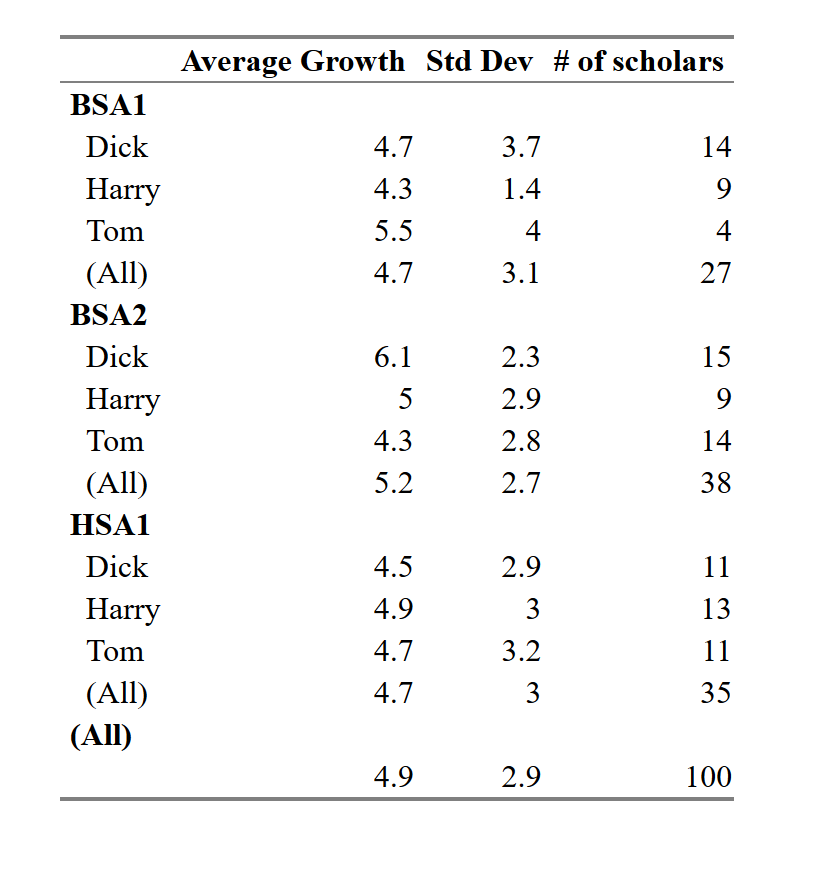
Tableau croisé dynamique-comme Sortie dans R?
je suis en train de rédiger un rapport qui nécessite la génération D'un certain nombre de tables pivotantes dans Excel. Je voudrais penser qu'il y a un moyen de le faire à R afin que je puisse éviter Excel. Je voudrais la sortie comme la capture d'écran ci-dessous (noms des enseignants expurgés). Pour autant que je sache, je pourrais utiliser le paquet reshape pour calculer les valeurs agrégées, mais j'aurais besoin de le faire un certain nombre de fois et d'une façon ou d'une autre obtenir toutes les données dans le bon ordre. À ce moment-là, je devrais juste le faire en Excel. Personne ne avez des suggestions ou des recommandations de paquets? Je vous remercie!
(EDIT) Les données commencent par une liste des élèves, de leur enseignant, de l'école et de la croissance. Ces données sont ensuite agrégées pour obtenir une liste des enseignants avec leur croissance moyenne. Veuillez noter que les enseignants sont ensuite regroupés par l'école. Le plus grand problème que je prévois de faire cela avec R dès maintenant est comment obtenir le total partiel et les lignes totales (BSA1 Total, Grand Total, etc) là-dedans car ils ne sont pas le même type d'observation que le les autres? Vous le faire manuellement à calculer eux et essayer de les faire dans le bon ordre afin qu'ils apparaissent au bas de ce groupe?

4 réponses
Voici un swag au calcul de bits:
set.seed(1)
school <- sample(c("BSA1", "BSA2", "HSA1"), 100, replace=T)
teacher <- sample(c("Tom", "Dick", "Harry"), 100, replace=T)
growth <- rnorm(100, 5, 3)
myDf <- data.frame(school, teacher, growth)
require(reshape2)
aggregate(growth ~ school + teacher, data =myDf, FUN=mean)
myDf.melt <- melt(myDf, measured="growth")
dcast(myDf.melt, school + teacher ~ ., fun.aggregate=mean, margins=c("school", "teacher"))
Je n'ai pas abordé le formatage de sortie, seulement le calcul. La base de données résultante devrait ressembler à ceci:
school teacher NA
1 BSA1 Dick 4.663140
2 BSA1 Harry 4.310802
3 BSA1 Tom 5.505247
4 BSA1 (all) 4.670451
5 BSA2 Dick 6.110988
6 BSA2 Harry 5.007221
7 BSA2 Tom 4.337063
8 BSA2 (all) 5.196018
9 HSA1 Dick 4.508610
10 HSA1 Harry 4.890741
11 HSA1 Tom 4.721124
12 HSA1 (all) 4.717335
13 (all) (all) 4.886576
cet exemple utilise le paquet reshape2 pour gérer les sous-totaux.
je pense que R est le bon outil pour le travail ici. Je peux totalement comprendre ne pas être sûr de la façon de commencer sur cette analyse. Je suis venu à R D'Excel il ya quelques années et il peut être difficile à grok au début. Permettez-moi de soulignez quatre conseils pro pour vous aider à obtenir de meilleures réponses dans le débordement de la pile:
1) fournir des données, même si simulé: vous pouvez le voir, j'ai simulé certaines données au début de ma réponse. Si vous aviez fourni cette simulation, j'aurais a) gagné du temps b) obtenu une réponse qui utilise votre propre structure de données, pas une que j'ai imaginée et c) d'autres personnes auraient répondu. Je passe souvent des questions sans données parce que j'en ai marre de deviner les données qu'on leur dit ma réponse. sucé parce que j'ai deviné le mal.
3) continuez à demander! Nous avons tous mieux avec la pratique. Vous essayez de faire plus en R et moins en Excel, donc vous êtes clairement d'une intelligence supérieure à la moyenne. Continue D'utiliser R et de poser des questions. Ça va être plus facile dans le temps.
4) Faites attention avec vos mots quand vous décrivez des choses. Vous dites dans votre édité question, vous avez une "liste" de choses. Une liste en R est une structure de données spécifique. Je me méfie vous avez une trame de données et utilisez le terme "liste" dans un sens générique. Cela peut faire pour une certaine confusion. Il illustre également pourquoi vous voulez fournir vos propres données.
en utilisant les données simulées de JD Long, et en ajoutant le sd et les comptes:
library(reshape) # not reshape2
cast(myDf.melt, school + teacher ~ ., margins=TRUE , c(mean, sd, length))
school teacher mean sd length
1 BSA1 Dick 4.663140 3.718773 14
2 BSA1 Harry 4.310802 1.430594 9
3 BSA1 Tom 5.505247 4.045846 4
4 BSA1 (all) 4.670451 3.095980 27
5 BSA2 Dick 6.110988 2.304104 15
6 BSA2 Harry 5.007221 2.908146 9
7 BSA2 Tom 4.337063 2.789244 14
8 BSA2 (all) 5.196018 2.682924 38
9 HSA1 Dick 4.508610 2.946961 11
10 HSA1 Harry 4.890741 2.977305 13
11 HSA1 Tom 4.721124 3.193576 11
12 HSA1 (all) 4.717335 2.950959 35
13 (all) (all) 4.886576 2.873637 100
vous trouverez ci-dessous plusieurs façons différentes de générer ceci en utilisant le paquet pivottabler relativement nouveau.
Divulgation: je suis l'auteur du package.
Pour plus d'informations, voir la page package sur CRAN et les diverses vignettes d'emballage disponibles sur cette page.
Données D'Échantillon (le même que ci-dessus)
set.seed(1)
school <- sample(c("BSA1", "BSA2", "HSA1"), 100, replace=T)
teacher <- sample(c("Tom", "Dick", "Harry"), 100, replace=T)
growth <- rnorm(100, 5, 3)
myDf <- data.frame(school, teacher, growth)
sortie de table à pivot rapide pour console en texte simple
library(pivottabler)
# arguments: qhpvt(dataFrame, rows, columns, calculations, ...)
qpvt(myDf, c("school", "teacher"), NULL,
c("Average Growth"="mean(growth)", "Std Dev"="sd(growth)",
"# of Scholars"="n()"),
formats=list("%.1f", "%.1f", "%.0f"))
Console Sortie:
Average Growth Std Dev # of Scholars
BSA1 Dick 4.7 3.7 14
Harry 4.3 1.4 9
Tom 5.5 4.0 4
Total 4.7 3.1 27
BSA2 Dick 6.1 2.3 15
Harry 5.0 2.9 9
Tom 4.3 2.8 14
Total 5.2 2.7 38
HSA1 Dick 4.5 2.9 11
Harry 4.9 3.0 13
Tom 4.7 3.2 11
Total 4.7 3.0 35
Total 4.9 2.9 100
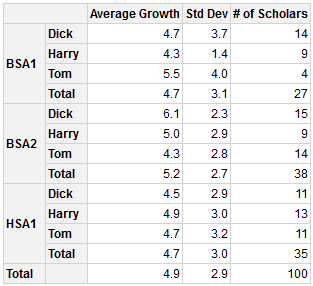
Rapide tableau croisé dynamique comme la sortie d'un widget html
library(pivottabler)
qhpvt(myDf, c("school", "teacher"), NULL,
c("Average Growth"="mean(growth)", "Std Dev"="sd(growth)",
"# of Scholars"="n()"),
formats=list("%.1f", "%.1f", "%.0f"))
HTML Widget Output:
Génération d'un tableau croisé dynamique à l'aide de plus de commentaires de syntaxe
il y a plus d'options, par exemple renommer les totaux.
library(pivottabler)
pt <- PivotTable$new()
pt$addData(myDf)
pt$addRowDataGroups("school", totalCaption="(all)")
pt$addRowDataGroups("teacher", totalCaption="(all)")
pt$defineCalculation(calculationName="c1", caption="Average Growth",
summariseExpression="mean(growth)", format="%.1f")
pt$defineCalculation(calculationName="c2", caption="Std Dev",
summariseExpression="sd(growth)", format="%.1f")
pt$defineCalculation(calculationName="c3", caption="# of Scholars",
summariseExpression="n()", format="%.0f")
pt # to output to console as plain text
pt$renderPivot() # to output as a html widget
HTML Widget Output:
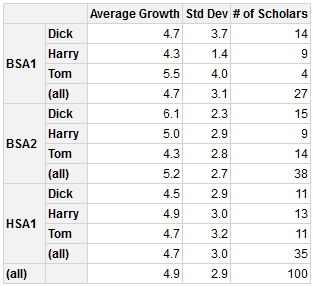
Désolé pour l'autopromotion, mais jetez un oeil à mon paquet expss.
Code pour générer la sortie ci-dessous:
set.seed(1)
school <- sample(c("BSA1", "BSA2", "HSA1"), 100, replace=T)
teacher <- sample(c("Tom", "Dick", "Harry"), 100, replace=T)
growth <- rnorm(100, 5, 3)
myDf <- data.frame(school, teacher, growth)
library(expss)
myDf %>%
# 'tab_cells' - variables on which statistics will be calculated
# "|" is needed to suppress 'growth' in row labels
tab_cells("|" = growth) %>%
# 'tab_cols' - variables for columns. Can be ommited
tab_cols(total(label = "")) %>%
# 'tab_rows' - variables for rows.
tab_rows(school %nest% list(teacher, "(All)"), "|" = "(All)") %>%
# 'method = list' is needed for statistics labels in column
tab_stat_fun("Average Growth" = mean,
"Std Dev" = sd,
"# of scholars" = length,
method = list) %>%
# finalize table
tab_pivot()
le Code ci-dessus donne l'objet hérité des données.cadre pouvant être utilisé avec les opérations standard R (sous-dimensionnement avec [ et etc.). Mais il y a un spécial!--3 -- > méthode pour cet objet. Sortie de la Console:
| | | Average Growth | Std Dev | # of scholars |
| ----- | ----- | -------------- | ------- | ------------- |
| BSA1 | Dick | 4.7 | 3.7 | 14 |
| | Harry | 4.3 | 1.4 | 9 |
| | Tom | 5.5 | 4.0 | 4 |
| | (All) | 4.7 | 3.1 | 27 |
| BSA2 | Dick | 6.1 | 2.3 | 15 |
| | Harry | 5.0 | 2.9 | 9 |
| | Tom | 4.3 | 2.8 | 14 |
| | (All) | 5.2 | 2.7 | 38 |
| HSA1 | Dick | 4.5 | 2.9 | 11 |
| | Harry | 4.9 | 3.0 | 13 |
| | Tom | 4.7 | 3.2 | 11 |
| | (All) | 4.7 | 3.0 | 35 |
| (All) | | 4.9 | 2.9 | 100 |
sortie via htmlTable dans knitr, RStudio de spectateur ou de Brillant: