Pandas: différence entre la table à pivot et la table à pivot. Pourquoi la table à pivot fonctionne-t-elle?
j'ai le texte suivant dataframe.
df.head(30)
struct_id resNum score_type_name score_value
0 4294967297 1 omega 0.064840
1 4294967297 1 fa_dun 2.185618
2 4294967297 1 fa_dun_dev 0.000027
3 4294967297 1 fa_dun_semi 2.185591
4 4294967297 1 ref -1.191180
5 4294967297 2 rama -0.795161
6 4294967297 2 omega 0.222345
7 4294967297 2 fa_dun 1.378923
8 4294967297 2 fa_dun_dev 0.028560
9 4294967297 2 fa_dun_rot 1.350362
10 4294967297 2 p_aa_pp -0.442467
11 4294967297 2 ref 0.249477
12 4294967297 3 rama 0.267443
13 4294967297 3 omega 0.005106
14 4294967297 3 fa_dun 0.020352
15 4294967297 3 fa_dun_dev 0.025507
16 4294967297 3 fa_dun_rot -0.005156
17 4294967297 3 p_aa_pp -0.096847
18 4294967297 3 ref 0.979644
19 4294967297 4 rama -1.403292
20 4294967297 4 omega 0.212160
21 4294967297 4 fa_dun 4.218029
22 4294967297 4 fa_dun_dev 0.003712
23 4294967297 4 fa_dun_semi 4.214317
24 4294967297 4 p_aa_pp -0.462765
25 4294967297 4 ref -1.960940
26 4294967297 5 rama -0.600053
27 4294967297 5 omega 0.061867
28 4294967297 5 fa_dun 3.663050
29 4294967297 5 fa_dun_dev 0.004953
selon la documentation de pivot, je devrais être en mesure de remodeler cela sur le score_type_name en utilisant la fonction de pivot.
df.pivot(columns='score_type_name',values='score_value',index=['struct_id','resNum'])
mais j'obtiens ce qui suit.
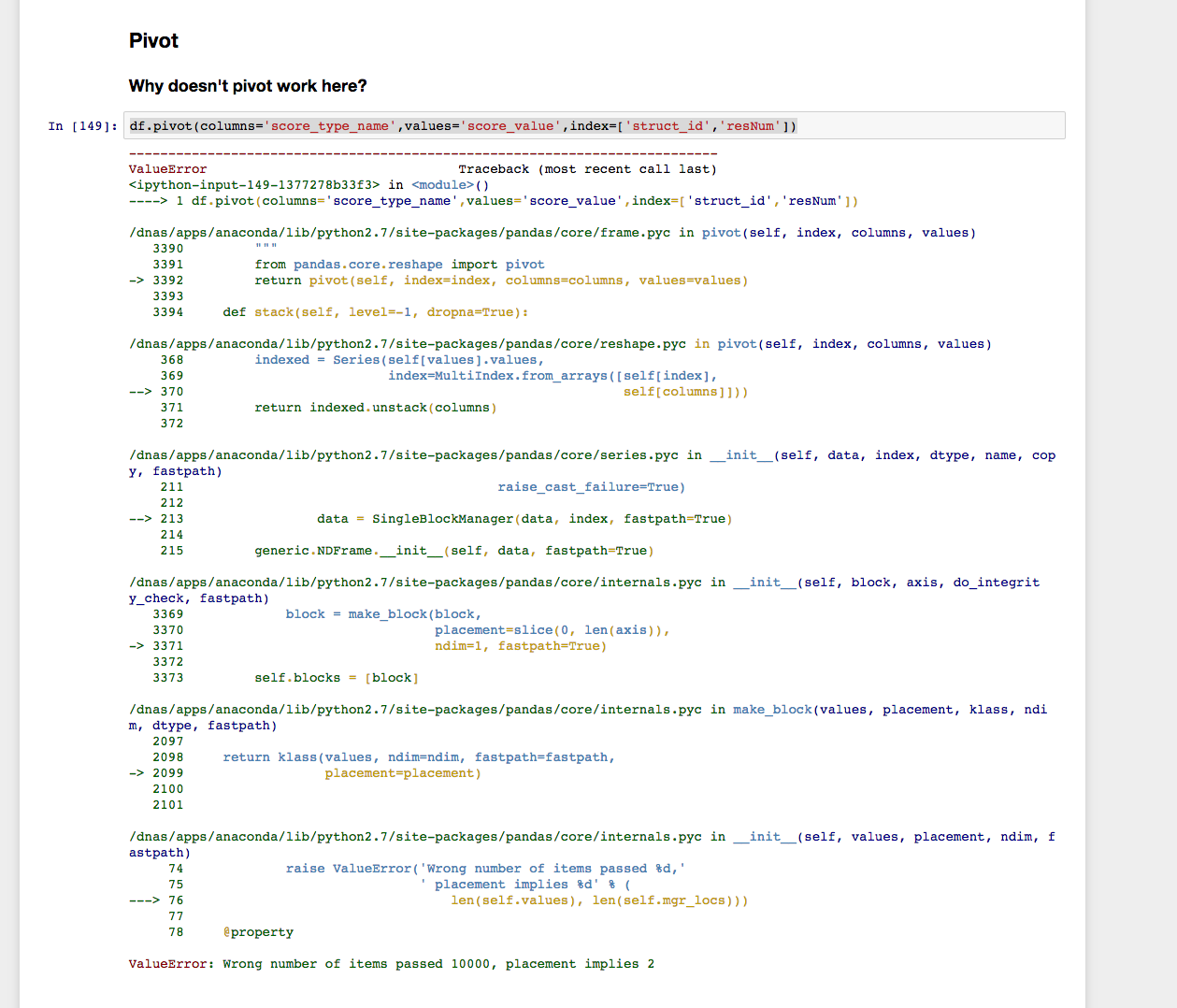
cependant, la fonction pivot_table semble fonctionner:
pivoted = df.pivot_table(columns='score_type_name',
values='score_value',
index=['struct_id','resNum'])
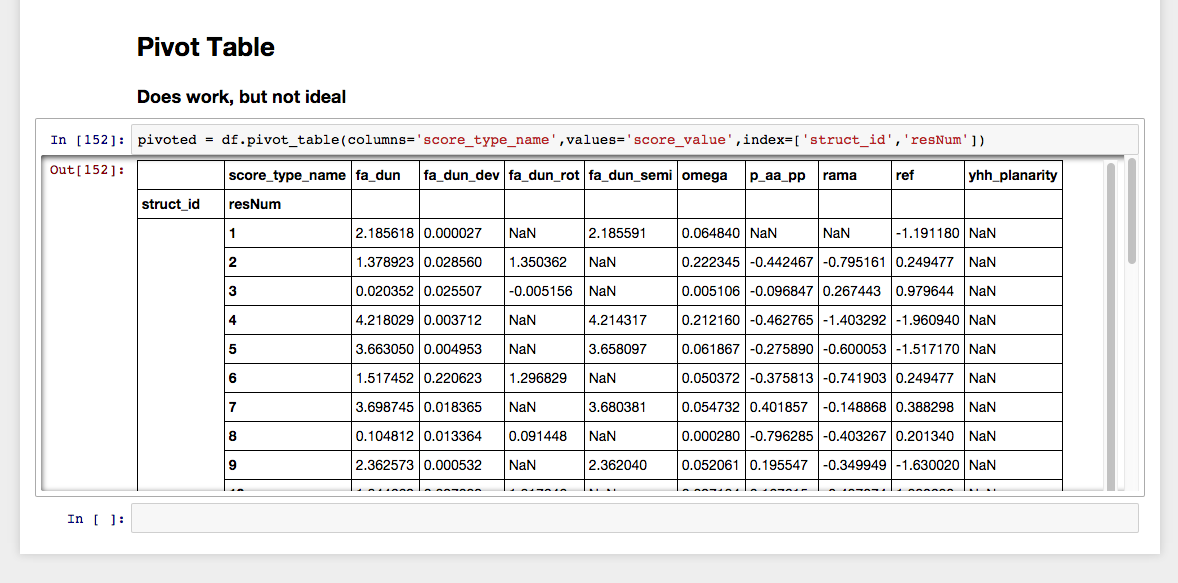
alors est-ce que quelqu'un peut me dire comment je peux obtenir une bonne base de données comme je le veux en utilisant pivot? En outre, de la documentation, Je ne peux pas dire pourquoi pivot_table fonctionne et pivot ne fonctionne pas. Si je regarde le premier exemple de pivot, il ressemble exactement à ce que je besoin.
P. J'ai posté une question en référence à ce problème, mais j'ai fait un si mauvais travail de démontrer la sortie, je l'ai supprimé et ai essayé à nouveau en utilisant le carnet ipython. Je m'excuse d'avance si vous voyez ça deux fois.
voici le carnet pour votre référence complète
EDIT-mes résultats souhaités ressembleraient à ceci (made in excel):
StructId resNum pdb_residue_number chain_id name3 fa_dun fa_dun_dev fa_dun_rot fa_dun_semi omega p_aa_pp rama ref
4294967297 1 99 A ASN 2.1856 0.0000 2.1856 0.0648 -1.1912
4294967297 2 100 A MET 1.3789 0.0286 1.3504 0.2223 -0.4425 -0.7952 0.2495
4294967297 3 101 A VAL 0.0204 0.0255 -0.0052 0.0051 -0.0968 0.2674 0.9796
4294967297 4 102 A GLU 4.2180 0.0037 4.2143 0.2122 -0.4628 -1.4033 -1.9609
4294967297 5 103 A GLN 3.6630 0.0050 3.6581 0.0619 -0.2759 -0.6001 -1.5172
4294967297 6 104 A MET 1.5175 0.2206 1.2968 0.0504 -0.3758 -0.7419 0.2495
4294967297 7 105 A HIS 3.6987 0.0184 3.6804 0.0547 0.4019 -0.1489 0.3883
4294967297 8 106 A THR 0.1048 0.0134 0.0914 0.0003 -0.7963 -0.4033 0.2013
4294967297 9 107 A ASP 2.3626 0.0005 2.3620 0.0521 0.1955 -0.3499 -1.6300
4294967297 10 108 A ILE 1.8447 0.0270 1.8176 0.0971 0.1676 -0.4071 1.0806
4294967297 11 109 A ILE 0.1276 0.0092 0.1183 0.0208 -0.4026 -0.0075 1.0806
4294967297 12 110 A SER 0.2921 0.0342 0.2578 0.0342 -0.2426 -1.3930 0.1654
4294967297 13 111 A LEU 0.6483 0.0019 0.6464 0.0845 -0.3565 -0.2356 0.7611
4294967297 14 112 A TRP 2.5965 0.1507 2.4457 0.5143 -0.1370 -0.5373 1.2341
4294967297 15 113 A ASP 2.6448 0.1593 0.0510 -0.5011
6 réponses
je ne suis pas sûr de comprendre, mais je vais essayer. J'utilise habituellement stack / untack au lieu de pivotement, est-ce plus près de ce que vous voulez?
df.set_index(['struct_id','resNum','score_type_name']).unstack()
score_value
score_type_name fa_dun fa_dun_dev fa_dun_rot fa_dun_semi omega
struct_id resNum
4294967297 1 2.185618 0.000027 NaN 2.185591 0.064840
2 1.378923 0.028560 1.350362 NaN 0.222345
3 0.020352 0.025507 -0.005156 NaN 0.005106
4 4.218029 0.003712 NaN 4.214317 0.212160
5 3.663050 0.004953 NaN NaN 0.061867
score_type_name p_aa_pp rama ref
struct_id resNum
4294967297 1 NaN NaN -1.191180
2 -0.442467 -0.795161 0.249477
3 -0.096847 0.267443 0.979644
4 -0.462765 -1.403292 -1.960940
5 NaN -0.600053 NaN
Je ne suis pas sûr pourquoi votre pivot ne fonctionne pas (il me semble un peu comme il devrait, mais je pourrais me tromper), mais il ne semble pas fonctionner (ou du moins pas donner une erreur) si je laisse de côté 'struct_id'. Bien sûr, ce n'est pas vraiment une solution utile pour l'ensemble complet de données où vous avez plus d'une valeurs différentes pour "struct_id".
df.pivot(columns='score_type_name',values='score_value',index='resNum')
score_type_name fa_dun fa_dun_dev fa_dun_rot fa_dun_semi omega
resNum
1 2.185618 0.000027 NaN 2.185591 0.064840
2 1.378923 0.028560 1.350362 NaN 0.222345
3 0.020352 0.025507 -0.005156 NaN 0.005106
4 4.218029 0.003712 NaN 4.214317 0.212160
5 3.663050 0.004953 NaN NaN 0.061867
score_type_name p_aa_pp rama ref
resNum
1 NaN NaN -1.191180
2 -0.442467 -0.795161 0.249477
3 -0.096847 0.267443 0.979644
4 -0.462765 -1.403292 -1.960940
5 NaN -0.600053 NaN
Modifier pour ajouter:reset_index() va passer d'un multi-index (hiérarchique) à un style plus plat. Il y a encore une certaine hiérarchie dans les noms de colonne, parfois la façon la plus facile de se débarrasser de ceux-ci est juste de faire df.columns=['var1','var2',...] bien qu'il y ait des moyens plus sophistiqués si vous faites des recherches.
df.set_index(['struct_id','resNum','score_type_name']).unstack().reset_index()
struct_id resNum score_value
score_type_name fa_dun fa_dun_dev fa_dun_rot
0 4294967297 1 2.185618 0.000027 NaN
1 4294967297 2 1.378923 0.028560 1.350362
2 4294967297 3 0.020352 0.025507 -0.005156
3 4294967297 4 4.218029 0.003712 NaN
4 4294967297 5 3.663050 0.004953 NaN
pour ceux qui s'intéressent encore à la différence entre pivot et pivot_table, il y a principalement deux différences:
pivot_tableest une généralisation de l'pivotqui peut gérer les valeurs en double pour un pivoté index/colonne paire. Plus précisément, vous pouvez donnerpivot_tableune liste de fonctions d'agrégation à l'aide argument mot-cléaggfunc. La valeur par défautaggfuncpivot_tablenumpy.mean.pivot_tablesupporte également l'utilisation de plusieurs colonnes pour l'indice de colonne et de l' pivoté tableau. Un index hiérarchique sera généré automatiquement pour vous.
réf:pivot et pivot_table
Je l'ai un peu débogué.
- Le DataFrame.pivot () et DataFrame.pivot_table() sont différentes.
- pivot () n'accepte pas de liste pour index.
- pivot_table() accepte.
en interne, les deux utilisent reset_index()/stack()/unstack() pour faire le travail.
pivot() est juste un raccourci pour une utilisation simple, je pense.
une Autre mise en garde:
pivot_table ne permettra que les types numériques comme " values=", alors que pivot prendra les types de chaîne comme " values=".
pour obtenir le dataframe que vous avez obtenu à partir du pivot_table appel dans le format que vous voulez:
pivoted.columns.name=None ## remove the score_type_name
result = pivoted.reset_index() ## puts index columns back into dataframe body
l'extrait donné peut vous aider à aplatir davantage l'apparence de votre dataframe
df.set_index(['struct_id','resNum','score_type_name']).unstack().reset_index()
df.loc[:,['struct_id','resNum','fa_dun','fa_dun_dev','fa_dun_rot']]