Performance de Find () vs. FirstOrDefault () [dupliquer]
question similaire:
Find () vs. Where ().FirstOrDefault ()
a obtenu un résultat intéressant à la recherche de Diana dans une grande séquence d'un type de référence simple ayant une propriété de chaîne simple.
using System;
using System.Collections.Generic;
using System.Linq;
public class Customer{
public string Name {get;set;}
}
Stopwatch watch = new Stopwatch();
const string diana = "Diana";
while (Console.ReadKey().Key != ConsoleKey.Escape)
{
//Armour with 1000k++ customers. Wow, should be a product with a great success! :)
var customers = (from i in Enumerable.Range(0, 1000000)
select new Customer
{
Name = Guid.NewGuid().ToString()
}).ToList();
customers.Insert(999000, new Customer { Name = diana }); // Putting Diana at the end :)
//1. System.Linq.Enumerable.DefaultOrFirst()
watch.Restart();
customers.FirstOrDefault(c => c.Name == diana);
watch.Stop();
Console.WriteLine("Diana was found in {0} ms with System.Linq.Enumerable.FirstOrDefault().", watch.ElapsedMilliseconds);
//2. System.Collections.Generic.List<T>.Find()
watch.Restart();
customers.Find(c => c.Name == diana);
watch.Stop();
Console.WriteLine("Diana was found in {0} ms with System.Collections.Generic.List<T>.Find().", watch.ElapsedMilliseconds);
}
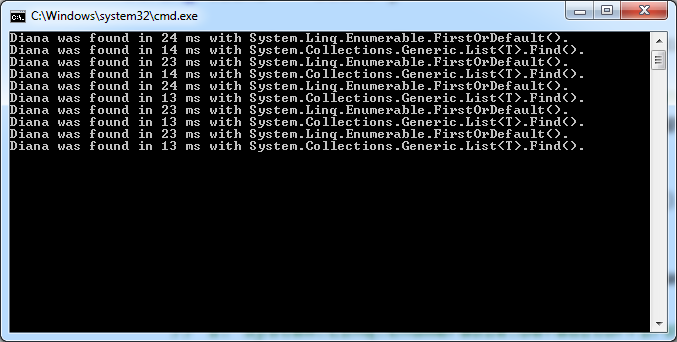
est ceci en raison de L'absence d'agent recenseur au-dessus de la liste.Trouver() ou ça et peut-être autre chose?
Find() court presque deux fois plus vite, en espérant que l'équipe .Net ne le marquera pas obsolète à l'avenir.
2 réponses
j'ai pu imiter vos résultats donc j'ai décomposé votre programme et il y a une différence entre Find et FirstOrDefault .
tout d'abord voici le programme décomposé. J'ai fait votre objet de données un élément de données anonmyous juste pour la compilation
List<\u003C\u003Ef__AnonymousType0<string>> source = Enumerable.ToList(Enumerable.Select(Enumerable.Range(0, 1000000), i =>
{
var local_0 = new
{
Name = Guid.NewGuid().ToString()
};
return local_0;
}));
source.Insert(999000, new
{
Name = diana
});
stopwatch.Restart();
Enumerable.FirstOrDefault(source, c => c.Name == diana);
stopwatch.Stop();
Console.WriteLine("Diana was found in {0} ms with System.Linq.Enumerable.FirstOrDefault().", (object) stopwatch.ElapsedMilliseconds);
stopwatch.Restart();
source.Find(c => c.Name == diana);
stopwatch.Stop();
Console.WriteLine("Diana was found in {0} ms with System.Collections.Generic.List<T>.Find().", (object) stopwatch.ElapsedMilliseconds);
la chose clé à noter ici est que FirstOrDefault est appelé sur Enumerable alors que Find est appelé comme une méthode sur la liste des sources.
Alors, qu'est-ce que trouver? C'est la méthode Find décomposée 1519130920"
private T[] _items;
[__DynamicallyInvokable]
public T Find(Predicate<T> match)
{
if (match == null)
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.match);
for (int index = 0; index < this._size; ++index)
{
if (match(this._items[index]))
return this._items[index];
}
return default (T);
}
donc il est itératif sur un tableau d'éléments qui a du sens, puisqu'une liste est un enveloppeur sur un tableau.
cependant, FirstOrDefault , sur la classe Enumerable , utilise foreach pour itérer les articles. Il utilise un itérateur à la liste et passer à côté. Je pense que ce que vous voyez est le overhead de l'iterator
[__DynamicallyInvokable]
public static TSource FirstOrDefault<TSource>(this IEnumerable<TSource> source, Func<TSource, bool> predicate)
{
if (source == null)
throw Error.ArgumentNull("source");
if (predicate == null)
throw Error.ArgumentNull("predicate");
foreach (TSource source1 in source)
{
if (predicate(source1))
return source1;
}
return default (TSource);
}
Foreach est juste sucre syntatique en utilisant le motif énumérable. Regardez cette image
 .
.
j'ai cliqué sur foreach pour voir ce qu'il fait et vous pouvez voir dotpeek veut m'emmener à l'énumérateur/en cours/prochaines implémentations qui a du sens.
à part le fait qu'ils sont essentiellement les mêmes (tester le prédicat réussi pour voir si un article est ce que vous voulez)
je parie que FirstOrDefault fonctionne via l'implémentation IEnumerable , c'est-à-dire qu'il utilisera une boucle foreach standard pour effectuer la vérification. List<T>.Find() ne fait pas partie de Linq ( http://msdn.microsoft.com/en-us/library/x0b5b5bc.aspx ), et utilise probablement une boucle standard for de 0 à Count (ou un autre mécanisme interne rapide fonctionnant probablement directement sur son réseau interne/enveloppé). En se débarrassant des frais généraux d'énumérer par (et faire les vérifications de version pour s'assurer que la liste n'a pas été modifiée) la méthode Find est plus rapide.
si vous ajoutez un troisième test:
//3. System.Collections.Generic.List<T> foreach
Func<Customer, bool> dianaCheck = c => c.Name == diana;
watch.Restart();
foreach(var c in customers)
{
if (dianaCheck(c))
break;
}
watch.Stop();
Console.WriteLine("Diana was found in {0} ms with System.Collections.Generic.List<T> foreach.", watch.ElapsedMilliseconds);
qui court à peu près à la même vitesse que le premier (25ms vs 27ms pour FirstOrDefault )
EDIT: si j'ajoute une boucle de tableau, il se rapproche assez près de la vitesse Find() , et étant donné @devshorts regarder le code source, je pense que c'est lui:
//4. System.Collections.Generic.List<T> for loop
var customersArray = customers.ToArray();
watch.Restart();
int customersCount = customersArray.Length;
for (int i = 0; i < customersCount; i++)
{
if (dianaCheck(customers[i]))
break;
}
watch.Stop();
Console.WriteLine("Diana was found in {0} ms with an array for loop.", watch.ElapsedMilliseconds);
cette méthode n'est que 5,5% plus lente que la méthode Find() .
donc la ligne de fond: boucle à travers les éléments du tableau est plus rapide que de traiter avec foreach itération au-dessus. (mais les deux ont leurs avantages/inconvénients, donc il suffit de choisir ce qui est logique pour votre code logiquement. De plus, ce n'est que rarement que la petite différence de vitesse ever posera un problème, alors il suffit d'utiliser ce qui a du sens pour maintenabilité / lisibilité)