R sous Windows: encodage des caractères hell
j'essaie d'importer un CSV encodé comme OEM-866 (jeu de caractères cyrilliques) dans R sous Windows. J'ai aussi une copie qui a été converti en UTF-8 sans BOM. Ces deux fichiers sont lisibles par toutes les autres applications sur mon système, une fois l'encodage spécifié.
de plus, sur Linux, R peut lire ces fichiers particuliers avec les encodages spécifiés très bien. Je peux aussi lire le CSV sur Windows si Je ne spécifie pas le paramètre" fileEncoding", mais cela se traduit par texte illisible. Lorsque je spécifie l'encodage du fichier sur Windows, j'obtiens toujours les erreurs suivantes, tant pour le fichier OEM que pour le fichier Unicode:
d'Origine OEM d'importation de fichier:
> oem.csv <- read.table("~/csv1.csv", sep=";", dec=",", quote="",fileEncoding="cp866") #result: failure to import all rows
Warning messages:
1: In scan(file, what, nmax, sep, dec, quote, skip, nlines, na.strings, :
invalid input found on input connection '~/Revolution/RProject1/csv1.csv'
2: In scan(file, what, nmax, sep, dec, quote, skip, nlines, na.strings, :
number of items read is not a multiple of the number of columns
UTF-8 w/ o bom file import:
> unicode.csv <- read.table("~/csv1a.csv", sep=";", dec=",", quote="",fileEncoding="UTF-8") #result: failure to import all row
Warning messages:
1: In scan(file, what, nmax, sep, dec, quote, skip, nlines, na.strings, :
invalid input found on input connection '~/Revolution/RProject1/csv1a.csv'
2: In scan(file, what, nmax, sep, dec, quote, skip, nlines, na.strings, :
number of items read is not a multiple of the number of columns
informations locales:
> Sys.getlocale()
[1] "LC_COLLATE=English_United States.1252;LC_CTYPE=English_United States.1252;LC_MONETARY=English_United States.1252;LC_NUMERIC=C;LC_TIME=English_United States.1252"
Qu'est-ce que R on Windows est responsable de cela? J'ai fait tout ce que j'ai pu, à part planter des fenêtres.
Merci
(autres tentatives infructueuses):
>Sys.setlocale("LC_ALL", "en_US.UTF-8") #OS reports request to set locale to "en_US.UTF-8" cannot be honored
>options(encoding="UTF-8") #now nothing can be imported
> noarg.unicode.csv <- read.table("~/Revolution/RProject1/csv1a.csv", sep=";", dec=",", quote="") #result: mangled cyrillic
> encarg.unicode.csv <- read.table("~/Revolution/RProject1/csv1a.csv", sep=";", dec=",", quote="",encoding="UTF-8") #result: mangled cyrillic
5 réponses
il est possible que votre problème soit résolu en changeant fileEncoding en encodage, ces paramètres fonctionnent différemment dans la fonction de lecture (voir ?lire.)
oem.csv <- read.table("~/csv1.csv", sep=";", dec=",", quote="",encoding="cp866")
juste au cas, cependant, une réponse plus complète, car il peut y avoir des obstacles non évidents. En bref: il est possible de travailler avec Cyrillic dans R sur Windows (dans mon cas Win 7).
vous pourriez avoir besoin d'essayer quelques encodages possibles pour obtenir des choses à travailler. Pour l'exploration de texte, un l'aspect important est d'obtenir les variables de votre entrée pour correspondre aux données. La fonction Encoding () est très utile, Voir aussi iconv (). Ainsi il est possible de voir votre paramètre natif.
Encoding(variant <- "Минемум")
dans mon cas, L'encodage est UTF-8, bien que cela puisse dépendre des paramètres du système. Donc, nous pouvons essayer le résultat avec UTF-8 et UTF-8-BOM, et faire un fichier test dans le bloc-notes++ avec une ligne de Latin et une ligne de Cyrillique.
UTF8_nobom_cyrillic.csv & UTF8_bom_cyrillic.csv
part2, part3, part4
Минемум конкыптам, тхэопхражтуз, ед про
peut être importé dans R par
raw_table1 <- read.csv("UTF8_nobom_cyrillic.csv", header = FALSE, sep = ",", quote = "\"", dec = ".", fill = TRUE, comment.char = "", encoding = "UTF-8")
raw_table2 <- read.csv("UTF8_bom_cyrillic.csv", header = FALSE, sep = ",", quote = "\"", dec = ".", fill = TRUE, comment.char = "", encoding = "UTF-8-BOM")
les résultats de ceux-ci sont pour moi pour BOM Cyrillic régulier dans la vue(raw_table1), et gibberish dans la console.
part2, part3, part4
ŠŠøŠ½ŠµŠ¼ŃŠ¼ ŠŗŠ¾Š½ŠŗŃ‹ŠæŃ‚Š°Š¼ тхѨŠ¾ŠæŃ…Ń€Š°Š¶Ń‚ŃŠ
plus important encore, le script ne lui donne pas accès.
> grep("Минемум", as.character(raw_table2[2,1]))
integer(0)
les résultats pour No BOM UTF-8, sont quelque chose comme cela pour la vue(raw_table1) et la console.
part2, part3, part4
<U+041C><U+0438><U+043D><U+0435><U+043C><U+0443><U+043C> <U+043A><U+043E><U+043D><U+043A><U+044B><U+043F><U+0442><U+0430><U+043C> <U+0442><U+0445><U+044D><U+043E><U+043F><U+0445><U+0440><U+0430><U+0436><U+0442><U+0443><U+0437> <U+0435><U+0434> <U+043F><U+0440><U+043E>
cependant, et c'est important, une recherche du mot à l'intérieur donnera le bon résultat.
> grep("Минемум", as.character(raw_table1[2,1]))
1
ainsi, il est possible de travailler avec des caractères non standard dans Windows, en fonction de vos objectifs précis cependant. Je travaille régulièrement avec des caractères latins non-anglais et L'UTF-8 permet de travailler dans Windows 7 sans problèmes. "WINDOWS-1252" a été utile pour exporter dans les lecteurs Microsoft tels que Excel.
PS Les mots russes ont été générés ici http://generator.lorem-ipsum.info/_russian , donc essentiellement dénué de sens. PPS les avertissements que vous avez mentionnés restent sans effet important apparent.
réponse Simple.
Sys.setlocale(locale = "Russian")
si vous voulez juste la langue Russe (pas les formats, la monnaie):
'Sys.setlocale(category = "LC_COLLATE", locale = "Russian")'
'Sys.setlocale(category = "LC_CTYPE", locale = "Russian")'
si vous utilisez Revolution R Open 3.2.2, vous aurez peut - être besoin de configurer la locale dans le Panneau de configuration: sinon - si vous avez RStudio-vous verrez du texte cyrillique dans le Visualiseur et des déchets dans la console. Ainsi, par exemple si vous tapez une chaîne de caractères Cyrillique aléatoire et frappez entrée vous obtiendrez la sortie de déchets. Fait intéressant, Revolution R n'a pas le même problème avec say texte arabe. Si vous utilisez R régulier, il semble que Sys.setlocale() est suffisant.
" Sys.setlocale () 'a été suggéré par L'utilisateur G. Grothendieck ici: R, Windows et caractères de langue étrangère
il y a deux options pour lire des données à partir de fichiers contenant des caractères non pris en charge par votre locale actuelle. Vous pouvez changer votre localisation comme suggéré par @user23676 ou vous pouvez convertir en UTF-8. Le paquet readr fournit des remplacements pour les fonctions dérivées de read.table qui effectuent cette conversion pour vous. Vous pouvez lire le fichier CP866 avec
library(readr)
oem.csv <- read_csv2('~/csv1.csv', locale = locale(encoding = 'CP866'))
il y a un petit problème, qui est qu'il y a un bug dans print.data.frame qui résulte en colonnes avec encodage UTF-8 à afficher incorrectement sur Windows. Vous pouvez contourner le bug avec print.listof(oem.csv) ou print(as.matrix(oem.csv)) .
j'en ai discuté plus en détail dans un billet de blog à http://people.fas.harvard.edu/~izahn/posts/lecture de données-avec-non-native-encodage-en-r/
selon Wikipedia :
la marque d'ordre de byte (BOM) est un caractère Unicode utilisé pour signaler l'Enness (ordre de byte) [...] La norme Unicode autorise le BOM en UTF-8, mais n'exige ni ne recommande son utilisation.
de toute façon dans le monde de Windows UTF8 est utilisé avec BOM. Par exemple, L'éditeur de bloc-notes standard utilise le BOM lors de l'enregistrement en UTF-8.
De nombreuses applications nées dans un monde Linux (y compris LaTex, par exemple lors de l'utilisation du paquet inputenc avec le paquet utf8 ) présentent des problèmes de lecture des fichiers BOM-UTF-8.
Notepad++ est une option typique pour convertir les types d'encodage, les terminaisons de ligne Linux/DOS/Mac et la suppression de BOM.
comme nous le savons, la représentation non recommandée UTF-8 du BOM est la séquence byte
0xEF,0xBB,0xBF
au début du flux de texte, pourquoi ne pas l'enlever avec R lui-même?
## Converts an UTF8 BOM file as a NO BOM file
## ------------------------------------------
## Usage:
## Set the variable BOMFILE (file to convert) and execute
BOMFILE="C:/path/to/BOM-file.csv"
conr= file(BOMFILE, "rb")
if(readChar(conr, 3, useBytes = TRUE)== ""){
cat("The file appears UTF8-BOM. Converting as NO BOM.\n\n")
BOMFILE=sub("(\.\w*$)", "-NOBOM\1", BOMFILE)
BOMFILE=paste0( getwd(), '/', basename (BOMFILE))
if(file.exists(BOMFILE)){
cat(paste0('File:\n', BOMFILE, '\nalready exists. Please rename.\n' ))
} else{
conw= file(BOMFILE, "wb")
while(length( x<-readBin(conr, "raw", n=100)) !=0){
cat (rawToChar (x))
writeBin(x, conw)
}
cat(paste0('\n\nFile was converted as:\n', getwd(), BOMFILE, '\n' ))
close(conw)
}
}else{
BOMFILE=paste0( getwd(), '/', basename (BOMFILE))
cat(paste0('File:\n', BOMFILE, '\ndoes not appear UTF8 BOM.\n' ))
}
close(conr)
je pense qu'il y a toutes les bonnes réponses ici et beaucoup de doubles. J'essaie de contribuer avec, je l'espère, une description plus complète du problème et la façon dont j'ai utilisé les solutions ci-dessus.
mes résultats d'écriture de situation de L'API Google Translate dans le fichier R
pour mon but particulier, j'envoyais un texte à Google API:
# load library
library(translateR)
# return chinese tranlation
result_chinese <- translate(content.vec = "This is my Text",
google.api.key = api_key,
source.lang = "en",
target.lang = "zh-CN")
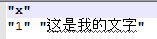
le résultat que je vois dans le R Environment est comme ceci:

cependant si j'imprime ma variable en Console je verrai ce texte joliment formaté (j'espère):
> print(result_chinese)
[1] "这是我的文字"
dans ma situation, j'ai dû écrire file to Computer File System en utilisant la fonction r write.table() ... mais tout ce que j'écrirais serait dans le format:
Ma Solution - pris de réponses ci-dessus:
j'ai décidé d'utiliser effectivement la fonction Sys.setlocale() comme ceci:
Sys.setlocale(locale = "Chinese") # set locale to Chinese
> Sys.setlocale(locale = "Chinese") # set locale to Chinese
[1] "LC_COLLATE=Chinese (Simplified)_People's Republic of China.936;LC_CTYPE=Chinese (Simplified)_People's Republic of China.936;LC_MONETARY=Chinese (Simplified)_People's Republic of China.936;LC_NUMERIC=C;LC_TIME=Chinese (Simplified)_People's Republic of China.936"
après cela ma traduction a été visualisée correctement dans L'environnement R:
# return chinese tranlation with new locale
result_chinese <- translate(content.vec = "This is my Text",
google.api.key = api_key,
source.lang = "en",
target.lang = "zh-CN")
Le résultat dans R de l'Environnement a été:

Après cela, je pourrais écrire mon dossier et finalement voir le texte chinois:
# writing
write.table(result_chinese, "translation.txt")
enfin dans ma fonction de traduction je retournerais à mes paramètres d'origine avec:
Sys.setlocale() # to set up current locale to be default of the system
> Sys.setlocale() # to set up current locale to be default of the system
[1] "LC_COLLATE=English_United Kingdom.1252;LC_CTYPE=English_United Kingdom.1252;LC_MONETARY=English_United Kingdom.1252;LC_NUMERIC=C;LC_TIME=English_United Kingdom.1252"
ma conclusion:
avant de traiter de langues spécifiques dans R:
- Configuration des paramètres régionaux de l' une de la langue spécifique
Sys.setlocale(locale = "Chinese") # set locale to Chinese - effectuer toutes les manipulations de données
- Retour aux paramètres d'origine
Sys.setlocale() # set original system settings