Condition de course sur x86
Quelqu'un Pourrait-il expliquer cette déclaration:
shared variables
x = 0, y = 0
Core 1 Core 2
x = 1; y = 1;
r1 = y; r2 = x;
Comment est-il possible d'avoir r1 == 0 et r2 == 0 sur des processeurs x86?
Source "le langage de la concurrence" par Bartosz Milewski .
3 réponses
Le problème peut survenir en raison d'optimisations impliquant réorganisation des instructions . En d'autres termes, les deux processeurs peuvent assigner r1 et r2 avant d'assigner des variables x et y, s'ils constatent que cela donnerait de meilleures performances. Cela peut être résolu en ajoutant une barrière de mémoire , qui imposerait la contrainte d'ordre.
Pour citer le diaporama que vous avez mentionné dans votre message:
Multicores/langues modernes pause cohérence séquentielle .
En ce qui concerne l'architecture x86, la meilleure ressource à lire est Intel® 64 et IA-32 Architectures Software Developer's Manual (Chapitre 8.2 Memory Ordering). Les Sections 8.2.1 et 8.2.2 décrivent l'ordre de mémoire mis en œuvre par Intel486, Pentium, Intel Core 2 Duo, Intel Atom, Intel Core Duo, Pentium 4, Intel Xeon, et les processeurs de la famille P6: un modèle de mémoire appelé Processeur ordonnant , par opposition à ordre du programme (strong ordering ) de l'ancienne architecture Intel386 (où les instructions de lecture et d'écriture étaient toujours émises dans l'ordre dans lequel elles apparaissaient dans le flux d'instructions).
, Le manuel décrit de nombreuses garanties d'organisation du processeur de commande de la mémoire de modèle (par exemple Charges ne sont pas réorganisées avec d'autres charges, les Magasins ne sont pas réorganisées avec d'autres magasins, les Magasins ne sont pas réorganisées avec les anciennes charges, etc.), mais aussi décrit la règle de réorganisation autorisée qui provoque la condition de concurrence dans le post de L'OP:
8.2.3.4 les charges peuvent être réorganisées avec des magasins antérieurs à différents Lieux
D'autre part, si l'ordre d'origine des instructions a été changé:
shared variables
x = 0, y = 0
Core 1 Core 2
r1 = y; r2 = x;
x = 1; y = 1;
Dans ce cas, le processeur garantit que la situation r1 = 1 et r2 = 1 n'est pas autorisée (en raison de 8.2.3.3 les magasins ne sont pas réorganisés avec une charge antérieure garantie), ce qui signifie que ceux-ci les instructions ne seraient jamais réorganisées dans des cœurs individuels.
Pour comparer cela avec différentes architectures, consultez cet article: ordre de la mémoire dans les microprocesseurs modernes (cette image spécifiquement). Vous pouvez voir Qu'Itanium (IA-64) fait encore plus de réorganisation que L'architecture IA-32.
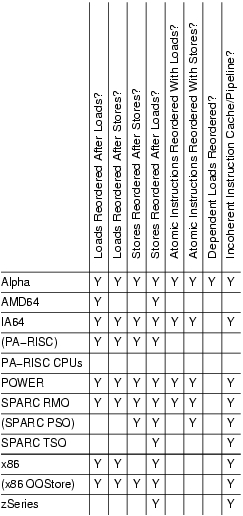{kind=link}
Sur les processeurs avec un modèle de cohérence de mémoire plus faible (comme SPARC, PowerPC, Itanium,ARM, etc.), la condition ci-dessus peut avoir lieu en raison d'un manque de cohérence du cache forcée sur les écritures sans instruction de barrière de mémoire explicite. Donc, fondamentalement, Core1 voit l'écrire sur x avant y, alors Core2 voit l'écrire sur y avant x. Une instruction complète de clôture ne serait pas nécessaire dans ce cas ... fondamentalement, vous n'auriez besoin que d'appliquer la sémantique d'écriture ou de libération avec ceci scénario de sorte que toutes les Écritures sont validées et visibles pour tous les processeurs avant que les lectures aient lieu sur les variables qui ont été écrites. Les architectures de processeur avec des modèles de cohérence de mémoire forts comme x86 rendent généralement cela inutile, mais comme le souligne Groo, le compilateur lui-même pourrait réorganiser les opérations. Vous pouvez utiliser le mot clé volatile en C et c++ pour empêcher la réorganisation des opérations par le compilateur dans un thread donné. Cela ne veut pas dire que volatile va créer code thread-safe qui gère la visibilité des lectures et des Écritures entre les threads ... une barrière de mémoire serait nécessaire que. Ainsi, alors que l'utilisation de volatile peut toujours créer du code thread non sécurisé, dans un thread donné, elle imposera une cohérence séquentielle au niveau du code machine respecté.
C'est pourquoi certains disent: Threads considérés comme nuisibles
Le problème est qu'aucun thread n'impose d'ordre entre ses deux instructions, car elles ne sont pas interdépendantes.
Le compilateur sait que x et y ne sont pas des alias, et donc il n'est pas nécessaire pour commander les opérations.
Le PROCESSEUR sait que x et y ne sont pas des alias, de sorte qu'il peut réorganiser pour la vitesse. Un bon exemple de ce lorsque le PROCESSEUR détecte une opportunité pour la combinaison d'écriture. Il peut fusionner une écriture avec une autre s'il peut le faire sans violer son modèle de cohérence.
La dépendance mutuelle semble étrange mais elle n'est vraiment pas différente de toute autre condition de course. Écrire directement du code à thread de mémoire partagée est assez difficile, et c'est pourquoi des langages parallèles et des frameworks parallèles passant des messages ont été développés, afin d'isoler les risques parallèles à un petit kernel et supprimer les dangers des applications elles-mêmes.