Postgres utilisation des index btree vs MySQL B + trees
nous sommes en train de migrer de MySQL à PGSQL et nous avons une table de 100 millions de lignes.
quand j'ai essayé de déterminer combien d'espace les deux systèmes utilisent, j'ai trouvé beaucoup moins de différence pour les tableaux, mais a trouvé d'énormes différences pour les indices.
Les indicesMySQL occupaient une plus grande taille que les données de la table elle-même et postgres utilisaient des tailles considérablement plus petites.
-
pour la raison, J'ai trouvé que MySQL utilise des arbres B+ pour stocker les index et postgres utilise arbres B.
-
MySQL l'usage des index était un peu différent, il stocke les données avec les index (en raison de laquelle la taille accrue), mais postgres ne le fait pas.
maintenant les questions:
-
Comparant arbre-B et B+ arbres sur la base de données de parler, il est préférable d'utiliser les arbres B+car ils sont meilleurs pour les requêtes de portée O(m) + O(logN) - où m dans la portée et la recherche est logarithmique dans les arbres B+?
maintenant dans les arbres B la recherche est logarithmique pour les requêtes de portée il pousse Jusqu'à O (N) puisqu'il n'a pas la liste liée structure sous-jacente pour les noeuds de données. Cela dit, Pourquoi postgres utilise-t-il des arbres B? Fonctionne-t-il bien pour les requêtes de portée (il le fait, mais comment le gère-t-il en interne avec les arbres B)?
-
la question ci-dessus est d'un point de vue postgrès, mais D'un point de vue MySQL, pourquoi utilise-t-il plus de stockage que postgrès, Quel est l'avantage de performance de l'utilisation des arbres B+dans la réalité?
j'aurais pu manquer/mal comprendre beaucoup de choses, alors s'il vous plaît n'hésitez pas à corriger ma compréhension ici.
Edit for answering Rick James questions
- je suis à l'aide de moteur InnoDB de MySQL
- j'ai construit l'indice après avoir peuplé les données - de la même façon que je l'ai fait dans postgres
- les index ne sont pas des index uniques, juste des index normaux
- il n'y avait pas d'inserts aléatoires, j'ai utilisé le chargement csv dans postgres et MySQL et seulement après cela j'ai créé les index.
- Postgres taille de bloc pour les indices et les données est de 8KB, Je ne suis pas sûr pour MySQL, mais Je ne l'ai pas changé, donc ça doit être les valeurs par défaut.
- Je n'appellerais pas les lignes grandes, elles ont environ 4 champs de texte avec 200 caractères de long, 4 champs décimaux et 2 champs bigint - 19 Nombres de long.
- le P. K est une colonne bigint avec 19 Nombres,Je ne suis pas sûr si c'est volumineux? À quelle échelle faut-il distinguer les grosses et les non grosses?
- la taille de la table MySQL était de 600 MB et Postgres était d'environ 310 MB tous les deux y compris les index - ce ça fait 48% de plus si mes calculs sont bons.Mais y a-t-il un moyen pour que je puisse mesurer la taille de l'indice seul dans MySQL excluant la taille de la table? Cela peut conduire à de meilleurs nombres, je suppose.
- informations Machine: j'avais assez de RAM-256GB pour assembler toutes les tables et les index, mais je ne pense pas que nous ayons besoin de parcourir cette route du tout, je n'ai pas vu de différence de performance notable dans les deux.
Questions Supplémentaires
- quand nous disons que la fragmentation se produit ? Y a-t-il un moyen de procéder à la dé-fragmentation pour que nous puissions dire qu'au-delà de cela, il n'y a rien à faire.Je suis à l'aide de Cent OS.
- est-il un moyen de mesurer la taille de l'indice le long dans MySQL, en ignorant la clé primaire comme il est regroupé, de sorte que nous pouvons réellement voir quel type occupe plus de taille si elle existe.
3 réponses
tout d'abord, et avant tout , si vous n'utilisez pas InnoDB , fermez cette question, reconstruisez avec InnoDB, puis voyez si vous avez besoin de rouvrir la question. MyISAM est pas préférable et ne doit pas être discuté.
Comment avez-vous construire l'index dans MySQL? Il y a plusieurs façons de construire explicitement ou implicitement des index; ils conduisent à un empaquetage meilleur ou pire.
MySQL: les données et les index sont stockés dans des arbres B+composés de blocs 16KB .
MySQL: UNIQUE indices (y compris le PRIMARY KEY ) doit être mis à jour comme vous insérez des lignes. Donc, un index UNIQUE aura nécessairement beaucoup de blocs, etc.
MySQL: le PRIMARY KEY est regroupé avec les données, donc il prend effectivement l'espace zéro. Si vous chargez les données dans l'ordre PK, la fragmentation du bloc est minime.
Non - UNIQUE les touches secondaires peuvent être construites à la volée, ce qui entraîne une certaine fragmentation. Ou ils peuvent être construits après le chargement de la table, ce qui conduit à un emballage plus dense.
les clés secondaires ( UNIQUE ou non) comprennent implicitement le PRIMARY KEY . Si le PK est "grand" alors les touches secondaires sont volumineuses. Qu'est-ce que votre PK? Est-ce la réponse?
en théorie, les inserts totalement aléatoires dans un BTree conduisent à des blocs d'environ 69% pleine . C'est peut-être la réponse. MySQL est-il 45% plus grand (1/69%)?
avec des lignes de 100M, de nombreuses opérations sont probablement liées aux e/s parce que vous n'avez pas assez de RAM pour mettre en cache toutes les données et / ou les blocs d'index nécessaires. Si tout est caché, alors B-Tree par rapport à B + Tree ne fera pas beaucoup de différence. Analysons ce qui doit se passer pour une requête de gamme quand les choses ne sont pas complètement cachées.
avec l'un ou l'autre type d'arbre, l'opération commence par une descente dans l'arbre. Pour MySQL, les rangées de 100M auront un arbre B+d'environ 4 niveaux de profondeur. Les 3 noeuds non-feuilles (encore des blocs de 16KB) seront mis en cache (s'ils ne l'étaient pas déjà) et réutilisés. Même pour Postgres, cette mise en cache se produit probablement. (Je ne connais pas Postgres.) Puis le balayage de portée commence. Avec MySQL, il traverse le reste du quartier. (Règle empirique: 100 lignes par bloc.) Idem pour Postgres?
À la fin du bloc de quelque chose de différent. Pour MySQL, il y a un lien vers le bloc suivant. Ce bloc (avec 100 lignes supplémentaires) est récupéré à partir du disque (s'il n'est pas mis en cache). Pour un arbre B, les noeuds non foliaires doivent être parcourus à nouveau. 2, probablement 3 niveaux sont encore en cache. Je m'attendrais à ce que le besoin pour un autre noeud non-feuille d'être récupéré à partir du disque seulement des lignes 1/10K. (10K = 100*100) C'est-à-dire, Postgres pourrait frapper le disque 1% plus souvent que MySQL, même sur un système "froid".
par contre, si les rangées sont si grasses que seulement 1 ou 2 peuvent tenir dans un bloc de 16K, le" 100 "que j'ai continué à utiliser est plus comme" 2", et le 1% devient peut-être 50%. C'est-à-dire, si vous avez de grandes lignes cela pourrait être la "réponse" . S'agit-il?
Quelle est la taille du bloc dans Postgres? Notez que les calculs ci-dessus dépendent de la taille relative entre le bloc et la données. Cela pourrait-il être une réponse?
Conclusion: je vous ai donné 4 réponses possibles. Aimeriez-vous augmenter la question pour confirmer ou réfuter que chacun de ces s'appliquer? (Existence d'indices secondaires, grand PK, construction inefficace d'indices secondaires, grandes rangées, taille des blocs,...)
Addenda à propos de la clé primaire
pour InnoDB, autre chose à noter... Il est il est préférable d'avoir un PRIMARY KEY dans la définition du tableau avant de charger les données. Il est également préférable de trier les données dans L'ordre PK avant LOAD DATA . Sans spécifier Aucune clé PRIMARY KEY ou UNIQUE , InnoDB construit un PK caché de 6 octets, ce qui est généralement sous-optimal.
aux bases de données, vous avez souvent des requêtes qui délivre des gammes de données comme des id de 100 à 200.
Dans ce cas
- B-Tree a besoin de suivre le chemin de la racine aux feuilles pour chaque entrée simple pour obtenir le pointeur de données.
- B+ - Les Arbres peuvent "marcher" à travers les feuilles et doit suivre le chemin vers les feuilles seulement la première fois (i.e. pour le id 100)
c'est parce que B + - Trees stocke seulement les données (ou l'indicateur de données) dans les leafs et les leafs sont liés de sorte que vous pouvez effectuer un rapide dans l'ordre-transversal.
B+-Arbre
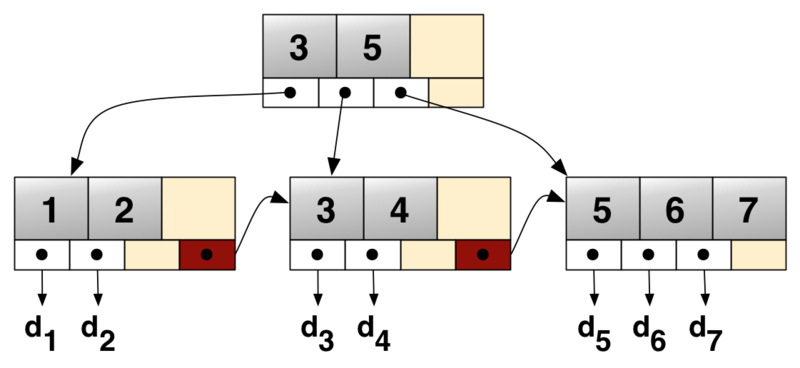
un autre point est:
Aux arbres B+les noeuds intérieurs stockent seulement le pointeur vers d'autres noeuds sans aucun pointeur de données, donc vous avez plus d'espace pour les pointeurs et vous avez besoin de moins IO-opérations et vous pouvez stocker plus de noeuds-pointeurs à une page de mémoire.
donc pour les requêtes de portée B+-Les Arbres sont la structure de données optimale. Pour les sélections simples, les arbres B peuvent être meilleurs (causes de la profondeur/taille de l'arbre), car le pointeur de données se trouve également à l'intérieur de l'arbre.
MySQL et PostgreSQL ne sont pas vraiment comparables ici Innodb utilise un indice pour stocker des données de table (et les indices secondaires pointent juste à la clé). C'est parfait pour les recherches PKEY à une seule rangée et avec les arbres B+, faites ok avec les requêtes de portée sur le champ pkey, mais avec des inconvénients de performance pour tout le reste.
PostgreSQL utilise des tables de tas et met des index comme séparé. Il prend en charge un certain nombre d'algorithmes d'indexation différents. En fonction de votre requête de plage, un arbre index peut ne pas vous aider et vous pouvez avoir besoin d'un Index GiST à la place. De même, les index GIN fonctionnent bien avec les ID favori des membres (pour les tableaux, fts, etc.).
je pense que btree est utilisé parce qu'il excelle dans le cas d'une utilisation simple: quels rooes contiennent les données suivantes? Cela devient un bloc de construction de GIN par exemple.
mais il n'est pas vrai que PostgreSQL ne peut pas utiliser les arbres B+. GiST est construit sur des index D'arbre B+ dans un format généralisé. Donc PostgreSQL vous donne l'option de utilisez les arbres B+ là où ils sont utiles.