Regex sélectionner tout le texte entre les balises
Quelle est la meilleure façon de sélectionner tout le texte entre 2 balises - ex: le texte entre toutes les balises 'pre' sur la page.
13 réponses
vous pouvez utiliser "<pre>(.*?)</pre>" , (en remplaçant pre par n'importe quel texte que vous voulez) et extraire le premier groupe (pour des instructions plus spécifiques spécifiez une langue) mais cela suppose la notion simpliste que vous avez HTML très simple et valide.
comme d'autres commentateurs l'ont suggéré, si vous faites quelque chose de complexe, utilisez un analyseur HTML.
peut être remplie sur une autre ligne. C'est pourquoi \n doit être ajouté.
<PRE>(.|\n)*?<\/PRE>
C'est ce que j'utiliserais.
(?<=(<pre>))(\w|\d|\n|[().,\-:;@#$%^&*\[\]"'+–/\/®°⁰!?{}|`~]| )+?(?=(</pre>))
fondamentalement, ce qu'il fait est:
(?<=(<pre>)) la sélection doit être préparée avec <pre> tag
(\w|\d|\n|[().,\-:;@#$%^&*\[\]"'+–/\/®°⁰!?{}|~]| ) C'est juste une expression régulière je veux appliquer. Dans ce cas, il sélectionne la lettre ou le chiffre ou le caractère newline ou certains caractères spéciaux énumérés dans l'exemple entre crochets. Le caractère de la pipe | signifie simplement ou .
+? plus les états de caractères pour sélectionner un ou plusieurs de l'ordre ci - dessus n'a pas d'importance. point d'interrogation modifie le comportement par défaut de "gourmand" à "moins gourmand'.
(?=(</pre>)) sélection doivent être annexés par le <pre> tag
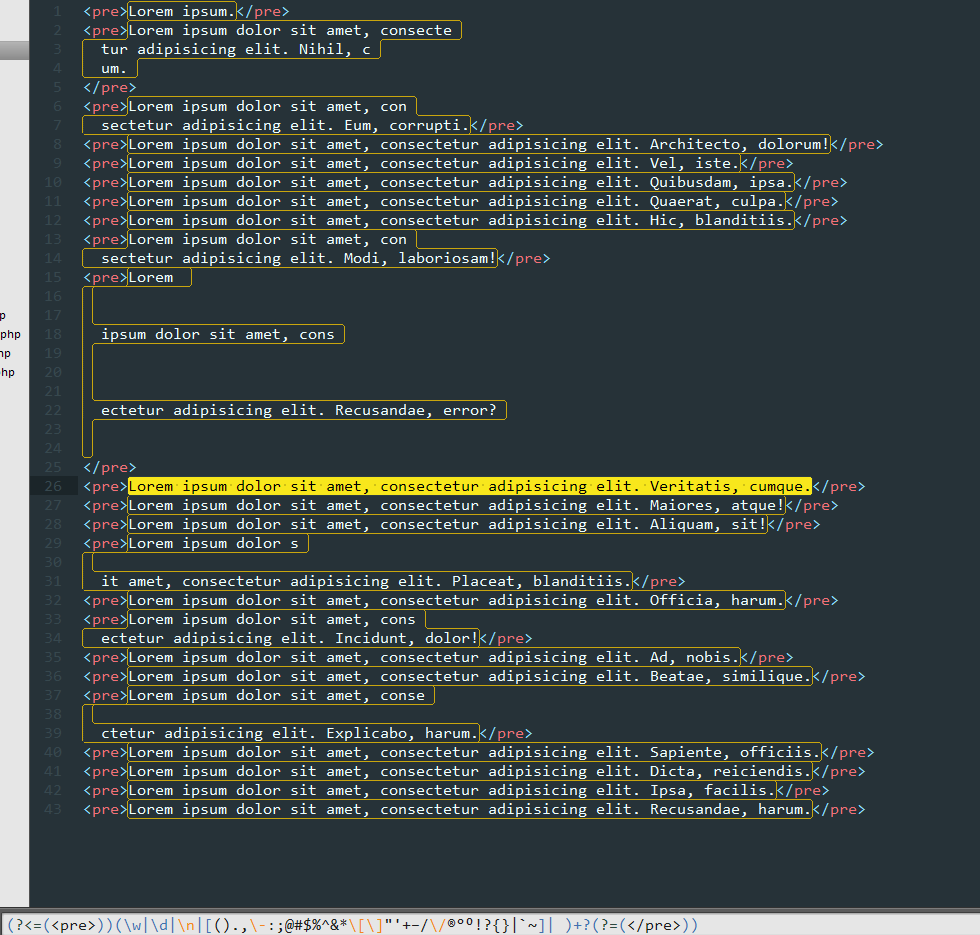
selon votre cas d'utilisation vous pourriez avoir besoin d'ajouter des modificateurs comme ( i ou m )
- i - insensible à la casse
- m - recherche multi-ligne
ici j'ai effectué cette recherche en texte Sublime donc je n'ai pas eu à utiliser de modificateurs dans mon regex.
Javascript ne supporte pas lookbehind
l'exemple ci-dessus devrait fonctionner correctement avec des langages tels que PHP, Perl, Java ...
Javascript, cependant, ne supporte pas lookbehind donc nous devons oublier d'utiliser (?<=(<pre>)) et chercher une sorte de solution. Peut-être simplement retirer les quatre premiers caractères de notre résultat pour chaque sélection comme ici
Regex match de texte entre les balises
regardez aussi la DOCUMENTATION REGEX JAVASCRIPT pour Non-capturing parentheseses
utilisez le modèle ci-dessous pour obtenir le contenu entre les éléments. Remplacez [tag] par l'élément dont vous souhaitez extraire le contenu.
<[tag]>(.+?)</[tag]>
parfois tags auront des attributs , comme anchor tag ayant href , puis utiliser le modèle ci-dessous.
<[tag][^>]*>(.+?)</[tag]>
Vous ne devriez pas être en train d'essayer de parser du html avec regexes voir cette question et comment il s'est avéré.
dans les termes les plus simples, html n'est pas un langage régulier de sorte que vous ne pouvez pas entièrement analyser est avec des expressions régulières.
ayant dit que vous pouvez analyser des sous-ensembles de html quand il n'y a pas de tags similaires imbriqués. Aussi longtemps que quelque chose entre et n'est pas cette étiquette elle-même, cela fonctionnera:
preg_match("/<([\w]+)[^>]*>(.*?)<\/>/", $subject, $matches);
$matches = array ( [0] => full matched string [1] => tag name [2] => tag content )
Une meilleure idée est d'utiliser un analyseur, comme le DOMDocument natif, pour charger votre html, puis sélectionner votre étiquette et obtenir le html intérieur qui pourrait ressembler à quelque chose comme ceci:
$obj = new DOMDocument();
$obj -> load($html);
$obj -> getElementByTagName('el');
$value = $obj -> nodeValue();
et comme il s'agit d'un analyseur approprié, il sera capable de traiter les étiquettes de nidification, etc.
essayez ceci....
(?<=\<any_tag\>)(\s*.*\s*)(?=\<\/any_tag\>)
var str = "Lorem ipsum <pre>text 1</pre> Lorem ipsum <pre>text 2</pre>";
str.replace(/<pre>(.*?)<\/pre>/g, function(match, g1) { console.log(g1); });depuis la réponse acceptée est sans code javascript, ajoutant que:
pour exclure les étiquettes délimitantes:
"(?<=<pre>)(.*?)(?=</pre>)"
vous pouvez utiliser Pattern pattern = Pattern.compile( "[^<'tagname'/>]" );
j'utilise cette solution:
preg_match_all( '/<((?!<)(.|\n))*?\>/si', $content, $new);
var_dump($new);
cela semble être l'expression régulière la plus simple de tout ce que j'ai trouvé
(?:<TAG>)([\s\S]*)(?:<\/TAG>)
- Exclure la balise d'ouverture
(?:<TAG>)dans les matchs - Inclure n'importe quel espace ou non les espaces
([\s\S]*)dans les matchs - exclure l'étiquette de fermeture
(?:<\/TAG>)des allumettes
<pre>([\r\n\s]*(?!<\w+.*[\/]*>).*[\r\n\s]*|\s*[\r\n\s]*)<code\s+(?:class="(\w+|\w+\s*.+)")>(((?!<\/code>)[\s\S])*)<\/code>[\r\n\s]*((?!<\w+.*[\/]*>).*|\s*)[\r\n\s]*<\/pre>