But de l'alignement de la mémoire
Je ne comprends pas. Dites que vous avez une mémoire avec un mot de mémoire d'une longueur de 1 octet. Pourquoi ne pouvez-vous pas accéder à une variable longue de 4 octets dans un accès mémoire unique sur une adresse non alignée(c.-à-d. non divisible par 4), comme c'est le cas avec des adresses alignées?
8 réponses
c'est une limitation de nombreux processeurs sous-jacents. Il est généralement possible de contourner ce problème en faisant 4 fetches à byte simples inefficaces plutôt qu'un fetch à mot efficace, mais de nombreux spécificateurs de langue ont décidé qu'il serait plus facile de les proscrire et de forcer tout à être aligné.
il y a beaucoup plus d'informations dans ce lien que L'OP a découvert.
le sous-système mémoire d'un processeur moderne est limité à l'accès à la mémoire à la granularité et l'alignement de sa taille de mot; c'est le cas pour un certain nombre de raisons.
vitesse
les processeurs modernes ont plusieurs niveaux de mémoire cache que les données doivent être tirées à travers; soutenir des lectures d'un seul octet ferait le débit du sous-système de mémoire étroitement lié au débit de l'unité d'exécution (aka cpu-bound); tout cela rappelle comment mode PIO a été dépassé par DMA pour plusieurs des mêmes raisons dans les disques durs.
CPU toujours lit à sa taille de mot (4 octets sur un processeur 32 bits), de sorte que lorsque vous faites un non alignés adresse d'accès sur un processeur qui prend en charge le processeur va lire plusieurs mots. Le CPU Lira chaque mot de mémoire que l'adresse demandée chevauche. Cela provoque une amplification jusqu'à 2 fois le nombre de mémoire transactions nécessaires pour accéder aux données demandées.
pour cette raison, il peut très facilement être plus lent à lire deux octets que quatre. Par exemple, disons que vous avez une structure en mémoire qui ressemble à ceci:
struct mystruct {
char c; // one byte
int i; // four bytes
short s; // two bytes
}
sur un processeur 32 bits il serait très probablement aligné comme montré ici:
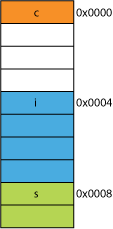
le processeur peut lire chacun de ces membres dans une transaction.
dites que vous aviez une version emballée de la structure, peut-être du réseau où elle était emballée pour l'efficacité de transmission; elle pourrait ressembler à quelque chose comme ceci:
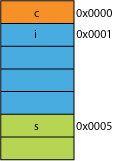
lire le premier octet va être le même.
quand vous demandez au processeur de vous donner 16 bits à partir de 0x0005 il devra lire un mot à partir de 0x0004 et décaler à gauche de 1 octet pour le placer dans un registre de 16 bits; un peu de travail supplémentaire, mais la plupart peuvent gérer cela en un cycle.
si vous demandez 32 bits à partir de 0x0001, vous obtiendrez une amplification 2X. Le processeur Lira à partir de 0x0000 dans le registre de résultat et décalera à gauche 1 octet, puis relira à partir de 0x0004 dans un registre temporaire, décalera à droite 3 octets, puis OR il avec le registre de résultat.
Gamme
pour tout espace d'adresse donné, si l'architecture peut supposer que les 2 LSB sont toujours 0 (par ex., Machines 32 bits) puis il peut accéder à 4 fois plus de mémoire (les 2 bits enregistrés peuvent représenter 4 états distincts), ou la même quantité de mémoire avec 2 bits pour quelque chose comme des drapeaux. Enlever les 2 LSB d'une adresse vous donnerait un alignement de 4 octets; aussi appelé stride de 4 octets. Chaque fois qu'une adresse est incrémentée, elle incrémente effectivement le bit 2, pas le bit 0, c'est-à-dire que les 2 derniers bits continueront toujours à être 00 .
cela peut même affecter la conception physique du système. Si le bus d'adresse a besoin de 2 bits de moins, il peut y avoir 2 pins de moins sur le CPU, et 2 traces de moins sur le circuit imprimé.
atomicité
le CPU peut fonctionner sur un mot aligné de mémoire atomiquement, ce qui signifie qu'aucune autre instruction ne peut interrompre cette opération. Cela est essentiel pour le bon fonctionnement de nombreuses structures de données sans verrouillage et autres simultané paradigmes.
Conclusion
le système de mémoire d'un processeur est un peu plus complexe et impliqué que décrit ici; une discussion sur comment un processeur x86 adresse réellement la mémoire peut aider (de nombreux processeurs fonctionnent de la même manière).
Il ya beaucoup plus d'avantages à adhérer à l'alignement de la mémoire que vous pouvez lire à cet article D'IBM .
L'utilisation principale d'un ordinateur est de transformer des données. Les architectures et les technologies de mémoire modernes ont été optimisées au cours des décennies pour faciliter l'obtention de plus de données, l'entrée, la sortie et entre des unités d'exécution plus nombreuses et plus rapides–d'une manière très fiable.
Bonus: Caches
un autre alignement-pour-performance auquel j'ai fait allusion précédemment est l'alignement sur les lignes de cache qui sont (par exemple, sur certains CPU) 64B.
pour plus d'informations sur combien la performance peut être gagnée en tirant parti des caches, jetez un oeil à Galerie D'effets de Cache de processeur ; de cette question sur les tailles de ligne de cache
la compréhension des lignes de cache peut être importante pour certains types d'optimisation de programme. Par exemple, l'alignement des données peut déterminer si une opération touche une ou deux lignes de cache. Comme nous l'avons vu dans l'exemple ci-dessus, cela peut facilement signifier que mal alignées cas, l'opération sera deux fois plus lent.
vous pouvez avec certains processeurs ( le nehalem peut faire cela ), mais auparavant tout l'accès mémoire était aligné sur une ligne 64 bits (ou 32 bits), parce que le bus est 64 bits de large, vous deviez aller chercher 64 bits à la fois, et il était beaucoup plus facile de les récupérer dans des 'morceaux' alignés de 64 bits.
donc, si vous vouliez obtenir un octet simple, vous avez récupéré le morceau 64-bit et puis masqué les morceaux que vous ne vouliez pas. Facile et rapide si votre octet était au du bon côté, mais s'il était au milieu de ce morceau de 64 bits, vous auriez à masquer les bits indésirables et puis déplacer les données au bon endroit. Pire, si vous voulez une variable de 2 octets, mais qui a été divisé en 2 morceaux, alors qui a nécessité le double des accès mémoire requis.
donc, comme tout le monde pense que la mémoire est bon marché, ils ont juste fait le compilateur aligner les données sur les tailles de morceaux du processeur afin que votre code fonctionne plus rapidement et plus efficacement au coût de gaspillé mémoire.
fondamentalement, la raison en est que le bus mémoire a une longueur spécifique qui est beaucoup, beaucoup plus petite que la taille de la mémoire.
ainsi, le CPU lit hors de la mémoire cache L1 sur puce, qui est souvent 32KB ces jours-ci. Mais le bus mémoire qui connecte le cache L1 au CPU aura la largeur beaucoup plus petite de la taille de la ligne de cache. Ce sera de l'ordre de 128 bits .
:
262,144 bits - size of memory
128 bits - size of bus
chevauchent parfois deux lignes de cache, ce qui nécessite une lecture de cache entièrement nouvelle pour obtenir les données. Il pourrait même manquer tout le chemin jusqu'au DRAM.
de plus, une partie du CPU devra se tenir sur sa tête pour assembler un seul objet à partir de ces deux lignes de cache différentes qui ont chacune un morceau des données. Sur une ligne, il sera dans les bits d'ordre très élevé, dans l'autre, les bits d'ordre très bas.
il y aura du matériel dédié entièrement intégré dans le pipeline qui manipule les objets alignés en mouvement sur les bits nécessaires du bus de données CPU, mais ce matériel peut faire défaut pour les objets mal alignés, parce qu'il est probablement plus logique d'utiliser ces transistors pour accélérer les programmes correctement optimisés.
dans tous les cas, la deuxième lecture de mémoire qui est parfois nécessaire ralentirait le pipeline, peu importe combien de spécial-but le matériel était (hypothétiquement et bêtement) dédié à corriger les opérations de mémoire mal alignées.
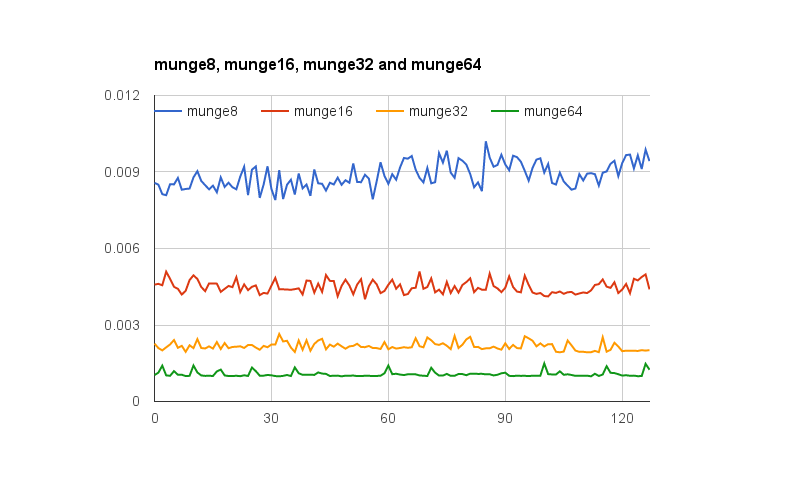
@joshperry a donné une excellente réponse à cette question. En plus de sa réponse, j'ai quelques chiffres qui montrent graphiquement les effets qui ont été décrits, en particulier l'amplification 2X. Voici un lien vers un Tableur Google montrant à quoi ressemble l'effet de différents alignements de mots. En outre, voici un lien vers un GitHub gist avec le code pour le test. Le code d'essai est adapté de l'article écrit par Jonathan Rentzsch auquel @joshperry fait référence. Les tests ont été effectués sur un Macbook Pro avec un processeur Intel i7 64 bits quad-core 2,8 GHz et 16 GO DE MÉMOIRE VIVE.
si un système avec une mémoire adressable en octets a un bus de mémoire de 32 bits, cela signifie qu'il y a effectivement quatre systèmes de mémoire de type octet qui sont tous câblés pour lire ou écrire la même adresse. Une lecture alignée de 32 bits exigera des informations stockées dans la même adresse dans les quatre systèmes de mémoire, de sorte que tous les systèmes peuvent fournir des données simultanément. Une lecture non alignée de 32 bits nécessiterait des systèmes de mémoire pour retourner des données à partir d'une adresse, et d'autres pour retourner des données à partir de la prochaine plus haute adresse. Bien qu'il existe certains systèmes de mémoire qui sont optimisés pour être en mesure de répondre à de telles requêtes (en plus de leur adresse, ils ont effectivement un signal "plus un" qui les amène à utiliser une adresse un plus élevé que spécifié) une telle fonctionnalité ajoute un coût considérable et de la complexité à un système de mémoire; la plupart des systèmes de mémoire de base ne peut tout simplement pas retourner des portions de différents mots 32 bits en même temps.
si vous avez un bus de données 32bit, les lignes d'adresse du bus d'adresse connectées à la mémoire partiront d'un 2 , de sorte que seules les adresses alignées 32bit seront accessibles dans un cycle de bus unique.
donc si un mot enjambe une limite d'alignement d'adresse - i.e. un 0 pour des données 16/32 bits ou un 1 pour des données 32 bits ne sont pas zéro, deux cycles de bus sont nécessaires pour obtenir les données.
Some les architectures/jeux d'instructions ne prennent pas en charge l'accès non aligné et généreront une exception sur de telles tentatives, de sorte que le code d'accès non aligné généré par le compilateur nécessite non seulement des cycles de bus supplémentaires, mais aussi des instructions supplémentaires, ce qui le rend encore moins efficace.
sur PowerPC vous pouvez charger un entier à partir d'une adresse impaire sans problème.
Sparc et I86 et (je pense) Itatnium soulever du matériel des exceptions lorsque vous essayez ceci.
une charge 32 bits vs quatre charges 8 bits ne va pas faire beaucoup de différence sur la plupart des processeurs modernes. Que les données soient déjà dans le cache ou non aura un effet beaucoup plus grand.