Analyse du fichier CSV avec des champs multilignes et des doubles guillemets échappés
Quelle est la meilleure façon d'analyser un fichier CSV avec les champs et les guillemets échappés ?
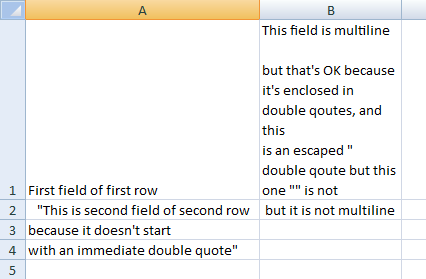
par exemple, ce CSV
First field of first row,"This field is multiline
but that's OK because it's enclosed in double qoutes, and this
is an escaped "" double qoute" but this one "" is not
"This is second field of second row, but it is not multiline
because it doesn't start
with an immediate double quote"
ressemble dans Excel comme ceci:
est-ce que je préserve l'état d'une façon ou d'une autre, avoir un drapeau disant si le champ que je lis maintenant a commencé avec un qoute, etc.? En outre, qu'arrive-t-il aux cas où il y a double les citations mais pas au début du champ, c.-à-d. , "ABC" , ou ,"item "" item" "" sont-elles considérées invalides? En outre, "" citations échappées si pas à l'intérieur d'un champ Cité? Excel ne semble pas.
y a-t-il d'autres corner cases que j'aurais pu manquer?
2 réponses
vos données d'échantillon ont un double devis simple juste après 'double qoute' (sic) qui met fin au double début de zone, mais vous devez continuer à lire jusqu'à la virgule suivante ou la fin de ligne. C'est un champ multi-lignes mal formé, mais vous voyez ce que Excel en fait. Vous pouvez trouver une description de ce dans le (excellent) livre la pratique de la programmation ( lien mort - Copie D'Archive Internet ; live link at Princeton University ) qui comprend une bibliothèque d'analyse CSV en C et une réimplementation en C++, et qui traite de ce niveau de détail. Il y a aussi une norme pour CSV dans RFC 4180 "Format commun et Type MIME pour les valeurs séparées par des virgules" et vous pouvez également étudier Wikipedia sur le sujet.
dans l'autre réponse, il y a un code d'échantillon, encore en cours de test. Il est assez résistant dans ses limites. Ici, il est modifié dans un SSCCE ( Bref, Autonome, Exemple Correcte ).
#include <stdbool.h>
#include <wchar.h>
#include <wctype.h>
extern const wchar_t *nextCsvField(const wchar_t *p, wchar_t sep, bool *newline);
// Returns a pointer to the start of the next field,
// or zero if this is the last field in the CSV
// p is the start position of the field
// sep is the separator used, i.e. comma or semicolon
// newline says whether the field ends with a newline or with a comma
const wchar_t *nextCsvField(const wchar_t *p, wchar_t sep, bool *newline)
{
// Parse quoted sequences
if ('"' == p[0]) {
p++;
while (1) {
// Find next double-quote
p = wcschr(p, L'"');
// If we don't find it or it's the last symbol
// then this is the last field
if (!p || !p[1])
return 0;
// Check for "", it is an escaped double-quote
if (p[1] != '"')
break;
// Skip the escaped double-quote
p += 2;
}
}
// Find next newline or comma.
wchar_t newline_or_sep[4] = L"\n\r ";
newline_or_sep[2] = sep;
p = wcspbrk(p, newline_or_sep);
// If no newline or separator, this is the last field.
if (!p)
return 0;
// Check if we had newline.
*newline = (p[0] == '\r' || p[0] == '\n');
// Handle "\r\n", otherwise just increment
if (p[0] == '\r' && p[1] == '\n')
p += 2;
else
p++;
return p;
}
static void dissect(const wchar_t *line)
{
const wchar_t *start = line;
const wchar_t *next;
bool eol;
wprintf(L"Input: %d [%.*ls]\n", wcslen(line), wcslen(line)-1, line);
while ((next = nextCsvField(start, L',', &eol)) != 0)
{
wprintf(L"Field: [%.*ls] (eol = %d)\n", (next - start - eol), start, eol);
start = next;
}
}
static const wchar_t multiline[] =
L"First field of first row,\"This field is multiline\n"
"\n"
"but that's OK because it's enclosed in double quotes, and this\n"
"is an escaped \"\" double quote\" but this one \"\" is not\n"
" \"This is second field of second row, but it is not multiline\n"
" because it doesn't start \n"
" with an immediate double quote\"\n"
;
int main(void)
{
wchar_t line[1024];
while (fgetws(line, sizeof(line)/sizeof(line[0]), stdin))
dissect(line);
dissect(multiline);
return 0;
}
exemple de sortie
$ cat csv.data
a,bb, c ,d""e,f
1,"2","",,"""",4
$ ./wcsv < csv.data
Input: 16 [a,bb, c ,d""e,f]
Field: [a,] (eol = 0)
Field: [bb,] (eol = 0)
Field: [ c ,] (eol = 0)
Field: [d""e,] (eol = 0)
Field: [f] (eol = 1)
Input: 17 [1,"2","",,"""",4]
Field: [1,] (eol = 0)
Field: ["2",] (eol = 0)
Field: ["",] (eol = 0)
Field: [,] (eol = 0)
Field: ["""",] (eol = 0)
Field: [4] (eol = 1)
Input: 296 [First field of first row,"This field is multiline
but that's OK because it's enclosed in double quotes, and this
is an escaped "" double quote" but this one "" is not
"This is second field of second row, but it is not multiline
because it doesn't start
with an immediate double quote"]
Field: [First field of first row,] (eol = 0)
Field: ["This field is multiline
but that's OK because it's enclosed in double quotes, and this
is an escaped "" double quote" but this one "" is not] (eol = 1)
Field: [ "This is second field of second row,] (eol = 0)
Field: [ but it is not multiline] (eol = 1)
Field: [ because it doesn't start ] (eol = 1)
Field: [ with an immediate double quote"] (eol = 1)
$
j'ai dit "dans ses limites"; quelles sont ses limites?
principalement, il isole le champ brut, plutôt que le champ converti. Ainsi, le champ il isole doit être modifié pour produire la valeur "réelle", avec les guillemets doubles entourés, et les guillemets doubles internes remplacés par des guillemets simples. Convertir un champ brut en valeur réelle imite beaucoup le code de la fonction nextCsvField() . Les entrées sont le début du champ et à la fin du champ (le caractère de séparation). Voici un second SSCCE avec une fonction supplémentaire csvFieldData() , et la fonction dissect() ci-dessus révisée pour l'appeler. Le format de la sortie disséquée est légèrement
#include <stdbool.h>
#include <wchar.h>
#include <wctype.h>
extern const wchar_t *nextCsvField(const wchar_t *p, wchar_t sep, bool *newline);
// Returns a pointer to the start of the next field,
// or zero if this is the last field in the CSV
// p is the start position of the field
// sep is the separator used, i.e. comma or semicolon
// newline says whether the field ends with a newline or with a comma
const wchar_t *nextCsvField(const wchar_t *p, wchar_t sep, bool *newline)
{
// Parse quoted sequences
if ('"' == p[0]) {
p++;
while (1) {
// Find next double-quote
p = wcschr(p, L'"');
// If we don't find it or it's the last symbol
// then this is the last field
if (!p || !p[1])
return 0;
// Check for "", it is an escaped double-quote
if (p[1] != '"')
break;
// Skip the escaped double-quote
p += 2;
}
}
// Find next newline or comma.
wchar_t newline_or_sep[4] = L"\n\r ";
newline_or_sep[2] = sep;
p = wcspbrk(p, newline_or_sep);
// If no newline or separator, this is the last field.
if (!p)
return 0;
// Check if we had newline.
*newline = (p[0] == '\r' || p[0] == '\n');
// Handle "\r\n", otherwise just increment
if (p[0] == '\r' && p[1] == '\n')
p += 2;
else
p++;
return p;
}
static wchar_t *csvFieldData(const wchar_t *fld_s, const wchar_t *fld_e, wchar_t *buffer, size_t buflen)
{
wchar_t *dst = buffer;
wchar_t *end = buffer + buflen - 1;
const wchar_t *src = fld_s;
if (*src == L'"')
{
const wchar_t *p = src + 1;
while (p < fld_e && dst < end)
{
if (p[0] == L'"' && p+1 < fld_s && p[1] == L'"')
{
*dst++ = p[0];
p += 2;
}
else if (p[0] == L'"')
{
p++;
break;
}
else
*dst++ = *p++;
}
src = p;
}
while (src < fld_e && dst < end)
*dst++ = *src++;
if (dst >= end)
return 0;
*dst = L'"151920920"';
return(buffer);
}
static void dissect(const wchar_t *line)
{
const wchar_t *start = line;
const wchar_t *next;
bool eol;
wprintf(L"Input %3zd: [%.*ls]\n", wcslen(line), wcslen(line)-1, line);
while ((next = nextCsvField(start, L',', &eol)) != 0)
{
wchar_t buffer[1024];
wprintf(L"Raw Field: [%.*ls] (eol = %d)\n", (next - start - eol), start, eol);
if (csvFieldData(start, next-1, buffer, sizeof(buffer)/sizeof(buffer[0])) != 0)
wprintf(L"Field %3zd: [%ls]\n", wcslen(buffer), buffer);
start = next;
}
}
static const wchar_t multiline[] =
L"First field of first row,\"This field is multiline\n"
"\n"
"but that's OK because it's enclosed in double quotes, and this\n"
"is an escaped \"\" double quote\" but this one \"\" is not\n"
" \"This is second field of second row, but it is not multiline\n"
" because it doesn't start \n"
" with an immediate double quote\"\n"
;
int main(void)
{
wchar_t line[1024];
while (fgetws(line, sizeof(line)/sizeof(line[0]), stdin))
dissect(line);
dissect(multiline);
return 0;
}
exemple de sortie
$ ./wcsv < csv.data
Input 16: [a,bb, c ,d""e,f]
Raw Field: [a,] (eol = 0)
Field 1: [a]
Raw Field: [bb,] (eol = 0)
Field 2: [bb]
Raw Field: [ c ,] (eol = 0)
Field 3: [ c ]
Raw Field: [d""e,] (eol = 0)
Field 4: [d""e]
Raw Field: [f] (eol = 1)
Field 1: [f]
Input 17: [1,"2","",,"""",4]
Raw Field: [1,] (eol = 0)
Field 1: [1]
Raw Field: ["2",] (eol = 0)
Field 1: [2]
Raw Field: ["",] (eol = 0)
Field 0: []
Raw Field: [,] (eol = 0)
Field 0: []
Raw Field: ["""",] (eol = 0)
Field 2: [""]
Raw Field: [4] (eol = 1)
Field 1: [4]
Input 296: [First field of first row,"This field is multiline
but that's OK because it's enclosed in double quotes, and this
is an escaped "" double quote" but this one "" is not
"This is second field of second row, but it is not multiline
because it doesn't start
with an immediate double quote"]
Raw Field: [First field of first row,] (eol = 0)
Field 24: [First field of first row]
Raw Field: ["This field is multiline
but that's OK because it's enclosed in double quotes, and this
is an escaped "" double quote" but this one "" is not] (eol = 1)
Field 140: [This field is multiline
but that's OK because it's enclosed in double quotes, and this
is an escaped " double quote" but this one "" is not]
Raw Field: [ "This is second field of second row,] (eol = 0)
Field 38: [ "This is second field of second row]
Raw Field: [ but it is not multiline] (eol = 1)
Field 24: [ but it is not multiline]
Raw Field: [ because it doesn't start ] (eol = 1)
Field 28: [ because it doesn't start ]
Raw Field: [ with an immediate double quote"] (eol = 1)
Field 34: [ with an immediate double quote"]
$
Je n'ai pas testé la fin de ligne \r\n (ou \r ).
j'ai écrit une fonction (que je teste toujours) qui essaie de l'analyser aussi bien que possible.
// Returns a pointer to the start of the next field, or zero if this is the
// last field in the CSV p is the start position of the field sep is the
// separator used, i.e. comma or semicolon newline says whether the field ends
// with a newline or with a comma
static const wchar_t* nextCsvField(const wchar_t *p, wchar_t sep, bool *newline, const wchar_t **escapedEnd)
{
*escapedEnd = 0;
*newline = false;
// Parse quoted sequences
if ('"' == p[0]) {
p++;
while (1) {
// Find next double-quote.
p = wcschr(p, L'"');
// If we didn't find it then this is the last field.
if (!p)
return 0;
// Check for "", it is an escaped double-quote.
if (p[1] != '"') {
*escapedEnd = p;
break;
}
// If it's the last symbol then this is the last field
if (!p[1])
return 0;
// Skip the escaped double-quote
p += 2;
}
}
// Find next newline or comma.
wchar_t newline_or_sep[4] = L"\n\r ";
newline_or_sep[2] = sep;
p = wcspbrk(p, newline_or_sep);
// If no newline or separator, this is the last field.
if (!p)
return 0;
// Check if we had newline.
*newline = (p[0] == '\r' || p[0] == '\n');
// Handle "\r\n", otherwise just increment
if (p[0] == '\r' && p[1] == '\n')
p += 2;
else
p++;
return p;
}