Les caractères des points d'interrogation qui s'affichent dans le texte, pourquoi?
j'ai un serveur de sauvegarde qui sauvegarde automatiquement mon site en direct, à la fois les fichiers et la base de données.
sur le site live, le texte a l'air bien, mais quand vous voyez la version miroir de celui-ci, il s'affiche '?"dans une partie du texte. Ce texte est stocké dans la table de la base de données des nouvelles.
Voici une capture d'écran de celui-ci étant sur le serveur live et sur le serveur miroir.
que pourrait-il se passer dans le processus de sauvegarde vers le haut du miroir le serveur? texte alternatif http://i34.tinypic.com/2mpbfo6.jpg
8 réponses
Les articles suivants seront utiles
http://dev.mysql.com/doc/refman/5.0/en/charset-syntax.html
http://dev.mysql.com/doc/refman/5.0/en/charset-connection.html
lorsque vous vous connectez à la base de données, lancez la commande suivante:
SET NAMES 'utf8';
assurez-vous que votre page Web utilise aussi L'encodage UTF-8:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
PHP offre également plusieurs fonction qui sera utile pour les conversions:
éditez votre fichier de configuration Apache sur le serveur" miroir " (le serveur avec le problème), et commentez la ligne suivante:
AddDefaultCharset UTF-8
puis redémarrez Apache:
service httpd restart
le problème est que la ligne "AddDefaultCharset UTF-8" l'emporte sur le type de contenu spécifié dans le .fichiers html; par exemple:
<meta http-equiv=Content-Type content="text/html; charset=windows-1252">
le symptôme le plus courant est que les codes de caractères au-dessus de 127 s'affichent comme des diamants noirs avec des points d'interrogation sur eux (en Chrome, Safari ou Firefox), ou en petites boîtes (en mi et Opera). Les fichiers HTML générés par Microsoft Word ont généralement beaucoup de tels caractères, le plus commun étant le code de caractère 160 = 0xA0, qui est l'équivalent de "" dans L'encodage Windows-1252, et est souvent trouvé entre les balises de portée, comme ceci:
<span style="mso-spacerun: yes">ááá </span>
je suis arrivé ici à la recherche d'une solution pour JavaScript affiché dans le navigateur et bien que pas directement lié à une base de données...
dans mon cas, j'ai copié et collé du texte que j'ai trouvé sur internet dans un fichier JavaScript et je l'ai enregistré avec le bloc-notes de Windows.
lorsque la page qui utilise ce fichier JavaScript affiche les chaînes, il y a des points d'interrogation (comme ceux indiqués dans la question) au lieu des caractères spéciaux comme les lettres accentuées., etc.
j'ai ouvert le fichier en utilisant Notepad++. Juste après avoir ouvert le fichier, j'ai vu que l'encodage des caractères était défini comme ANSI comme vous pouvez le voir (curseur de la souris sur le pied de page) dans la capture d'écran suivante:
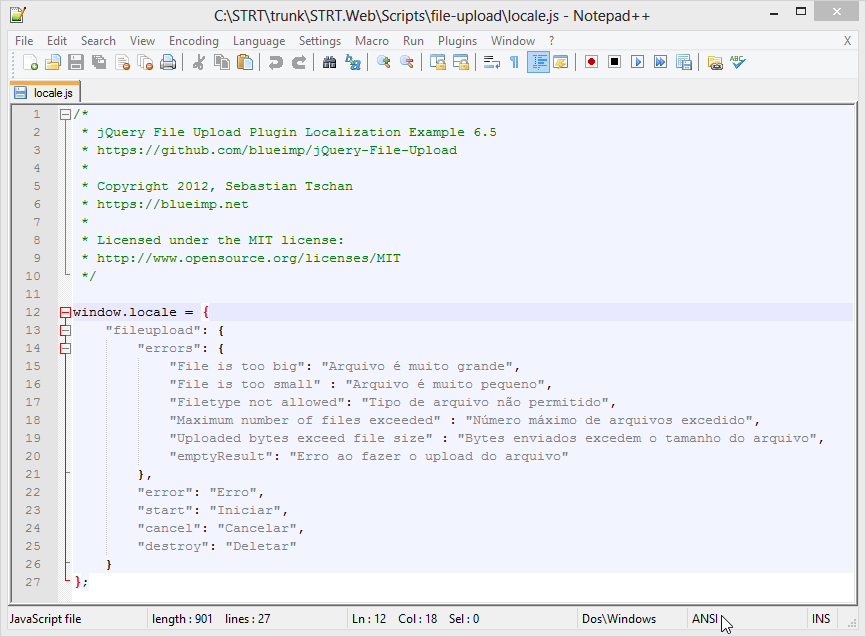
Pour résoudre le problème, cliquez sur le Encoding menu en Notepad++ et sélectionnez Encode in UTF-8. Tu devrais être prête à partir. :)
votre navigateur n'a pas interprété correctement l'encodage de la page (soit parce que vous l'avez forcé à un réglage particulier, soit parce que la page est mal positionnée), et ne peut donc pas afficher certains des caractères.
Cela va être quelque chose à voir avec les encodages de caractères.
êtes-vous sûr que le site miroir possède les mêmes propriétés en ce qui concerne l'encodage des caractères que votre serveur principal?
selon le type de serveur que vous avez, cela peut être une propriété du processus du serveur lui-même, ou cela peut être une variable d'environnement.
par exemple, si C'est un environnement UNIX, essayez de comparer LANG ou LC_ALL?
Voir aussi ici
Vérifier le jeu de caractères émis par votre serveur miroir. Il semble y avoir une différence par rapport au serveur principal -- le site en direct semble sortir Unicode, alors que le miroir ne l'est pas. En outre, il est généralement une bonne idée de frotter les caractères Unicode dans votre contenu entrant et de les remplacer par leurs entités HTML appropriées.
votre problème concerne les "citations intelligentes", les "tirets em" et les "tirets en"."Je sais que vous pouvez remplacer le tiret cadratin — et n-tirets – (ce qui devrait être fait sur le côté d'entrée de votre base de données); Je ne sais pas ce que le remplacement correct pour les citations intelligentes serait. (J'ai l'habitude de simplement remplacer tous bouclés apostrophes "et tous bouclés guillemets doubles" ... Les geeks typographiques peuvent se sentir libres de me tirer dessus à vue.)
je devrais noter que certains navigateurs sont plus indulgents que d'autres avec ce problème -- Internet Explorer sur Windows a tendance à auto-magiquement détecter et" corriger " cela; Firefox et la plupart des autres les navigateurs affichent les points d'interrogation.
je maudis habituellement MS word et ensuite exécute le Wscript suivant.
// remplacer avec chemin d'accès à un fichier qui a besoin de nettoyage
PATH = " test.html"
var=WScript.CreateObject ("Scripting.FileSystemObject");
var contenu=aller.GetFile (PATH).OpenAsTextStream ().ReadAll ();
var out=aller.CreateTextFile("nettoyage"+CHEMIN d'accès, true);
//
Unicode ou d'autres caractères?
j'ai vu des caractères "étranges" similaires apparaître sur des sites sur lesquels j'ai travaillé souvent lorsque le texte est copié à partir d'un e-mail ou d'un autre format de document (par exemple word) dans un éditeur de texte. L'éditeur peut afficher les caractères non ASCII mais pas le navigateur. Pour le site web, je suggérerais de chercher le code d'entité HTML pour le caractère et de l'insérer à la place ... ou de passer à plus standard.