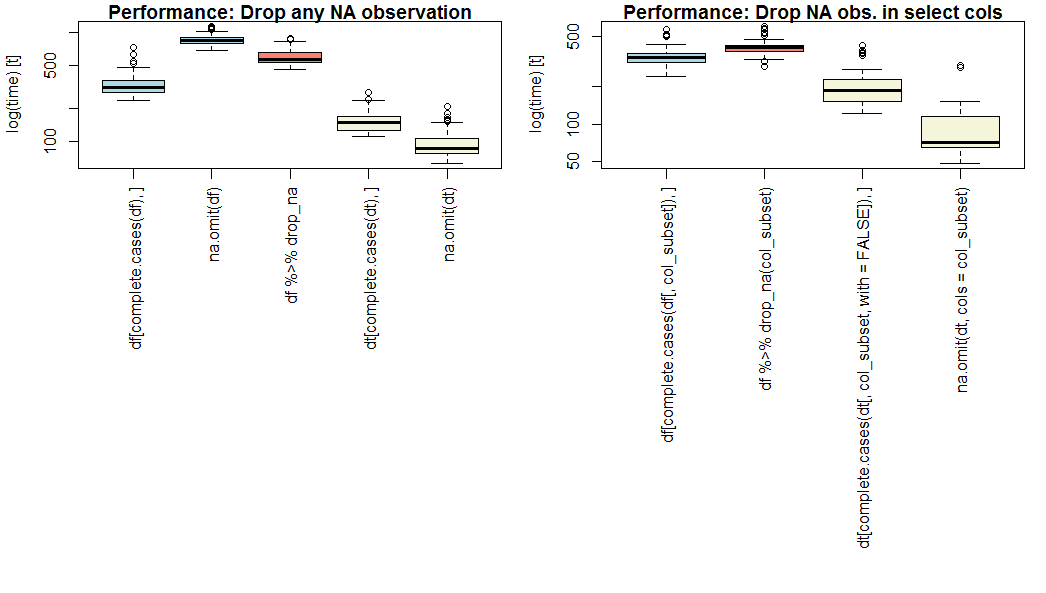
si la performance est une priorité, utiliser data.table et na.omit() avec param facultatif cols= .
na.omit.data.table est le plus rapide sur mon benchmark (voir ci-dessous), que ce soit pour toutes les colonnes ou pour les colonnes sélectionnées (OP question part 2).
Si vous ne voulez pas utiliser data.table , utilisez complete.cases() .
sur une vanille data.frame , complete.cases est plus rapide que na.omit() ou dplyr::drop_na() . Notez que na.omit.data.frame ne supporte pas cols= .
résultat de référence
Voici une comparaison des méthodes de base (bleu), dplyr (rose), et data.table (jaune) pour laisser tomber ou choisir des observations manquantes, sur un ensemble de données fictives de 1 million d'observations de 20 variables numériques avec une probabilité indépendante de 5% d'être manquant, et un sous-ensemble de 4 variables pour la partie 2.
vos résultats peuvent varier en fonction de la longueur, la largeur et la rareté de votre ensemble de données particulier.
note échelle logarithmique sur l'axe Y.
Référence de script
#------- Adjust these assumptions for your own use case ------------
row_size <- 1e6L
col_size <- 20 # not including ID column
p_missing <- 0.05 # likelihood of missing observation (except ID col)
col_subset <- 18:21 # second part of question: filter on select columns
#------- System info for benchmark ----------------------------------
R.version # R version 3.4.3 (2017-11-30), platform = x86_64-w64-mingw32
library(data.table); packageVersion('data.table') # 1.10.4.3
library(dplyr); packageVersion('dplyr') # 0.7.4
library(tidyr); packageVersion('tidyr') # 0.8.0
library(microbenchmark)
#------- Example dataset using above assumptions --------------------
fakeData <- function(m, n, p){
set.seed(123)
m <- matrix(runif(m*n), nrow=m, ncol=n)
m[m<p] <- NA
return(m)
}
df <- cbind( data.frame(id = paste0('ID',seq(row_size)),
stringsAsFactors = FALSE),
data.frame(fakeData(row_size, col_size, p_missing) )
)
dt <- data.table(df)
par(las=3, mfcol=c(1,2), mar=c(22,4,1,1)+0.1)
boxplot(
microbenchmark(
df[complete.cases(df), ],
na.omit(df),
df %>% drop_na,
dt[complete.cases(dt), ],
na.omit(dt)
), xlab='',
main = 'Performance: Drop any NA observation',
col=c(rep('lightblue',2),'salmon',rep('beige',2))
)
boxplot(
microbenchmark(
df[complete.cases(df[,col_subset]), ],
#na.omit(df), # col subset not supported in na.omit.data.frame
df %>% drop_na(col_subset),
dt[complete.cases(dt[,col_subset,with=FALSE]), ],
na.omit(dt, cols=col_subset) # see ?na.omit.data.table
), xlab='',
main = 'Performance: Drop NA obs. in select cols',
col=c('lightblue','salmon',rep('beige',2))
)
pour votre première question, j'ai un code qui me convient pour me débarrasser de tous les NAs. Merci pour @Gregor pour le rendre plus simple.
final[!(rowSums(is.na(final))),]
pour la deuxième question, le code n'est qu'une alternance de la solution précédente.
final[as.logical((rowSums(is.na(final))-5)),]
notez que le -5 est le nombre de colonnes dans vos données. Cela éliminera les lignes avec tous les NAs, puisque les rowSums s'additionnent à 5 et deviennent des zéros après soustraction. Cette fois, comme.logique est nécessaire.
je suis un synthétiseur:). Ici j'ai combiné les réponses dans une fonction:
#' keep rows that have a certain number (range) of NAs anywhere/somewhere and delete others
#' @param df a data frame
#' @param col restrict to the columns where you would like to search for NA; eg, 3, c(3), 2:5, "place", c("place","age")
#' \cr default is NULL, search for all columns
#' @param n integer or vector, 0, c(3,5), number/range of NAs allowed.
#' \cr If a number, the exact number of NAs kept
#' \cr Range includes both ends 3<=n<=5
#' \cr Range could be -Inf, Inf
#' @return returns a new df with rows that have NA(s) removed
#' @export
ez.na.keep = function(df, col=NULL, n=0){
if (!is.null(col)) {
# R converts a single row/col to a vector if the parameter col has only one col
# see https://radfordneal.wordpress.com/2008/08/20/design-flaws-in-r-2-%E2%80%94-dropped-dimensions/#comments
df.temp = df[,col,drop=FALSE]
} else {
df.temp = df
}
if (length(n)==1){
if (n==0) {
# simply call complete.cases which might be faster
result = df[complete.cases(df.temp),]
} else {
# credit: http://stackoverflow.com/a/30461945/2292993
log <- apply(df.temp, 2, is.na)
logindex <- apply(log, 1, function(x) sum(x) == n)
result = df[logindex, ]
}
}
if (length(n)==2){
min = n[1]; max = n[2]
log <- apply(df.temp, 2, is.na)
logindex <- apply(log, 1, function(x) {sum(x) >= min && sum(x) <= max})
result = df[logindex, ]
}
return(result)
}
en supposant que dat soit votre dataframe, le résultat attendu peut être obtenu en utilisant
1. rowSums
> dat[!rowSums((is.na(dat))),]
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
6 ENSG00000221312 0 1 2 3 2
2. lapply
> dat[!Reduce('|',lapply(dat,is.na)),]
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
6 ENSG00000221312 0 1 2 3 2
delete.dirt <- function(DF, dart=c('NA')) {
dirty_rows <- apply(DF, 1, function(r) !any(r %in% dart))
DF <- DF[dirty_rows, ]
}
mydata <- delete.dirt(mydata)
supprime toutes les lignes de la base de données qui a ' NA ' dans n'importe quelle colonne et renvoie les données résultantes. Si vous voulez vérifier plusieurs valeurs comme NA et ? changer dart=c('NA') dans la fonction param à dart=c('NA', '?')
à mon avis, cela pourrait être résolu de façon plus élégante de cette façon
m <- matrix(1:25, ncol = 5)
m[c(1, 6, 13, 25)] <- NA
df <- data.frame(m)
library(dplyr)
df %>%
filter_all(any_vars(is.na(.)))
#> X1 X2 X3 X4 X5
#> 1 NA NA 11 16 21
#> 2 3 8 NA 18 23
#> 3 5 10 15 20 NA