Prédiction d'une avancée temporelle multiple d'une série temporelle à L'aide de LSTM
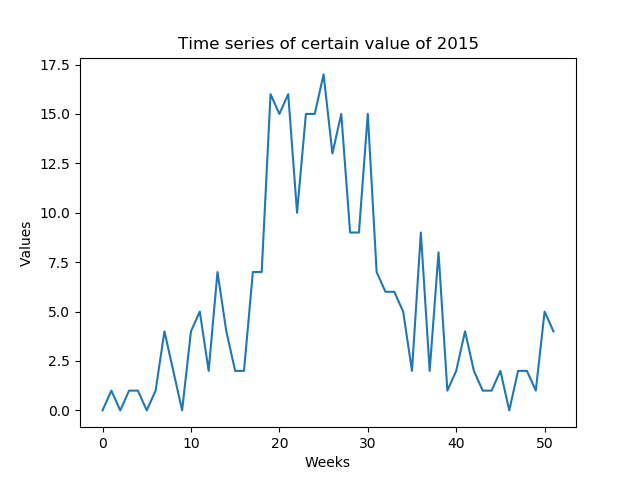
je veux prédire certaines valeurs qui sont hebdomadaires fournis. J'ai besoin de prédire l'ensemble de la série de temps de un an, formé par les semaines de l'année (52 valeurs (Figure 1),
ma première idée a été de développer un modèle LSTM de plusieurs à plusieurs (Figure 2) en utilisant Keras et TensorFlow. Je forme le modèle avec 52 entrées (séries chronologiques de l'année précédente) et je prédis 52 sorties (séries chronologiques de l'année suivante). La forme de train_X sont (x_examples, 52, 1), dans les mots, x exemples à train, 52 timesteps de 1 Caractéristique. Je comprends que le keras considérera que les 52 entrées sont une série temporelle du même domaine. La forme du train_Y est la même (y_examples, 52, 1). J'ai ajouté une couche distribuée dans le temps. Ce que je pense est que l'algorithme prédisent les valeurs comme une série temporelle au lieu de valeurs isolées (suis-je correct?)
le modèle de code dans keras:
y = y.reshape(y.shape[0], 52, 1)
X = X.reshape(X.shape[0], 52, 1)
# design network
model = Sequential()
model.add(LSTM(n_neurons, input_shape=(X.shape[1], X.shape[2]), return_sequences=True))
model.add(TimeDistributed(Dense(1)))
model.compile(loss='mean_squared_error', optimizer='adam')
# fit network
model.fit(X, y, epochs=n_epochs, batch_size=n_batch, verbose=2)
le problème est que l'algorithme n'apprend pas à travers l'exemple. Il prédit des valeurs très semblables aux valeurs des attributs. Est-ce que je modélise le problème en corrigeant?
deuxième question: Une autre idée est de former l'algorithme avec 1 entrée et 1 sortie, mais dans le test comment je vais prédire l'ensemble de la série 2015 sans regarder à la "1 entrée"? Les données de test sera ont forme différente de celle des données de formation.
2 réponses
partageant les mêmes préoccupations à propos d'avoir trop peu de données, vous pouvez le faire comme ceci.
tout d'abord, c'est une bonne idée de garder vos valeurs entre -1 et +1, donc je les normaliserais d'abord.
pour le modèle LSTM, vous devez vous assurer d'utiliser return_sequences=True .
Il n'y a rien de "mal" avec votre modèle, mais il peut nécessiter plus ou moins de couches ou d'unités pour atteindre ce que vous désirez. (Il n'y a pas de réponse claire à cette, bien.)
former le modèle pour prédire la prochaine étape:
Tout ce dont vous avez besoin est de passer Y comme un X décalé:
entireData = arrayWithShape((samples,52,1))
X = entireData[:,:-1,:]
y = entireData[:,1:,:]
l'apprentissage du modèle à l'aide de ces.
prédire l'avenir:
Maintenant, pour prédire l'avenir, car nous avons besoin d'utiliser prédit éléments d'entrée pour plus d'prédit éléments, nous allons utiliser un boucle et faire le modèle stateful=True .
créer un modèle égal au précédent, avec ces modifications:
- toutes les couches LSTM doivent avoir
stateful=True - la forme d'entrée doit être
(None, 1)- cela permet des longueurs variables
copier les poids du modèle déjà formé:
newModel.set_weights(oldModel.get_weights())
prédire un seul échantillon à la fois et jamais oubliez d'appeler model.reset_states() avant de lancer toute séquence.
d'abord prédire avec la séquence que vous connaissez déjà (ce qui assurera que le modèle prépare ses États correctement pour prédire l'avenir)
model.reset_states()
predictions = model.predict(entireData)
par la façon dont nous nous sommes entraînés, la dernière étape dans les prédictions sera le premier élément futur:
futureElement = predictions[:,-1:,:]
futureElements = []
futureElements.append(futureElement)
Maintenant, nous faisons une boucle où cet élément est l'entrée. (En raison de stateful, le modèle comprendra c'est une nouvelle étape de la séquence précédente au lieu d'une nouvelle séquence)
for i in range(howManePredictions):
futureElement = model.predict(futureElement)
futureElements.append(futureElement)
ce lien contient un exemple complet prédisant l'avenir de deux caractéristiques: https://github.com/danmoller/TestRepo/blob/master/TestBookLSTM.ipynb
j'ai des données sur 10 ans. Si mon ensemble de données de formation sont: les valeurs à partir de 4 semaines pour prédire le 5e et je continue à changer, je peux avoir presque 52 x 9 exemples pour former le modèle et 52 pour prédire (l'année dernière)
cela signifie en fait que vous n'avez que 9 Exemples de formation avec 52 caractéristiques chacun (à moins que vous ne vouliez vous former sur des données d'entrée qui se chevauchent fortement). Quoi qu'il en soit, je ne pense pas que ce soit suffisant pour mériter la formation d'un LSTM .
je suggère d'essayer un modèle beaucoup plus simple. Vos données d'entrée et de sortie sont de taille fixe, donc vous pouvez essayer sklearn.linear_model.LinearRegression qui gère plusieurs fonctionnalités d'entrée (dans votre cas 52) par exemple de formation, et plusieurs cibles (également 52).
mise à Jour: Si vous doit utiliser un LSTM alors jetez un oeil à LSTM Réseau de Neurones pour le Temps de la Série Prédiction , une implémentation Keras LSTM qui supporte plusieurs prédictions futures tout à la fois ou de façon itérative en alimentant chaque prédiction en entrée. En fonction de vos commentaires, cela devrait être exactement ce que vous voulez.
l'architecture du réseau dans cette implémentation est:
model = Sequential()
model.add(LSTM(
input_shape=(layers[1], layers[0]),
output_dim=layers[1],
return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(
layers[2],
return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(
output_dim=layers[3]))
model.add(Activation("linear"))
cependant, je recommande toujours d'exécuter une régression linéaire ou peut - être un simple réseau d'avance avec une couche cachée et la comparaison de la précision avec le LSTM. Surtout si vous prédisez une sortie à la fois et si vous l'alimentez en entrée, vos erreurs pourraient facilement s'accumuler, vous donnant de très mauvaises prédictions plus loin.