Analyser XLSX avec Node et créer json
Ok donc j'ai trouvé cela très bien documenté node_module js-xlsx
Question: Comment puis-je!--8-->analyser un xlsx à la sortie json?
voici à quoi ressemble la feuille excel:
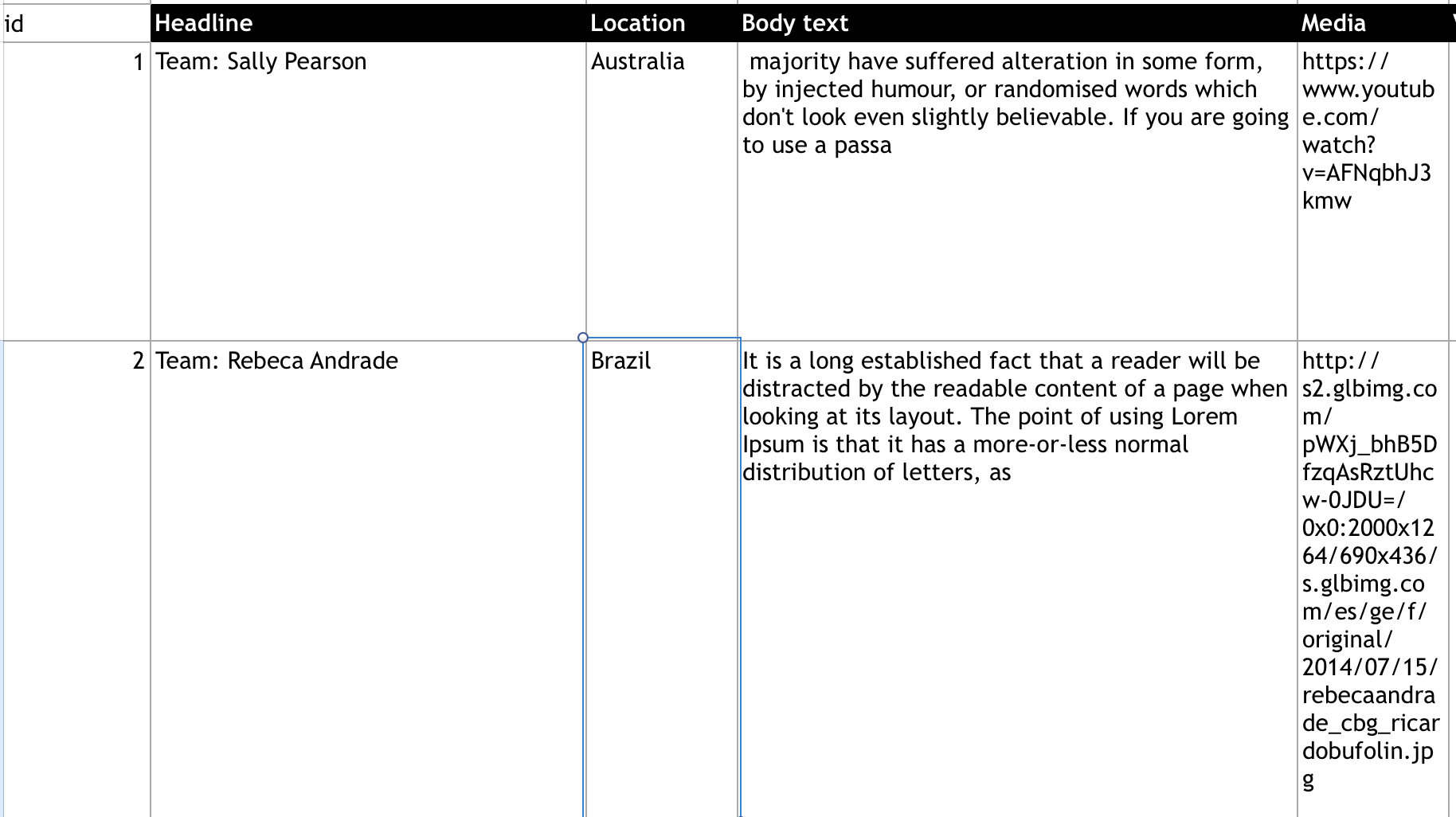
À la fin du json devrait ressembler à ceci:
[
{
"id": 1,
"Headline": "Team: Sally Pearson",
"Location": "Austrailia",
"BodyText": "...",
"Media: "..."
},
{
"id": 2,
"Headline": "Team: Rebeca Andrade",
"Location": "Brazil",
"BodyText": "...",
"Media: "..."
}
]
index.js:
if(typeof require !== 'undefined') {
console.log('hey');
XLSX = require('xlsx');
}
var workbook = XLSX.readFile('./assets/visa.xlsx');
var sheet_name_list = workbook.SheetNames;
sheet_name_list.forEach(function(y) { /* iterate through sheets */
var worksheet = workbook.Sheets[y];
for (z in worksheet) {
/* all keys that do not begin with "!" correspond to cell addresses */
if(z[0] === '!') continue;
// console.log(y + "!" + z + "=" + JSON.stringify(worksheet[z].v));
}
});
XLSX.writeFile(workbook, 'out.xlsx');
27
demandé sur
Donvino
2015-06-16 09:05:06
4 réponses
version améliorée de la réponse" Josh Marinacci", elle se lira au-delà de la colonne Z (i.e. AA1).
var XLSX = require('xlsx');
var workbook = XLSX.readFile('test.xlsx');
var sheet_name_list = workbook.SheetNames;
sheet_name_list.forEach(function(y) {
var worksheet = workbook.Sheets[y];
var headers = {};
var data = [];
for(z in worksheet) {
if(z[0] === '!') continue;
//parse out the column, row, and value
var tt = 0;
for (var i = 0; i < z.length; i++) {
if (!isNaN(z[i])) {
tt = i;
break;
}
};
var col = z.substring(0,tt);
var row = parseInt(z.substring(tt));
var value = worksheet[z].v;
//store header names
if(row == 1 && value) {
headers[col] = value;
continue;
}
if(!data[row]) data[row]={};
data[row][headers[col]] = value;
}
//drop those first two rows which are empty
data.shift();
data.shift();
console.log(data);
});
28
répondu
Parijat
2016-07-01 16:54:57
Vous pouvez aussi utiliser
var XLSX = require('xlsx');
var workbook = XLSX.readFile('Master.xlsx');
var sheet_name_list = workbook.SheetNames;
console.log(XLSX.utils.sheet_to_json(workbook.Sheets[sheet_name_list[0]]))
42
répondu
user3812377
2016-10-27 18:45:52
je pense que ce code fera ce que vous voulez. Il stocke la première ligne comme un ensemble d'en-têtes, puis stocke le reste dans un objet de données que vous pouvez écrire sur le disque comme JSON.
var XLSX = require('xlsx');
var workbook = XLSX.readFile('test.xlsx');
var sheet_name_list = workbook.SheetNames;
sheet_name_list.forEach(function(y) {
var worksheet = workbook.Sheets[y];
var headers = {};
var data = [];
for(z in worksheet) {
if(z[0] === '!') continue;
//parse out the column, row, and value
var col = z.substring(0,1);
var row = parseInt(z.substring(1));
var value = worksheet[z].v;
//store header names
if(row == 1) {
headers[col] = value;
continue;
}
if(!data[row]) data[row]={};
data[row][headers[col]] = value;
}
//drop those first two rows which are empty
data.shift();
data.shift();
console.log(data);
});
affiche
[ { id: 1,
headline: 'team: sally pearson',
location: 'Australia',
'body text': 'majority have…',
media: 'http://www.youtube.com/foo' },
{ id: 2,
headline: 'Team: rebecca',
location: 'Brazil',
'body text': 'it is a long established…',
media: 'http://s2.image.foo/' } ]
23
répondu
Josh Marinacci
2015-06-26 23:02:53
voici la version 5 méthode angulaire de ceci avec une syntaxe non diminuée pour ceux qui luttent avec cela y,z, tt réponse acceptée. d'utilisation: parseXlsx().subscribe((data)=> {...})
parseXlsx() {
let self = this;
return Observable.create(observer => {
this.http.get('./assets/input.xlsx', { responseType: 'arraybuffer' }).subscribe((data: ArrayBuffer) => {
const XLSX = require('xlsx');
let file = new Uint8Array(data);
let workbook = XLSX.read(file, { type: 'array' });
let sheetNamesList = workbook.SheetNames;
let allLists = {};
sheetNamesList.forEach(function (sheetName) {
let worksheet = workbook.Sheets[sheetName];
let currentWorksheetHeaders: object = {};
let data: Array<any> = [];
for (let cellName in worksheet) {//cellNames example: !ref,!margins,A1,B1,C1
//skipping serviceCells !margins,!ref
if (cellName[0] === '!') {
continue
};
//parse colName, rowNumber, and getting cellValue
let numberPosition = self.getCellNumberPosition(cellName);
let colName = cellName.substring(0, numberPosition);
let rowNumber = parseInt(cellName.substring(numberPosition));
let cellValue = worksheet[cellName].w;// .w is XLSX property of parsed worksheet
//treating '-' cells as empty on Spot Indices worksheet
if (cellValue.trim() == "-") {
continue;
}
//storing header column names
if (rowNumber == 1 && cellValue) {
currentWorksheetHeaders[colName] = typeof (cellValue) == "string" ? cellValue.toCamelCase() : cellValue;
continue;
}
//creating empty object placeholder to store current row
if (!data[rowNumber]) {
data[rowNumber] = {}
};
//if header is date - for spot indices headers are dates
data[rowNumber][currentWorksheetHeaders[colName]] = cellValue;
}
//dropping first two empty rows
data.shift();
data.shift();
allLists[sheetName.toCamelCase()] = data;
});
this.parsed = allLists;
observer.next(allLists);
observer.complete();
})
});
}
0
répondu
godblessstrawberry
2018-09-27 07:19:30