Python est temps.clock() en fonction du temps.temps (le) de la précision?
Qu'est-ce qui est le mieux à utiliser pour le timing en Python? temps.clock() ou de temps.temps (le)? Qui offre plus de précision?
par exemple:
start = time.clock()
... do something
elapsed = (time.clock() - start)
vs.
start = time.time()
... do something
elapsed = (time.time() - start)
17 réponses
au 3.3, time.clock () est déprécié , et il est suggéré d'utiliser time.process_time() ou du temps.perf_counter() à la place.
précédemment 2.7, selon le module temporel docs :
du temps.horloge()
sur Unix, renvoie le temps du processeur en cours sous la forme d'un nombre à virgule flottante. exprimée en secondes. La précision, et en fait la définition même de la notion de "temps processeur", ne dépend que de la fonction C du même nom, mais en tout cas, c'est la fonction à utiliser pour l'analyse comparative de Python ou de l'échéancier des algorithmes.
sur Windows, Cette fonction renvoie les secondes d'horloge du mur qui se sont écoulées depuis le le premier appel à cette fonction, en tant que numéro flottant, basé sur le Win32 function QueryPerformanceCounter (). La résolution est typiquement mieux que la microseconde.
de plus, il y a le module timeit pour comparer des extraits de code.
La réponse courte est: la plupart du temps time.clock() sera mieux.
Cependant, si vous chronométrez du matériel (par exemple un algorithme que vous mettez dans le GPU), alors time.clock() se débarrassera de ce temps et time.time() est la seule solution restante.
Note: quelle que soit la méthode utilisée, le timing dépendra de facteurs que vous ne pouvez pas contrôler (quand le processus va changer, combien de fois, ...), c'est pire avec time.time() mais existe aussi avec time.clock() , donc vous ne jamais exécuter un seul essai de synchronisation, mais toujours exécuter une série d'essais et examiner la moyenne/variance des temps.
autres ont répondu re: time.time() vs. time.clock() .
cependant, si vous planifiez l'exécution d'un bloc de code à des fins de benchmarking/profilage, Vous devriez jeter un oeil au timeit module .
dépend de ce qui vous intéresse. Si vous voulez dire L'heure du mur (comme l'heure sur l'horloge de votre mur), l'heure.clock () ne fournit aucune précision car il peut gérer le temps CPU.
Une chose à garder à l'esprit:
Changer l'heure du système affecte time.time() mais pas time.clock() .
j'avais besoin de contrôler certaines exécutions de tests automatiques. Si une étape du cas d'essai a pris plus d'un certain temps, ce TC a été abandonné pour continuer avec la suivante.
mais parfois une étape nécessaire pour changer l'heure du système( pour vérifier le module scheduler de l'application à l'essai), donc après avoir réglé l'heure du système de quelques heures à l'avenir, le délai D'attente de TC a expiré et le cas d'essai a été abandonné. J'ai dû passer de time.time() à time.clock() pour gérer cela correctement.
clock() - > numéro à virgule flottante
renvoie le temps CPU ou temps réel depuis le début du processus ou depuis
le premier appel à clock() . Cela a autant de précision que le système
dossier.
time() - > numéro à virgule flottante
renvoie l'heure actuelle en secondes depuis l'époque. Une fraction de seconde peut être présent si l'horloge du système.
habituellement time() est plus précis, parce que les systèmes d'exploitation ne stockent pas le temps de fonctionnement du processus avec la précision ils stockent le temps du système (c'est-à-dire, le temps réel)
pour mon propre practice. time() a une meilleure précision que clock() sous Linux. clock() a seulement une précision inférieure à 10 ms. Tandis que time() donne la précision de préfet.
Mon test est sur CentOS 6.4 et python 2.6
using time():
1 requests, response time: 14.1749382019 ms
2 requests, response time: 8.01301002502 ms
3 requests, response time: 8.01491737366 ms
4 requests, response time: 8.41021537781 ms
5 requests, response time: 8.38804244995 ms
using clock():
1 requests, response time: 10.0 ms
2 requests, response time: 0.0 ms
3 requests, response time: 0.0 ms
4 requests, response time: 10.0 ms
5 requests, response time: 0.0 ms
6 requests, response time: 0.0 ms
7 requests, response time: 0.0 ms
8 requests, response time: 0.0 ms
La différence est très spécifique à la plateforme.
clock () est très différent sur Windows que sur Linux, par exemple.
pour le genre d'exemples que vous décrivez, vous voulez probablement le module" timeit " à la place.
sur Unix time.clock() mesure la quantité de temps CPU qui a été utilisé par le processus actuel, de sorte qu'il n'est pas bon de mesurer le temps écoulé à partir d'un certain point dans le passé. Sur les fenêtres, il mesurera les secondes d'horloge du mur qui se sont écoulées depuis le premier appel à la fonction. Sur l'heure du système.time() retournera secondes écoulées depuis l'époque.
si vous écrivez du code qui est destiné uniquement pour Windows, l'un ou L'autre fonctionnera (bien que vous utiliserez les deux différemment - Non la soustraction est nécessaire pour le moment.horloge.))( Si cela va fonctionner sur un système Unix ou vous voulez le code qui est garanti pour être portable, vous voulez utiliser le temps.temps.)(
courte réponse: utiliser temps.horloge () pour le chronométrage en Python.
on *nix systems, clock() renvoie le temps du processeur sous la forme d'un nombre à virgule flottante, exprimé en secondes. Sur Windows, il renvoie les secondes écoulées depuis le premier appel à cette fonction, sous la forme d'un numéro flottant.
time () renvoie les secondes depuis L'époque, en UTC, comme un nombre de virgule flottante. Il n'y a aucune garantie que vous obtiendrez un meilleur précision que 1 seconde (même si le temps () renvoie un nombre de virgule flottante). Notez également que si l'horloge du système a été retardée entre deux appels à cette fonction, le second appel de fonction retournera une valeur inférieure.
pour autant que je sache, le temps.clock() a autant de précision que votre système le permet.
j'utilise ce code pour comparer 2 méthodes .Mon système D'exploitation est windows 8, Processeur core i5, RAM 4GB
import time
def t_time():
start=time.time()
time.sleep(0.1)
return (time.time()-start)
def t_clock():
start=time.clock()
time.sleep(0.1)
return (time.clock()-start)
counter_time=0
counter_clock=0
for i in range(1,100):
counter_time += t_time()
for i in range(1,100):
counter_clock += t_clock()
print "time() =",counter_time/100
print "clock() =",counter_clock/100
sortie:
time () = 0.0993799996376
horloge() = 0.0993572257367
bonne réponse: ils sont tous les deux de la même longueur d'une fraction.
mais quelle vitesse si subject est time ?
un petit Cas Type :
import timeit
import time
clock_list = []
time_list = []
test1 = """
def test(v=time.clock()):
s = time.clock() - v
"""
test2 = """
def test(v=time.time()):
s = time.time() - v
"""
def test_it(Range) :
for i in range(Range) :
clk = timeit.timeit(test1, number=10000)
clock_list.append(clk)
tml = timeit.timeit(test2, number=10000)
time_list.append(tml)
test_it(100)
print "Clock Min: %f Max: %f Average: %f" %(min(clock_list), max(clock_list), sum(clock_list)/float(len(clock_list)))
print "Time Min: %f Max: %f Average: %f" %(min(time_list), max(time_list), sum(time_list)/float(len(time_list)))
Je ne suis pas un laboratoire Suisse, mais j'ai testé..
basé sur cette question: time.clock() est mieux que time.time()
Modifier: time.clock() est un compteur interne donc ne peut pas utiliser à l'extérieur, a obtenu des limitations max 32BIT FLOAT , ne peut pas continuer à compter si pas stocker les premières/dernières valeurs. Ne peut pas fusionner un autre compteur...
Comparant le résultat d'essai entre Ubuntu et Windows 7.
Ubuntu
>>> start = time.time(); time.sleep(0.5); (time.time() - start)
0.5005500316619873
On Windows 7
>>> start = time.time(); time.sleep(0.5); (time.time() - start)
0.5
comme d'autres l'ont noté time.clock() est déprécié en faveur de time.perf_counter() ou time.process_time() , mais Python 3.7 introduit le timing de résolution nanoseconde avec time.perf_counter_ns() , time.process_time_ns() , et time.time_ns() , avec 3 autres fonctions.
ces 6 nouvelles fonctions de résolution nanseconde sont détaillées dans PEP 564 :
time.clock_gettime_ns(clock_id)
time.clock_settime_ns(clock_id, time:int)
time.monotonic_ns()
time.perf_counter_ns()
time.process_time_ns()
time.time_ns()ces fonctions sont similaires à la version sans le suffixe _ns, mais renvoie un certain nombre de nanosecondes en tant que Python int.
comme d'autres l'ont également noté, utilisez le timeit module fonctions de temps et de petits fragments de code.
pour prolonger les résultats de @Hill, voici un test utilisant python 3.4.3 Sur Xubuntu 16.04 à travers le vin:
(timeit.default_timer utilisera le temps.clock () parce qu'il voit L'OS comme 'win32')
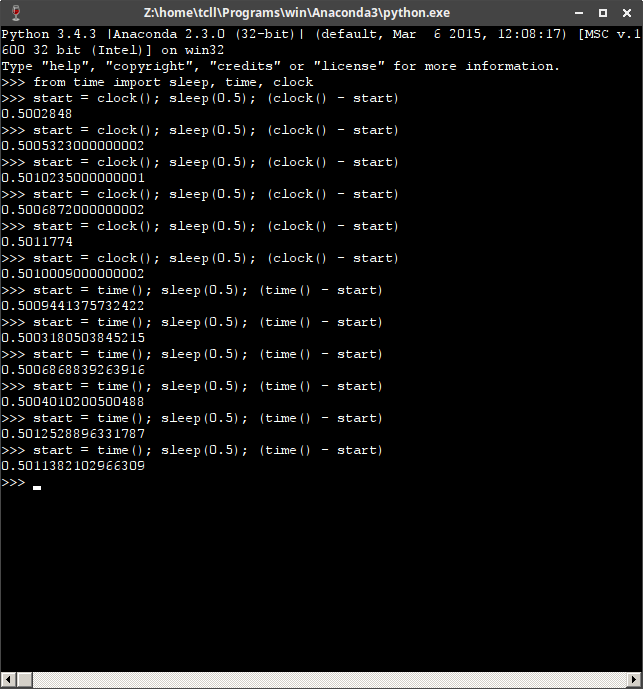
lorsque vous utilisez Windows, clock() est généralement plus précis, mais ce n'est pas le cas sur le vin...
vous pouvez voir ici le temps() est plus précise que l'horloge(), qui est généralement le cas avec Linux et Mac.