Python Requests vs pycurl Performance
comment la bibliothèque de requêtes se compare-t-elle à la performance de PyCurl?
je crois comprendre que Requests est un wrapper python pour urllib alors que PyCurl est un wrapper python pour libcurl qui est natif, donc PyCurl devrait avoir de meilleures performances, mais pas sûr de combien.
Je ne trouve aucun point de comparaison.
3 réponses
je vous ai écrit un benchmark complet, à l'aide d'une application flasque triviale appuyée par gUnicorn/meinheld + nginx (pour performance et HTTPS), et voir combien de temps il faut pour traiter 10 000 demandes. Les Tests sont effectués en AWS sur une paire de c4 déchargé.grandes instances, et l'instance du serveur n'était pas limitée au CPU.
TL;DR résumé: si vous faites beaucoup de réseautage, utilisez PyCurl, sinon utilisez requests. Pycurl termine les petites requêtes 2x-3x as requêtes rapides jusqu'à ce que vous atteigniez la limite de bande passante avec de grandes requêtes (environ 520 MBit ou 65 MB/S ici), et utilise de 3x à 10x moins de puissance CPU. Ces figures comparent les cas où le comportement de mise en commun des connexions est le même; par défaut, PyCurl utilise la mise en commun des connexions et les caches DNS, là où les requêtes ne le font pas, donc une implémentation naïve sera 10 fois plus lente.
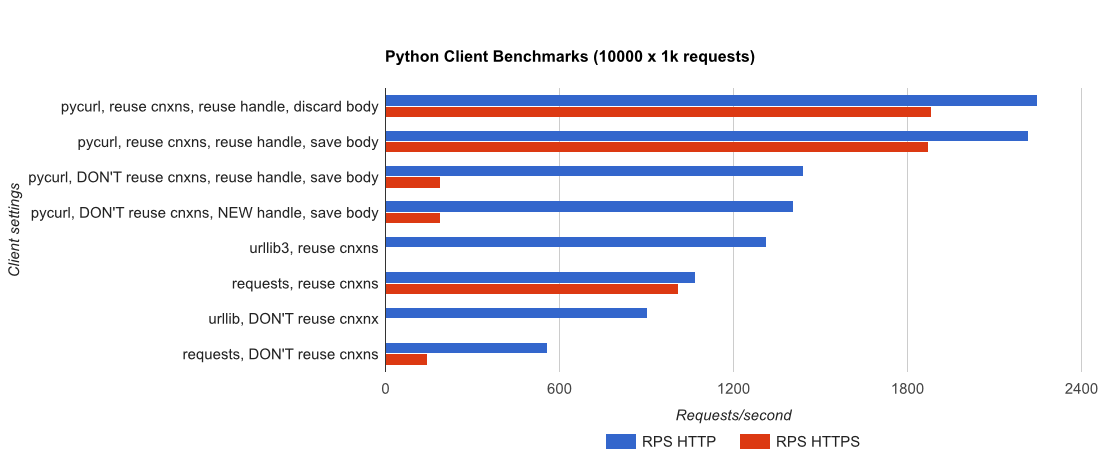
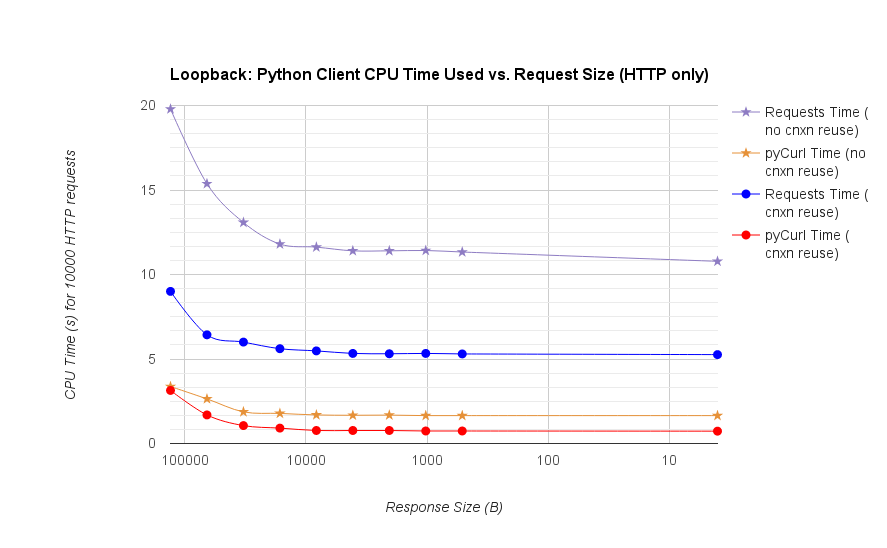
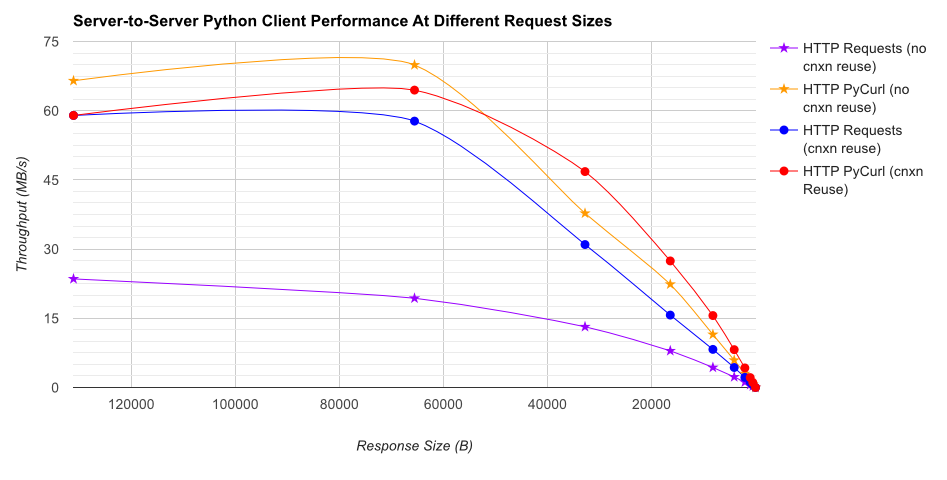
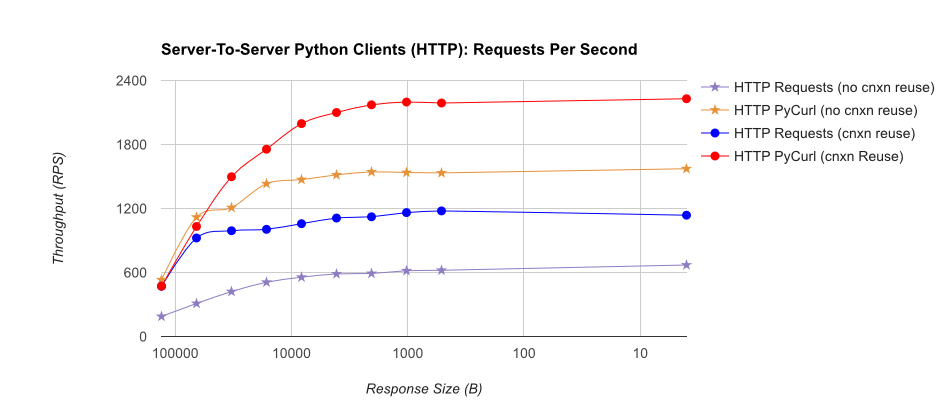
notez que les tracés à double log ne sont utilisés que pour le graphique ci-dessous, en raison des ordres de grandeur impliqués
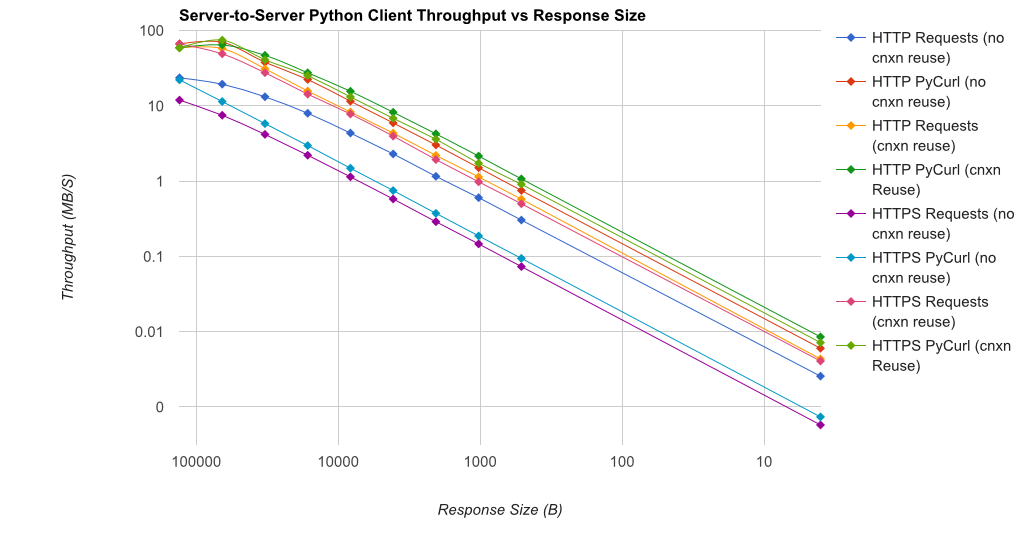
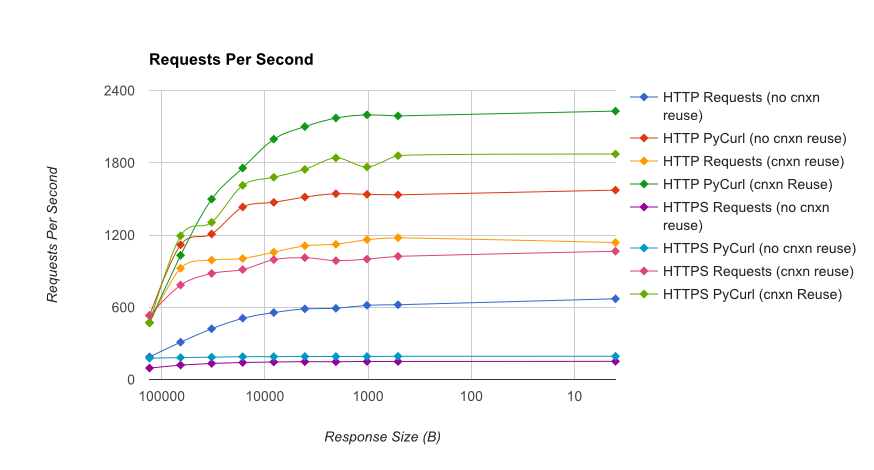
- pycurl prend environ 73 CPU-microsecondes pour émettre une requête lors de la réutilisation d'un connexion
- demande prend environ 526 CPU-microsecondes pour émettre une demande lors de la réutilisation d'une connexion
- pycurl prend environ 165 CPU-microsecondes à ouvrir une nouvelle connexion et émettre une requête (aucune réutilisation de connexion), ou ~ 92 microsecondes pour ouvrir
- demande prend environ 1078 CPU-microsecondes à ouvrir une nouvelle connexion et émettre une requête (aucune réutilisation de connexion), ou ~ 552 microsecondes pour ouvrir
les résultats Complets sont dans le lien, ainsi que la méthodologie de référence et la configuration du système.
mises en garde: bien que j'ai pris soin de m'assurer que les résultats sont recueillis de façon scientifique, ce n'est que tester un type de système et un système d'exploitation, et un sous-ensemble limité de performances et surtout les options HTTPS.
d'Abord et avant tout, requests est construit sur le dessus du urllib3 bibliothèque, le stdlib urllib ou urllib2 les bibliothèques ne sont pas utilisés.
il y a peu d'intérêt à comparer requests