Détection de crête du signal mesuré
nous utilisons une carte d'acquisition de données pour prendre des relevés d'un appareil qui augmente son signal jusqu'à un pic et retombe ensuite près de la valeur originale. Pour trouver la valeur de crête, nous cherchons actuellement dans le tableau la valeur la plus élevée et nous utilisons l'indice pour déterminer le moment où la valeur de crête est utilisée dans nos calculs.
cela fonctionne bien si la valeur la plus élevée est le pic que nous recherchons mais si l'appareil ne fonctionne pas correctement nous pouvons voir un deuxième pic qui peut être plus élevé que le pic initial. Nous prenons 10 lectures par seconde à partir de 16 appareils sur une période de 90 secondes.
mes pensées initiales sont de parcourir les lectures en vérifiant pour voir si les points précédents et suivants sont inférieurs au courant pour trouver un pic et construire un tableau de pics. Peut-être devrions-nous examiner une moyenne d'un certain nombre de points de part et d'autre de la position actuelle pour tenir compte du bruit dans le système. Est-ce la meilleure façon de procéder, ou de de meilleures techniques?
nous utilisons LabVIEW et j'ai vérifié les forums de lave et il y a un certain nombre d'exemples intéressants. Cela fait partie de notre logiciel de test et nous essayons d'éviter d'utiliser trop de bibliothèques VI non standard, donc j'espérais obtenir des commentaires sur le processus/les algorithmes impliqués plutôt que du code spécifique.
9 réponses
vous pouvez essayer la moyenne de signal, c.-à-d. pour chaque point, la moyenne de la valeur avec les 3 points environnants ou plus. Si le bruit soubresauts sont énormes, alors même cela peut ne pas aider.
je me rends compte que C'était agnostique au niveau du langage, mais en devinant que vous utilisez LabView, il y a beaucoup de VIs de traitement de signal pré-emballées qui viennent avec LabView que vous pouvez utiliser pour faire le lissage et la réduction du bruit. Les ni forums sont un excellent endroit pour obtenir plus l'aide spécialisée sur ce genre de chose.
il y a des tas et des tas de méthodes classiques de détection des pics, dont n'importe laquelle pourrait fonctionner. Vous devez voir ce qui, en particulier, limite la qualité de vos données. Voici les descriptions de base:
-
entre deux points de vos données,
(x(0), y(0))et(x(n), y(n)), additionnezy(i + 1) - y(i)pour0 <= i < net appelez celaT("voyage") et mettezR("ascension") ày(n) - y(0) + kpour un petitk.T/R > 1indique un pic. Cela fonctionne bien si un grand déplacement dû au bruit est peu probable ou si le bruit se répartit symétriquement autour d'une forme de courbe de base. Pour votre application, accepter le pic le plus tôt avec un score au-dessus d'un seuil donné, ou analyser la courbe des valeurs de voyage par hausse pour des propriétés plus intéressantes. -
utiliser des filtres appariés pour marquer la similitude avec une forme de pointe standard (essentiellement, utiliser un produit à points normalisés contre certains forme pour obtenir un cosinus-métrique de similarité)
-
Donne par rapport à un étalon forme de pic et vérifier pour des valeurs élevées (bien que je trouve souvent de 2 à être moins sensibles au bruit pour une simple instrumentation de sortie).
-
lisser les données et vérifier pour les triplets de points également espacés où, si
x0 < x1 < x2, y1 > 0.5 * (y0 + y2), ou vérifier les distances euclidiennes comme ceci:D((x0, y0), (x1, y1)) + D((x1, y1), (x2, y2)) > D((x0, y0),(x2, y2)), qui repose sur l'inégalité du triangle. L'utilisation de rapports simples vous fournira encore une fois un mécanisme de notation. -
ajustement d'un modèle de mélange 2-gaussien très simple à vos données (par exemple, recettes numériques a un bon morceau de code prêt à l'emploi). Prenez le précédent sommet. Cela permettra de traiter correctement les pics qui se chevauchent.
-
trouver la meilleure correspondance dans les données à une courbe gaussienne simple, Cauchy, Poisson, ou ce que-ONT-VOUS. Évaluer cette courbe sur une large plage et soustrayez - la d'une copie des données après avoir noté son emplacement de pointe. Répéter. Prenez le pic le plus précoce dont les paramètres du modèle (déviation standard probablement, mais certaines applications pourraient se soucier de kurtosis ou d'autres caractéristiques) répondent à un certain critère. Méfiez-vous des artefacts laissés derrière lorsque les pics sont soustraits des données. Le meilleur match peut être déterminé par le type de match marqué suggéré au numéro 2 ci-dessus.
j'ai fait ce que vous faites avant: trouver des pics dans les données de séquence D'ADN, trouver des pics dans les dérivés estimés à partir de courbes mesurées, et trouver des pics dans les histogrammes.
je vous encourage à vous occuper avec soin des baselinings appropriés. Le filtrage Wiener ou un autre filtrage ou l'analyse simple d'histogrammes est souvent un moyen facile de baseline en présence de bruit.
enfin, si vos données sont typiquement bruyantes et que vous obtenez des données sur la carte comme non référencées sortie simple (ou même référencée, tout simplement pas différentielle), et si vous faites la moyenne de beaucoup d'observations dans chaque point de données, essayez de trier ces observations et jeter le premier et le dernier quartile et la moyenne de ce qui reste. Il existe une foule de tactiques d'élimination qui peuvent être très utiles.
Ce problème a été étudié en détail.
il existe un ensemble d'implémentations très à jour dans les classes TSpectrum* de ROOT (un outil d'analyse de la physique nucléaire/des particules). Le code fonctionne en trois dimensions des données.
le code source racine est disponible, vous pouvez donc saisir cette implémentation si vous le souhaitez.
de la classe TSpectrum document:
Les algorithmes utilisés dans cette classe ont été publiés dans les références suivantes:
[1] M. Morhac et al.: Fond l'élimination méthodes pour coïncidence multidimensionnelle rayons gamma spectre. Les Instruments nucléaires et Méthodes de recherche en physique A 401 (1997) 113- 132.
[2] M. Morhac et al.: L'or à une et deux dimensions efficace deconvolution et son application à décomposition des spectres gamma. Instruments et méthodes nucléaires La Recherche En Physique 401 (1997) 385-408.
[3] M. Morhac et al.: Identification des pics de coïncidence multidimensionnelle rayons gamma spectre. Les Instruments nucléaires et Méthodes de recherche en physique 443 (2000), 108-125.
les journaux sont reliés à partir de la documentation de la classe pour ceux d'entre vous qui n'ont pas d'abonnement NIM en ligne.
la version courte de ce qui est fait est que l'histogramme aplati pour éliminer le bruit, puis les maxima locaux sont détectés par la force brute dans l'histogramme aplati.
je voudrais contribuer à ce fil un algorithme que j'ai développé moi-même :
il est basé sur le principe de dispersion : si un nouveau point de données est un nombre x donné d'écarts-types loin d'une moyenne mobile, les signaux de l'algorithme (également appelé Z-score ). L'algorithme est très robuste parce qu'il construit une séparée moyenne mobile et déviation, de sorte que les signaux ne corrompent pas le seuil. Les signaux futurs sont donc identifiés avec à peu près la même précision, quelle que soit la quantité de signaux antérieurs. L'algorithme prend 3 entrées: lag = the lag of the moving window , threshold = the z-score at which the algorithm signals et influence = the influence (between 0 and 1) of new signals on the mean and standard deviation . Par exemple, un lag de 5 les 5 dernières observations pour lisser les données. Un threshold de 3.5 signalera si un point de données est à 3.5 écarts-types de la moyenne mobile. Et un influence de 0,5 donne des signaux la moitié de l'influence des points de données normaux. De même, un influence de 0 ignore complètement les signaux pour recalculer le nouveau seuil: une influence de 0 est donc l'option la plus robuste.
il fonctionne comme suit:
Pseudo-code
# Let y be a vector of timeseries data of at least length lag+2
# Let mean() be a function that calculates the mean
# Let std() be a function that calculates the standard deviaton
# Let absolute() be the absolute value function
# Settings (the ones below are examples: choose what is best for your data)
set lag to 5; # lag 5 for the smoothing functions
set threshold to 3.5; # 3.5 standard deviations for signal
set influence to 0.5; # between 0 and 1, where 1 is normal influence, 0.5 is half
# Initialise variables
set signals to vector 0,...,0 of length of y; # Initialise signal results
set filteredY to y(1,...,lag) # Initialise filtered series
set avgFilter to null; # Initialise average filter
set stdFilter to null; # Initialise std. filter
set avgFilter(lag) to mean(y(1,...,lag)); # Initialise first value
set stdFilter(lag) to std(y(1,...,lag)); # Initialise first value
for i=lag+1,...,t do
if absolute(y(i) - avgFilter(i-1)) > threshold*stdFilter(i-1) then
if y(i) > avgFilter(i-1)
set signals(i) to +1; # Positive signal
else
set signals(i) to -1; # Negative signal
end
# Adjust the filters
set filteredY(i) to influence*y(i) + (1-influence)*filteredY(i-1);
set avgFilter(i) to mean(filteredY(i-lag,i),lag);
set stdFilter(i) to std(filteredY(i-lag,i),lag);
else
set signals(i) to 0; # No signal
# Adjust the filters
set filteredY(i) to y(i);
set avgFilter(i) to mean(filteredY(i-lag,i),lag);
set stdFilter(i) to std(filteredY(i-lag,i),lag);
end
end
Démo
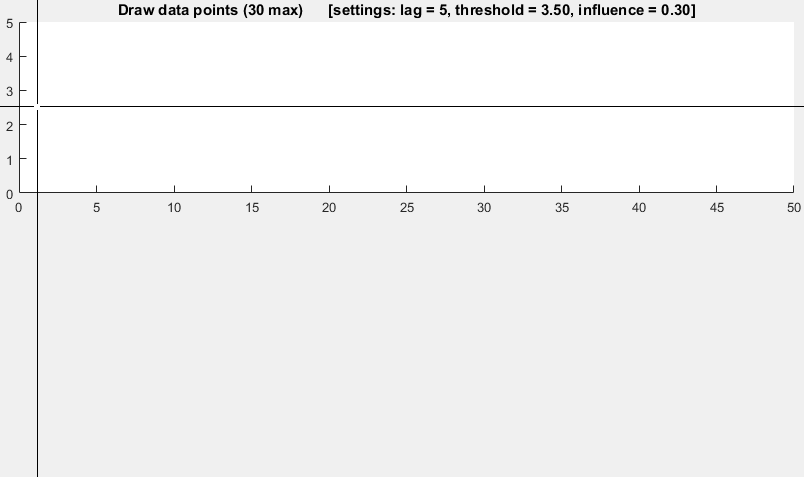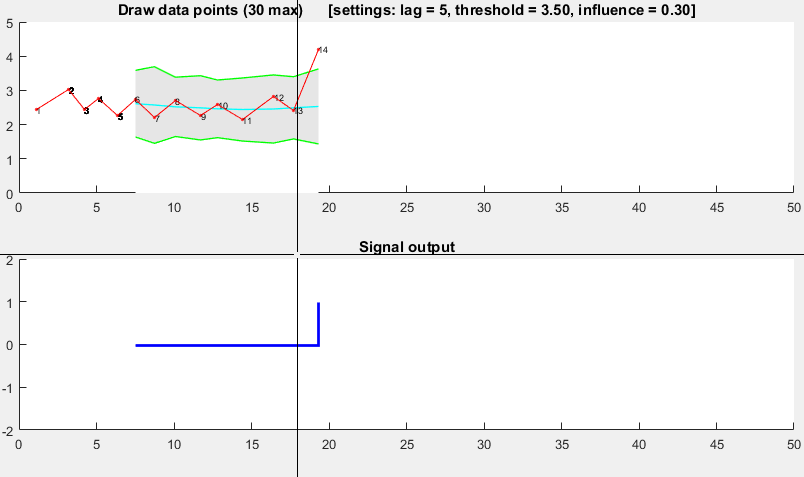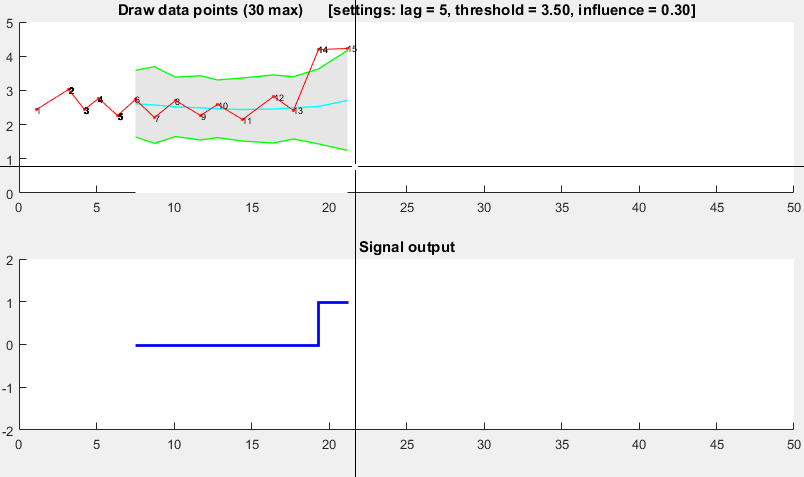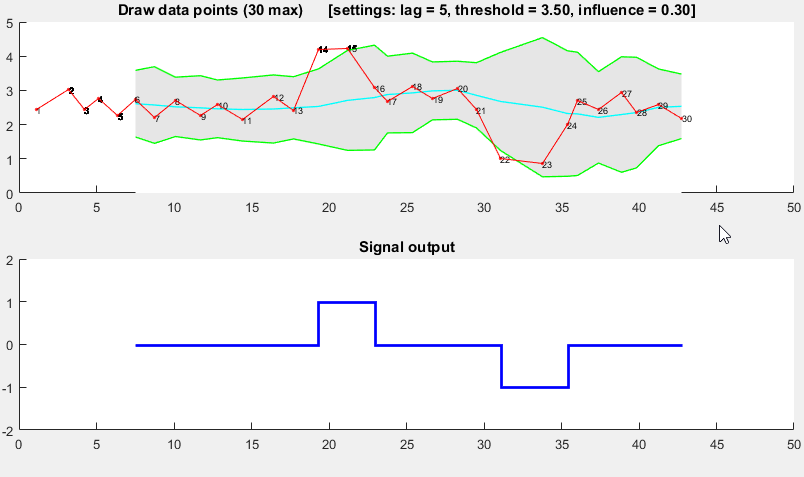
> réponse originale
Cette méthode est essentiellement à partir de David Marr du livre "Vision"
Gaussian brouiller votre signal avec la largeur prévue de vos pics. cela élimine les pointes de bruit et vos données de phase sont intactes.
Puis bord de détecter (JOURNAL)
alors vos bords étaient les bords des traits (comme les pics). regardez entre les bords pour les pics, trier les pics par taille, et vous avez fini.
j'ai utilisé des variantes sur ce et ils fonctionnent très bien.
je pense que vous voulez cross-corrélation votre signal avec un, exemplaire du signal. Mais ça fait si longtemps que je n'ai pas étudié le traitement du signal et je n'y ai même pas prêté attention.
vous pourriez appliquer quelques Standard Devision à votre logique et prendre note des pics de plus de x%.
Je ne sais pas grand chose sur l'instrumentation, donc cela pourrait être totalement impraticable, mais là encore, il pourrait être une direction utile différente. Si vous savez comment les lectures peuvent échouer, et qu'il y a un certain intervalle entre les pics compte tenu de ces échecs, pourquoi ne pas effectuer une descente en pente à chaque intervalle. Si la descente vous ramène à une zone que vous avez déjà cherchée, vous pouvez l'abandonner. Selon la forme de la surface échantillonnée, cela peut aussi vous aider à trouver des pics plus rapidement que rechercher.
y a-t-il une différence qualitative entre le pic désiré et le second pic non désiré? Si les deux pics sont "pointus" - c.-à-d. de courte durée-en regardant le signal dans le domaine de fréquence (en faisant FFT) vous obtiendrez de l'énergie à la plupart des bandes. Mais si le "bon" pic a de l'énergie présente de façon fiable à des fréquences qui n'existent pas dans le "mauvais" pic, ou vice versa, vous pouvez être en mesure de les différencier automatiquement de cette façon.