Mauvaise performance memcpy sur Linux
nous avons récemment acheté de nouveaux serveurs et avons de mauvaises performances memcpy. La performance memcpy est 3 fois plus lente sur les serveurs que sur nos ordinateurs portables.
Serveur "Caractéristiques Techniques Des 1519200920"
- châssis et Mobo: SUPER MICRO 1027GR-TRF
- CPU: 2x Intel Xeon E5-2680 @ 2,70 Ghz
- Mémoire: 8x 16 go de mémoire DDR3 à 1 600 mhz
Edit: je teste également sur un autre serveur avec des spécifications légèrement plus élevées et voir les mêmes résultats que le serveur ci-dessus
Serveur 2 "Caractéristiques Techniques Des 1519200920"
- châssis et Mobo: SUPER MICRO 10227GR-TRFT
- CPU: 2x Intel Xeon E5-2650 v2 @ 2,6 Ghz
- Mémoire: 8x 16 go de mémoire DDR3 à 1 866 mhz
"1519190920 Portable" Specs
- Châssis: Lenovo W530
- CPU: 1x Intel Core i7 i7-3720QM @ 2,6 Ghz
- Mémoire: 4x 4 GO de mémoire DDR3 à 1 600 mhz
Système D'Exploitation
$ cat /etc/redhat-release
Scientific Linux release 6.5 (Carbon)
$ uname -a
Linux r113 2.6.32-431.1.2.el6.x86_64 #1 SMP Thu Dec 12 13:59:19 CST 2013 x86_64 x86_64 x86_64 GNU/Linux
compilateur (sur tous les systèmes)
$ gcc --version
gcc (GCC) 4.6.1
a également été testé avec gcc 4.8.2 sur la base d'une suggestion de @stefan. Il n'y a pas de différence de performances entre les compilateurs.
Code D'Essai Le code de test ci-dessous est un test en conserve pour dupliquer le problème que je vois dans notre code de production. Je sais que ce point de repère est simpliste, mais il a su exploiter et identifier notre problème. Le code crée deux tampons de 1 Go et des memcpys entre eux, chronométrant l'appel memcpy. Vous pouvez spécifier d'autres tailles de tampon sur la ligne de commande en utilisant: ./ big_memcpy_test [SIZE_BYTES]
#include <chrono>
#include <cstring>
#include <iostream>
#include <cstdint>
class Timer
{
public:
Timer()
: mStart(),
mStop()
{
update();
}
void update()
{
mStart = std::chrono::high_resolution_clock::now();
mStop = mStart;
}
double elapsedMs()
{
mStop = std::chrono::high_resolution_clock::now();
std::chrono::milliseconds elapsed_ms =
std::chrono::duration_cast<std::chrono::milliseconds>(mStop - mStart);
return elapsed_ms.count();
}
private:
std::chrono::high_resolution_clock::time_point mStart;
std::chrono::high_resolution_clock::time_point mStop;
};
std::string formatBytes(std::uint64_t bytes)
{
static const int num_suffix = 5;
static const char* suffix[num_suffix] = { "B", "KB", "MB", "GB", "TB" };
double dbl_s_byte = bytes;
int i = 0;
for (; (int)(bytes / 1024.) > 0 && i < num_suffix;
++i, bytes /= 1024.)
{
dbl_s_byte = bytes / 1024.0;
}
const int buf_len = 64;
char buf[buf_len];
// use snprintf so there is no buffer overrun
int res = snprintf(buf, buf_len,"%0.2f%s", dbl_s_byte, suffix[i]);
// snprintf returns number of characters that would have been written if n had
// been sufficiently large, not counting the terminating null character.
// if an encoding error occurs, a negative number is returned.
if (res >= 0)
{
return std::string(buf);
}
return std::string();
}
void doMemmove(void* pDest, const void* pSource, std::size_t sizeBytes)
{
memmove(pDest, pSource, sizeBytes);
}
int main(int argc, char* argv[])
{
std::uint64_t SIZE_BYTES = 1073741824; // 1GB
if (argc > 1)
{
SIZE_BYTES = std::stoull(argv[1]);
std::cout << "Using buffer size from command line: " << formatBytes(SIZE_BYTES)
<< std::endl;
}
else
{
std::cout << "To specify a custom buffer size: big_memcpy_test [SIZE_BYTES] n"
<< "Using built in buffer size: " << formatBytes(SIZE_BYTES)
<< std::endl;
}
// big array to use for testing
char* p_big_array = NULL;
/////////////
// malloc
{
Timer timer;
p_big_array = (char*)malloc(SIZE_BYTES * sizeof(char));
if (p_big_array == NULL)
{
std::cerr << "ERROR: malloc of " << SIZE_BYTES << " returned NULL!"
<< std::endl;
return 1;
}
std::cout << "malloc for " << formatBytes(SIZE_BYTES) << " took "
<< timer.elapsedMs() << "ms"
<< std::endl;
}
/////////////
// memset
{
Timer timer;
// set all data in p_big_array to 0
memset(p_big_array, 0xF, SIZE_BYTES * sizeof(char));
double elapsed_ms = timer.elapsedMs();
std::cout << "memset for " << formatBytes(SIZE_BYTES) << " took "
<< elapsed_ms << "ms "
<< "(" << formatBytes(SIZE_BYTES / (elapsed_ms / 1.0e3)) << " bytes/sec)"
<< std::endl;
}
/////////////
// memcpy
{
char* p_dest_array = (char*)malloc(SIZE_BYTES);
if (p_dest_array == NULL)
{
std::cerr << "ERROR: malloc of " << SIZE_BYTES << " for memcpy test"
<< " returned NULL!"
<< std::endl;
return 1;
}
memset(p_dest_array, 0xF, SIZE_BYTES * sizeof(char));
// time only the memcpy FROM p_big_array TO p_dest_array
Timer timer;
memcpy(p_dest_array, p_big_array, SIZE_BYTES * sizeof(char));
double elapsed_ms = timer.elapsedMs();
std::cout << "memcpy for " << formatBytes(SIZE_BYTES) << " took "
<< elapsed_ms << "ms "
<< "(" << formatBytes(SIZE_BYTES / (elapsed_ms / 1.0e3)) << " bytes/sec)"
<< std::endl;
// cleanup p_dest_array
free(p_dest_array);
p_dest_array = NULL;
}
/////////////
// memmove
{
char* p_dest_array = (char*)malloc(SIZE_BYTES);
if (p_dest_array == NULL)
{
std::cerr << "ERROR: malloc of " << SIZE_BYTES << " for memmove test"
<< " returned NULL!"
<< std::endl;
return 1;
}
memset(p_dest_array, 0xF, SIZE_BYTES * sizeof(char));
// time only the memmove FROM p_big_array TO p_dest_array
Timer timer;
// memmove(p_dest_array, p_big_array, SIZE_BYTES * sizeof(char));
doMemmove(p_dest_array, p_big_array, SIZE_BYTES * sizeof(char));
double elapsed_ms = timer.elapsedMs();
std::cout << "memmove for " << formatBytes(SIZE_BYTES) << " took "
<< elapsed_ms << "ms "
<< "(" << formatBytes(SIZE_BYTES / (elapsed_ms / 1.0e3)) << " bytes/sec)"
<< std::endl;
// cleanup p_dest_array
free(p_dest_array);
p_dest_array = NULL;
}
// cleanup
free(p_big_array);
p_big_array = NULL;
return 0;
}
fichier CMake pour construire
project(big_memcpy_test)
cmake_minimum_required(VERSION 2.4.0)
include_directories(${CMAKE_CURRENT_SOURCE_DIR})
# create verbose makefiles that show each command line as it is issued
set( CMAKE_VERBOSE_MAKEFILE ON CACHE BOOL "Verbose" FORCE )
# release mode
set( CMAKE_BUILD_TYPE Release )
# grab in CXXFLAGS environment variable and append c/" class="blnk">C++11 and -Wall options
set( CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++0x -Wall -march=native -mtune=native" )
message( INFO "CMAKE_CXX_FLAGS = ${CMAKE_CXX_FLAGS}" )
# sources to build
set(big_memcpy_test_SRCS
main.cpp
)
# create an executable file named "big_memcpy_test" from
# the source files in the variable "big_memcpy_test_SRCS".
add_executable(big_memcpy_test ${big_memcpy_test_SRCS})
Résultats Des Essais
Buffer Size: 1GB | malloc (ms) | memset (ms) | memcpy (ms) | NUMA nodes (numactl --hardware)
---------------------------------------------------------------------------------------------
Laptop 1 | 0 | 127 | 113 | 1
Laptop 2 | 0 | 180 | 120 | 1
Server 1 | 0 | 306 | 301 | 2
Server 2 | 0 | 352 | 325 | 2
comme vous pouvez le voir les memcpys et les memsets sur nos serveurs sont beaucoup plus lents que les memcpys et les memsets sur nos ordinateurs portables.
variing buffer sizes
j'ai essayé des tampons de 100MB à 5GB tous avec des résultats similaires (serveurs plus lent que l'ordinateur portable)
NUMA Affinity
j'ai lu au sujet des gens ayant des problèmes de performance avec NUMA donc j'ai essayé de Définir CPU et l'affinité de mémoire en utilisant numactl, mais les résultats sont restés les mêmes.
Serveur NUMA Matériel
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 0 size: 65501 MB
node 0 free: 62608 MB
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
node 1 size: 65536 MB
node 1 free: 63837 MB
node distances:
node 0 1
0: 10 21
1: 21 10
portable NUMA Hardware
$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3 4 5 6 7
node 0 size: 16018 MB
node 0 free: 6622 MB
node distances:
node 0
0: 10
Réglage de NUMA Affinité
$ numactl --cpunodebind=0 --membind=0 ./big_memcpy_test
Any nous vous sommes très reconnaissants de nous aider à résoudre ce problème.
modifier: options GCC
basé sur des commentaires que j'ai essayé de compiler avec différentes options de GCC:
de la Compilation avec -march et-mtune sur natif
g++ -std=c++0x -Wall -march=native -mtune=native -O3 -DNDEBUG -o big_memcpy_test main.cpp
Résultat: exactement la même performance (pas d'amélioration)
compilant avec-O2 au lieu de-O3
g++ -std=c++0x -Wall -march=native -mtune=native -O2 -DNDEBUG -o big_memcpy_test main.cpp
Résultat: même performance exacte (aucune amélioration)
Edit: change memset pour écrire 0xF au lieu de 0 pour éviter la page nulle (@SteveCox)
pas d'amélioration lors de la mémorisation avec une valeur autre que 0 (utilisé 0xF dans ce cas).
Edit: Cachebench results
afin d'exclure que mon programme de test soit trop simpliste, j'ai téléchargé un véritable benchmarking programme LLCacheBench ( ) http://icl.cs.utk.edu/projects/llcbench/cachebench.html )
j'ai construit le benchmark sur chaque machine séparément pour éviter les problèmes d'architecture. Ci-dessous sont mes résultats.
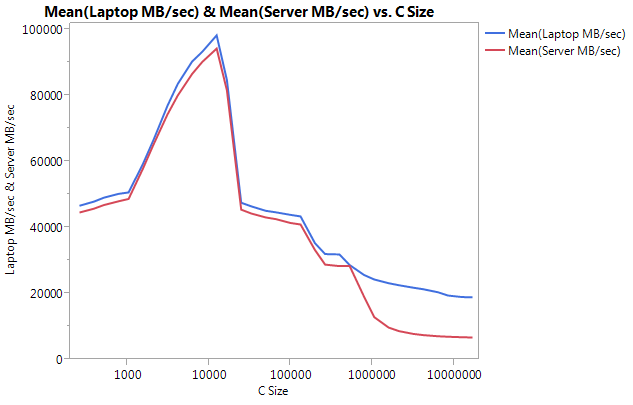
remarquez que la très grande différence est la performance sur les plus grandes tailles de tampons. La dernière taille testée (16777216) effectué à 18849.29 MB / sec sur l'ordinateur portable et 6710.40 sur le serveur. C'est à peu près 3 fois la différence de performance. Vous pouvez également remarquer que le déclin des performances du serveur est beaucoup plus prononcé que sur l'ordinateur portable.
Edit: memmove() est 2x plus RAPIDE que memcpy() sur le serveur
basé sur quelques expérimentations j'ai essayé d'utiliser memmove() au lieu de memcpy() dans mon cas de test et j'ai trouvé une amélioration 2x sur le serveur. Memmove() sur le portable fonctionne plus lentement que memcpy (), mais bizarrement assez court à la même vitesse que le memmove() sur le serveur. Cela nous amène à la question: pourquoi memcpy est-il si lent?
code mis à jour pour tester memmove avec memcpy. J'ai dû envelopper le memmove() à l'intérieur d'une fonction parce que si je l'avais laissé inline GCC l'avait optimisé et exécuté exactement le même que memcpy() (je suppose que gcc l'avait optimisé pour memcpy parce qu'il savait que les emplacements ne se chevauchaient pas).
Résultats Actualisés
Buffer Size: 1GB | malloc (ms) | memset (ms) | memcpy (ms) | memmove() | NUMA nodes (numactl --hardware)
---------------------------------------------------------------------------------------------------------
Laptop 1 | 0 | 127 | 113 | 161 | 1
Laptop 2 | 0 | 180 | 120 | 160 | 1
Server 1 | 0 | 306 | 301 | 159 | 2
Server 2 | 0 | 352 | 325 | 159 | 2
Edit: Naïve Memcpy
basé sur la suggestion de @Salgar j'ai mis en œuvre ma propre fonction naïve memcpy et je l'ai testé.
Source Naïve Memcpy
void naiveMemcpy(void* pDest, const void* pSource, std::size_t sizeBytes)
{
char* p_dest = (char*)pDest;
const char* p_source = (const char*)pSource;
for (std::size_t i = 0; i < sizeBytes; ++i)
{
*p_dest++ = *p_source++;
}
}
Naïf Memcpy des Résultats par Rapport à memcpy()
Buffer Size: 1GB | memcpy (ms) | memmove(ms) | naiveMemcpy()
------------------------------------------------------------
Laptop 1 | 113 | 161 | 160
Server 1 | 301 | 159 | 159
Server 2 | 325 | 159 | 159
Edit: Assemblée De Sortie
Simple memcpy source
#include <cstring>
#include <cstdlib>
int main(int argc, char* argv[])
{
size_t SIZE_BYTES = 1073741824; // 1GB
char* p_big_array = (char*)malloc(SIZE_BYTES * sizeof(char));
char* p_dest_array = (char*)malloc(SIZE_BYTES * sizeof(char));
memset(p_big_array, 0xA, SIZE_BYTES * sizeof(char));
memset(p_dest_array, 0xF, SIZE_BYTES * sizeof(char));
memcpy(p_dest_array, p_big_array, SIZE_BYTES * sizeof(char));
free(p_dest_array);
free(p_big_array);
return 0;
}
Assemblée de Sortie: C'est exactement la même sur le serveur et l'ordinateur portable. J'économise de l'espace et je ne colle pas les deux.
.file "main_memcpy.cpp"
.section .text.startup,"ax",@progbits
.p2align 4,,15
.globl main
.type main, @function
main:
.LFB25:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movl 73741824, %edi
pushq %rbx
.cfi_def_cfa_offset 24
.cfi_offset 3, -24
subq , %rsp
.cfi_def_cfa_offset 32
call malloc
movl 73741824, %edi
movq %rax, %rbx
call malloc
movl 73741824, %edx
movq %rax, %rbp
movl , %esi
movq %rbx, %rdi
call memset
movl 73741824, %edx
movl , %esi
movq %rbp, %rdi
call memset
movl 73741824, %edx
movq %rbx, %rsi
movq %rbp, %rdi
call memcpy
movq %rbp, %rdi
call free
movq %rbx, %rdi
call free
addq , %rsp
.cfi_def_cfa_offset 24
xorl %eax, %eax
popq %rbx
.cfi_def_cfa_offset 16
popq %rbp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE25:
.size main, .-main
.ident "GCC: (GNU) 4.6.1"
.section .note.GNU-stack,"",@progbits
PROGRESS!!!! asmlib
basé sur la suggestion de @tbenson j'ai essayé de courir avec la version asmlib de memcpy. Au départ, mes résultats étaient mauvais, mais après avoir changé SetMemcpyCacheLimit () en 1 Go (Taille de mon tampon), je courais à vitesse égale avec ma naïve pour boucle!
la mauvaise nouvelle est que la version asmlib de memmove est plus lente que la version glibc, elle tourne maintenant à 300ms (sur le même pied que la version glibc de memcpy). Chose étrange est que sur l'ordinateur portable quand je Metmemcpycachelimit() à un grand nombre, il blesse la performance...
dans les résultats au-dessous des lignes marquées avec SetCache ont SetMemcpyCacheLimit réglé à 1073741824. Les résultats sans SetCache n'appellent pas SetMemcpyCacheLimit()
résultats utilisant les fonctions de asmlib:
Buffer Size: 1GB | memcpy (ms) | memmove(ms) | naiveMemcpy()
------------------------------------------------------------
Laptop | 136 | 132 | 161
Laptop SetCache | 182 | 137 | 161
Server 1 | 305 | 302 | 164
Server 1 SetCache | 162 | 303 | 164
Server 2 | 300 | 299 | 166
Server 2 SetCache | 166 | 301 | 166
commence à pencher vers la question de cache, mais qu'est-ce qui causerait cela?
7 réponses
[je ferait un commentaire, mais n'ont pas assez de réputation pour le faire.]
j'ai un système similaire et voir des résultats similaires, mais peut ajouter quelques points de données:
- si vous inversez la direction de votre naïve
memcpy(i.e. convertir en*p_dest-- = *p_src--), alors vous pouvez obtenir des performances bien pires que pour la direction avant (~637 ms pour moi). Il y a eu un changement dansmemcpy()dans glibc 2.12 qui a exposé plusieurs bogues pour avoir appelémemcpysur des tampons qui se chevauchent ( http://lwn.net/Articles/414467 / ) et je crois que le problème a été causé par le passage à une version dememcpyqui fonctionne à l'envers. Ainsi, les copies vers l'arrière versus les copies vers l'avant peuvent expliquer la disparitémemcpy()/memmove(). - il semble préférable de ne pas utiliser de réserves non temporelles. De nombreuses implémentations optimisées
memcpy()passent à des magasins non temporels (qui ne sont pas mis en cache) pour les grandes tampons (c.-à-d. plus gros que le dernier niveau de cache). J'ai testé la version D'Agner Fog de memcpy ( http://www.agner.org/optimize/#asmlib ) et a trouvé qu'il était à peu près la même vitesse que la version dansglibc. Cependant,asmliba une fonction (SetMemcpyCacheLimit) qui permet de fixer le seuil au-dessus duquel les stocks non temporels sont utilisés. Le réglage de cette limite à 8GiB (ou juste plus grand que le tampon de 1 GiB) pour éviter les stocks non-temporels doublé la performance dans mon cas (délai à 176ms). Bien sûr, cela n'a fait que correspondre à la performance naïve de la direction avant, donc ce n'est pas stellaire. - le BIOS de ces systèmes permet d'activer/désactiver quatre préfetchers matériels différents (MLC Streamer Prefetcher, MLC Spatial Prefetcher, DCU Streamer Prefetcher, et DCU IP Prefetcher). J'ai essayé de les désactiver tous, mais en le faisant au mieux, j'ai maintenu la parité des performances et réduit les performances pour quelques-uns des réglages.
- La désactivation du mode de limitation de puissance moyenne (RAPL) n'a aucun impact.
- j'ai accès à D'autres systèmes Supermicro fonctionnant Fedora 19 (glibc 2.17). Avec une carte Supermicro X9DRG-HF, Fedora 19, et Xeon E5-2670 CPU, je vois des performances similaires comme ci-dessus. Sur un Supermicro X10SLM-F Single socket board tournant un Xeon E3-1275 v3 (Haswell) et Fedora 19, je vois 9.6 GB/s pour
memcpy(104ms). La mémoire vive du système Haswell est le DDR3-1600 (identique aux autres systèmes).
MISES à jour
- j'ai réglé la gestion de la puissance du CPU sur la Performance maximale et l'hyperthreading désactivé dans le BIOS. Sur la base de
/proc/cpuinfo, les noyaux ont ensuite été cochés à 3 GHz. Cependant, cette performance de mémoire a diminué d'environ 10%. - memtest86+ 4.10 rapporte une bande passante de 9091 MB/s vers la mémoire principale. Je n'ai pas pu trouver si cela correspond à lire, écrire ou copier.
- Le FLUX "de référence", 1519200920" rapports 13422 MO/s pour le copier, mais ils le nombre d'octets comme à la fois de lire et d'écrire, donc qui correspond à ~6.5 GO/s si l'on veut comparer les résultats ci-dessus.
ça me semble normal.
gérer des clés de mémoire ECC 8x16GB avec deux CPU est beaucoup plus difficile qu'un seul CPU avec 2x2GB. Vos bâtons de 16 Go sont mémoire Double face + ils peuvent avoir des tampons + ECC (même désactivé au niveau de la carte mère)... tout cela rend le chemin de données vers la RAM beaucoup plus long. Vous avez aussi 2 CPU partageant la ram, et même si vous ne faites rien sur l'autre CPU, il y a toujours peu d'accès mémoire. La commutation de ces données nécessite un certain temps supplémentaire. Juste regardez l'énorme performance perdue sur les PC qui partagent une mémoire vive avec une carte graphique.
vos severs sont toujours très puissants. Je ne suis pas sûr que dupliquer 1 GO se produit très souvent dans les logiciels de la vie réelle, mais je suis sûr que vos 128GB sont beaucoup plus rapides que n'importe quel disque dur, même le meilleur SSD et c'est là que vous pouvez profiter de vos serveurs. Faire le même test avec 3GB va mettre le feu à votre ordinateur portable.
Cela ressemble à l'exemple parfait de la comment une architecture basée sur du matériel de base pourrait être beaucoup plus efficace que de gros serveurs. Combien de consommateurs Pc pourrait-on se permettre avec l'argent dépensé sur ces gros serveurs ?
Merci pour votre question très détaillée.
EDIT: (cela m'a pris tellement de temps pour écrire cette réponse que j'ai manqué la partie graphique.)
je pense que le problème est l'endroit où les données sont stockées. Pouvez vous s'il vous plaît de comparer ce :
- test one: attribuez deux blocs contigus de 500 Mo de mémoire vive et copiez de l'un à l'autre (ce que vous avez déjà fait)
- test deux: attribuer 20 (ou plus) blocs de 500 Mo de mémoire et de copie forment la première à la dernière, de sorte qu'ils sont loin l'un de l'autre (même si vous ne pouvez pas être sûr de leur position réelle).
de cette façon, vous verrez comment le contrôleur de mémoire gère les blocs de mémoire loin l'un de l'autre. Je pensez que vos données sont placées sur différentes zones de mémoire et il nécessite une opération de commutation à un moment donné sur le chemin de données pour parler avec une zone puis l'autre (il ya un tel problème avec la mémoire Double face).
de plus, vous assurez-vous que le fil est relié à un CPU ?
EDIT 2:
il existe plusieurs sortes de délimiteur de" zones " pour mémoire. NUMA est un, mais ce n'est pas le seul. Exemple les bâtons à deux côtés nécessitent un drapeau pour s'adresser à l'un ou l'autre côté. Regardez sur votre graphique comment la performance se dégrade avec un gros morceau de mémoire, même sur l'ordinateur portable (qui n'a pas de NUMA). Je ne suis pas sûr de cela, mais memcpy peut utiliser une fonction matérielle pour copier la ram (une sorte de DMA) et cette puce doit avoir moins de cache que votre CPU, cela pourrait expliquer pourquoi la copie muette avec CPU est plus rapide que memcpy.
il est possible que certaines améliorations de CPU dans votre ordinateur portable basé à IvyBridge contribuent à ce gain sur les serveurs basés à SandyBridge.
-
page-crossing Prefetch - votre CPU ordinateur portable préfetch en avant de la page linéaire suivante chaque fois que vous atteignez la fin de L'actuel, vous épargner une vilaine TLB manquer à chaque fois. Pour essayer d'atténuer cela, essayez de construire votre code de serveur pour les pages 2M / 1g.
-
les schémas de remplacement de Cache semblent également avoir été améliorés (voir une intéressante rétro-ingénierie ici ). Si en effet ce CPU utilise une politique d'insertion dynamique, il empêchera facilement vos données copiées d'essayer de battre votre Cache de dernier niveau (qu'il ne peut pas utiliser efficacement de toute façon en raison de la taille), et sauvera la pièce pour d'autres cache utiles comme le code, la pile, les données de table de page, etc..). Pour tester ceci, vous pourriez essayer de reconstruire votre naïf mise en œuvre en utilisant des charges/magasins de streaming (
movntdqou similaires, vous pouvez également utiliser gcc builtin pour cela). Cette possibilité pourrait expliquer la chute soudaine des grands ensembles de données. -
je crois que certaines améliorations ont aussi été apportées avec string-copy ( ici ), cela peut ou non s'appliquer ici, selon l'apparence de votre code d'assemblage. Vous pouvez essayer l'étalonnage avec Dhrystone pour tester si il y a une différence inhérente. Cela peut aussi expliquer la différence entre memcpy et memmove.
si vous pouviez mettre la main sur un serveur basé à IvyBridge ou un ordinateur portable Sandy-Bridge, il serait plus simple de tester tout cela ensemble.
j'ai modifié le benchmark pour utiliser la minuterie nsec sous Linux et j'ai trouvé des variations similaires sur différents processeurs, tous avec une mémoire similaire. Tous les RHEL 6. Les nombres sont constants pour plusieurs passages.
Sandy Bridge E5-2648L v2 @ 1.90GHz, HT enabled, L2/L3 256K/20M, 16 GB ECC
malloc for 1073741824 took 47us
memset for 1073741824 took 643841us
memcpy for 1073741824 took 486591us
Westmere E5645 @2.40 GHz, HT not enabled, dual 6-core, L2/L3 256K/12M, 12 GB ECC
malloc for 1073741824 took 54us
memset for 1073741824 took 789656us
memcpy for 1073741824 took 339707us
Jasper Forest C5549 @ 2.53GHz, HT enabled, dual quad-core, L2 256K/8M, 12 GB ECC
malloc for 1073741824 took 126us
memset for 1073741824 took 280107us
memcpy for 1073741824 took 272370us
Sandy Bridge E5-2648L v2 @ 1.90GHz, HT enabled, 256K/20M, 16 GB
malloc for 1 GB took 46 us
memset for 1 GB took 478722 us
memcpy for 1 GB took 262547 us
Westmere E5645 @2.40 GHz, HT not enabled, dual 6-core, 256K/12M, 12 GB
malloc for 1 GB took 53 us
memset for 1 GB took 681733 us
memcpy for 1 GB took 258147 us
Jasper Forest C5549 @ 2.53GHz, HT enabled, dual quad-core, 256K/8M, 12 GB
malloc for 1 GB took 67 us
memset for 1 GB took 254544 us
memcpy for 1 GB took 255658 us
Pour le fun, j'ai aussi essayé de faire la ligne memcpy faire 8 octets à la fois. Sur ces processeurs Intel, cela n'a fait aucune différence notable. Cache fusionne tous l'octet opérations dans le nombre minimum d'opérations de mémoire. Je pense que le code de la bibliothèque gcc essaie d'être trop intelligent.
la question a déjà été répondue au-dessus de , mais dans tous les cas, voici une implémentation utilisant AVX qui devrait être plus rapide pour les grandes copies si c'est ce qui vous inquiète:
#define ALIGN(ptr, align) (((ptr) + (align) - 1) & ~((align) - 1))
void *memcpy_avx(void *dest, const void *src, size_t n)
{
char * d = static_cast<char*>(dest);
const char * s = static_cast<const char*>(src);
/* fall back to memcpy() if misaligned */
if ((reinterpret_cast<uintptr_t>(d) & 31) != (reinterpret_cast<uintptr_t>(s) & 31))
return memcpy(d, s, n);
if (reinterpret_cast<uintptr_t>(d) & 31) {
uintptr_t header_bytes = 32 - (reinterpret_cast<uintptr_t>(d) & 31);
assert(header_bytes < 32);
memcpy(d, s, min(header_bytes, n));
d = reinterpret_cast<char *>(ALIGN(reinterpret_cast<uintptr_t>(d), 32));
s = reinterpret_cast<char *>(ALIGN(reinterpret_cast<uintptr_t>(s), 32));
n -= min(header_bytes, n);
}
for (; n >= 64; s += 64, d += 64, n -= 64) {
__m256i *dest_cacheline = (__m256i *)d;
__m256i *src_cacheline = (__m256i *)s;
__m256i temp1 = _mm256_stream_load_si256(src_cacheline + 0);
__m256i temp2 = _mm256_stream_load_si256(src_cacheline + 1);
_mm256_stream_si256(dest_cacheline + 0, temp1);
_mm256_stream_si256(dest_cacheline + 1, temp2);
}
if (n > 0)
memcpy(d, s, n);
return dest;
}
les chiffres ont du sens pour moi. Il y a en fait deux questions ici, et je vais y répondre toutes les deux.
tout d'abord, nous avons besoin d'avoir un modèle mental de la taille de 1 transferts de mémoire fonctionnent sur quelque chose comme un processeur Intel moderne. Cette description est approximative et les détails peuvent changer un peu de l'architecture à l'architecture, mais les idées de haut niveau sont assez constants.
- Lorsqu'un chargement manque dans le cache de données
L1, un tampon de ligne est alloué qui suivra la demande de miss jusqu'à ce qu'elle soit remplie. Cela peut être pour une courte période (Une douzaine de cycles ou plus) si elle frappe dans le cacheL2, ou beaucoup plus longtemps (100+ nanosecondes) si elle manque tout le chemin vers DRAM. - il y a un nombre limité de ces tampons de ligne par âme 1 , et une fois qu'ils sont plein, d'autres ratés vont attendre un peu.
- autres que ces tampons de remplissage utilisés pour la demande 3 charges / emmagasins il existe des tampons supplémentaires pour le mouvement de mémoire entre DRAM et L2 et les caches de niveau inférieur utilisés pour le prédécoupage.
-
le sous-système de mémoire lui-même a une limite de bande passante maximale , que vous trouverez facilement listé sur ARK. Par exemple, l' 3720QM dans le Lenovo ordinateur portable montre une limite de 25,6 GB . Cette limite est essentiellement le produit de la fréquence effective (
1600 Mhz) fois 8 octets (64 bits) par transfert fois le nombre de canaux (2):1600 * 8 * 2 = 25.6 GB/s. La puce de serveur sur la main a une bande passante de pointe de 51,2 GB/s , par socket, pour une bande passante totale du système de ~102 GB / s.contrairement à d'autres caractéristiques de processeur, Il ya souvent seulement un possible théorique les nombres de bande passante à travers toute la variété de puces, depuis elle dépend uniquement des valeurs notées, qui sont souvent les mêmes dans de nombreux cas. différentes puces, et même à travers les architectures. Il n'est pas réaliste s'attendre DRAM à livrer à exactement le taux théorique (en raison de divers préoccupations de bas niveau, discuté un peu ici ), mais vous pouvez obtenir près de 90% ou plus.
donc la principale conséquence de (1) est que vous pouvez traiter les erreurs pour la RAM, comme une sorte de réponse à la requête de système. Une miss à la DRAM alloue un de remplissage de la mémoire tampon et le tampon est libérée lorsque la demande est de retour. Il n'y a que 10 de ces tampons, par CPU, pour les pannes de demande, ce qui met une limite stricte sur la bande passante mémoire de demande qu'un seul CPU peut générer, en fonction de sa latence.
par exemple, disons que votre E5-2680 a une latence de DRAM de 80ns. Chaque demande apporte une ligne de cache de 64 octets, donc vous venez d'envoyer des requêtes en série à DRAM, vous vous attendriez à un débit d'un minuscule 64 bytes / 80 ns = 0.8 GB/s , et vous couperiez cela de nouveau en deux (au moins) pour obtenir un chiffre memcpy puisqu'il a besoin de lire et écrire. Heureusement, vous pouvez Vos 10 tampons de remplissage de ligne, de sorte que vous pouvez chevaucher 10 requêtes simultanées à la mémoire et augmenter la bande passante d'un facteur de 10, conduisant à une bande passante théorique de 8 Go/s.
si vous voulez creuser dans encore plus de détails, ce fil est à peu près d'or pur. Vous constaterez que les faits et les chiffres de John McCalpin, alias "Dr Bandwidth seront un thème commun ci-dessous.
alors entrons dans les détails et répondons aux deux questions...
pourquoi memcpy est-il tellement plus lent que memmove ou la copie manuelle sur le serveur?
vous avez montré que vous les systèmes d'ordinateur portable faire le memcpy benchmark dans environ 120 ms , tandis que les pièces du serveur prennent 300 ms . Vous avez également montré que cette lenteur la plupart du temps n'est pas fondamentale puisque vous avez été en mesure d'utiliser memmove et votre main-roulé-memcpy (ci-après, hrm ) pour atteindre un temps d'environ 160 ms , beaucoup plus proche (mais encore plus lent que) la performance de l'ordinateur portable.
nous avons déjà montré ci-dessus que pour un noyau simple, la largeur de bande est limitée par la simultanéité et la latence totales disponibles, plutôt que par la largeur de bande DRAM. Nous nous attendons à ce que les parties du serveur aient une latence plus longue, mais pas 300 / 120 = 2.5x plus longtemps!
La réponse se trouve dans streaming (aka non temporelle) des magasins . La version libc de memcpy que vous utilisez les utilise, mais memmove ne le fait pas. Vous avez confirmé avec votre "naïf " memcpy qui ne les utilise pas non plus, ainsi que mon configurer asmlib à la fois pour utiliser les stocks de diffusion en continu (lent) et pas (rapide).
La streaming les magasins du mal à la UC les chiffres, parce que:
- (A) ils empêchent le préfetching d'introduire les lignes à stocker dans le cache, ce qui permet plus de concurrence depuis le matériel de préfetching a d'autres tampons dédiés au-delà de 10 tampons de remplissage qui exigent la charge / l'utilisation des magasins.
- (B) le E5-2680 est connu pour être particulièrement lent pour les magasins de diffusion en continu.
les deux questions sont mieux expliquées par des citations de John McCalpin dans le fil relié ci-dessus. Sur le thème de l'efficacité de préfetch et les magasins de streaming il dit :
avec les magasins "ordinaires", L2 Quincaillerie préfetcher peut récupérer les lignes avancer et réduire le temps d'occupation des tampons de remplissage de ligne, augmentant ainsi la bande passante soutenue. D'autre part, avec les magasins de streaming (cache-bypassing), la ligne remplissent les entrées de tampon pour les stocks sont occupés à plein temps pour transmettre les données à le contrôleur de DRAM. Dans ce cas, les charges peuvent être accélérées par préfetching matériel, mais les magasins ne peuvent pas, donc vous obtenez une certaine accélération, mais pas autant comme vous le feriez si les charges et les magasins étaient accéléré.
... et puis pour la latence apparemment beaucoup plus longue pour les magasins de streaming sur L'E5, il dit :
le plus simple "uncore" du Xeon E3 pourrait conduire à Occupation de la zone tampon de remplissage de ligne pour les magasins de diffusion en continu. Le Xeon E5 a un structure de l'anneau beaucoup plus complexe pour naviguer afin de stockage en continu à partir des tampons de base vers les contrôleurs de mémoire, donc l'occupation peut différer d'un facteur plus important que la mémoire (lire) le temps de latence.
en particulier, le Dr McCalpin a mesuré un ralentissement d'environ 1,8 x pour E5 par rapport à une puce avec le "client" uncore, mais le ralentissement de 2,5 x les rapports de L'OP est compatible avec cela puisque la note de 1,8 x est rapportée pour STREAM TRIAD, qui a un rapport de 2:1 charges:magasins, tandis que memcpy est à 1:1, et les magasins sont la partie problématique.
cela ne fait pas de la diffusion en continu une mauvaise chose - en effet, vous échangez la latence pour une plus petite consommation totale de bande passante. Vous obtenez moins de bande passante parce que vous êtes limité par la concurrence lorsque vous utilisez un seul noyau, mais vous évitez tout le trafic de lecture-propriété, donc vous verriez probablement un (petit) avantage si vous exécutez le test simultanément sur tous les noyaux.
si loin d'être un artefact de votre logiciel ou matériel les mêmes ralentissements ont été rapportés par d'autres utilisateurs, avec le même CPU.
pourquoi la partie serveur est-elle encore plus lente lorsque vous utilisez les magasins ordinaires?
même après avoir corrigé la question non-temporal store, vous êtes encore voir à peu près un 160 / 120 = ~1.33x ralentissement sur les pièces du serveur. Ce qui donne?
Eh bien, c'est une erreur courante que les CPU du serveur soient plus rapides tous les Respect plus rapide ou au moins égal à leurs homologues clients. Ce n'est tout simplement pas vrai - ce que vous payez pour (souvent à $2,000 une puce ou ainsi) sur les parties du serveur est la plupart du temps (a) plus de noyaux (b) Plus de canaux de mémoire (c) prise en charge pour plus de RAM total (d) prise en charge pour "enterprise-ish" fonctionnalités comme ECC, virutalization features, etc 5 .
en fait, du point de vue de la latence, les parties du serveur ne sont généralement égales ou plus lentes que pour leur client 4 des pièces. Quand il s'agit de la latence de mémoire, c'est particulièrement vrai, parce que:
- les parties du serveur ont un "uncore" plus évolutif, mais complexe qui nécessite souvent de supporter beaucoup plus de noyaux et par conséquent le chemin vers la RAM est plus long.
- les parties du serveur supportent plus de RAM (100s de GB ou quelques TB) qui nécessite souvent tampons électriques pour supporter une telle quantité.
- Comme dans le cas de L'OP, les parties du serveur sont généralement multi-socket, ce qui ajoute des problèmes de cohérence entre les sockets au chemin de mémoire.
il est donc typique que les parties du serveur ont une latence de 40% à 60% plus longue que les parties du client. Pour le E5, vous trouverez probablement que ~80 ns est un latence typique à la mémoire vive, tandis que les parties du client sont plus proches de 50 ns.
donc tout ce qui est limité par la latence de la RAM s'exécute plus lentement sur le serveur pièces, et comme il s'avère, memcpy sur un seul noyau est la latence contrainte. c'est confus parce que memcpy semble comme une mesure de bande passante, non? Comme décrit ci-dessus , un seul noyau ne dispose pas de suffisamment de ressources pour garder suffisamment de requêtes RAM en vol à la fois pour se rapprocher de la bande passante de la RAM 6 , donc la performance dépend directement de la latence.
Le client puces, sur d'un autre côté, la latence est plus faible et la bande passante plus faible, de sorte qu'un noyau est beaucoup plus proche de la saturation de la bande passante (c'est souvent la raison pour laquelle les magasins de diffusion en continu sont une grande source de gains pour les clients - lorsque même un seul noyau peut se rapprocher de la bande passante de la mémoire vive, la réduction de 50% de la bande passante offerte par les magasins de diffusion en continu est très utile.
Références
Il ya beaucoup de bonnes sources pour lire plus sur ce genre de choses, voici un couple.
- Une description détaillée de la latence de la mémoire des composants
- Beaucoup de mémoire, résultats de latence entre les Processeurs nouvelles et anciennes (voir le
MemLatX86etNewMemLat) des liens - analyse Détaillée de Sandy Bridge (et Opteron) mémoire latences - près de la même puce que l'OP.
1 Par grand je veux juste dire un peu plus grand que la LLC. Pour les copies qui correspondent au niveau LLC (ou à tout niveau de cache supérieur), le comportement est très différent. Le graphique OPs llcachebench montre qu'en fait l'écart de performance ne commence que lorsque les tampons commencent à dépasser la taille LLC.
2 en particulier, le nombre de tampons de remplissage de ligne a apparemment constante à 10 depuis plusieurs générations, y compris les architectures mentionnées dans cette question.
3 lorsque nous disons demand ici, nous voulons dire qu'il est associé à une charge/emmagasin explicite dans le code, plutôt que de dire être apporté par un préfetch.
4 quand je me réfère à un serveur partie ici, je veux dire un CPU avec un serveur non nominal . Cela signifie en grande partie la série E5, comme la série E3 généralement utilise le client uncore .
5 à l'avenir, il semble que vous puissiez ajouter "instruction set extensions" à cette liste, car il semble que AVX-512 n'apparaîtra que sur les parties du serveur Skylake.
6 par little law à une latence de 80 ns, nous aurions besoin de (51.2 B/ns * 80 ns) == 4096 bytes ou 64 lignes de cache en vol à tout moment pour atteindre la bande passante maximale, mais un noyau fournit moins de 20.
Serveur 1 "Caractéristiques Techniques Des 1519200920"
- CPU: 2x Intel Xeon E5-2680 @ 2,70 Ghz
Serveur 2 "Caractéristiques Techniques Des 1519200920"
- CPU: 2x Intel Xeon E5-2650 v2 @ 2.6 Ghz
selon Intel ARK, les deux E5-2650 et E5-2680 ont l'extension AVX.
fichier CMake pour la construction
C'est une partie de votre problème. CMake choisit des drapeaux plutôt pauvres pour vous. Vous pouvez le confirmer en exécutant make VERBOSE=1 .
vous devez ajouter -march=native et -O3 à vos CFLAGS et CXXFLAGS . Vous allez probablement assister à une augmentation spectaculaire des performances. Il devrait engager les extensions AVX. Sans -march=XXX , vous obtenez effectivement une machine minimale i686 ou x86_64. Sans -O3 , vous n'engagez pas les vectorisations de GCC.
Je ne sais pas si GCC 4.6 est capable D'AVX (et ses amis, comme BMI). Je sais que GCC 4.8 ou 4.9 est capable parce que j'ai dû traquer un bug d'alignement qui causait un segfault quand GCC externalisait memcpy et memset à L'unité MMX. AVX et AVX2 permettent au CPU de fonctionner sur des blocs de données de 16 octets et de 32 octets à la fois.
si GCC manque une occasion d'envoyer des données alignées au MMX unit, il peut manquer le fait que les données sont alignées. Si vos données sont alignées de 16 octets, alors vous pouvez essayer de le dire à GCC pour qu'il sache opérer sur des blocs gras. Pour cela, voir GCC __builtin_assume_aligned . Voir aussi des questions comme Comment dire à GCC qu'un argument pointeur est toujours double-mot-aligné?
cela semble aussi un petit suspect à cause du void* . Son genre de jeter des informations sur le pointeur. Vous devrait probablement conserver l'information:
void doMemmove(void* pDest, const void* pSource, std::size_t sizeBytes)
{
memmove(pDest, pSource, sizeBytes);
}
peut-être quelque chose comme:
template <typename T>
void doMemmove(T* pDest, const T* pSource, std::size_t count)
{
memmove(pDest, pSource, count*sizeof(T));
}
une autre suggestion est d'utiliser new , et d'arrêter d'utiliser malloc . Son Programme A C++ et GCC peut faire quelques hypothèses sur new qu'il ne peut pas faire sur malloc . Je crois que certaines des hypothèses sont détaillées dans la page d'option de GCC pour les built-ins.
encore une autre suggestion est de utilisez le tas. Ses 16 octets sont toujours alignés sur les systèmes modernes typiques. GCC devrait reconnaître qu'il peut décharger à L'unité MMX quand un pointeur du tas est impliqué (sans les problèmes potentiels void* et malloc ).
enfin, pendant un certain temps, Clang n'a pas utilisé les extensions CPU natives en utilisant -march=native . Voir, par exemple, Ubuntu Issue 1616723, Clang 3.4 seulement annonces SSE2 , Ubuntu Issue 1616723, Clang 3.5 seulement annonce SSE2 , et Ubuntu Question 1616723, Clang 3.6 seul fait de la publicité SSE2 .