Pandas, DataFrame: diviser une colonne en plusieurs colonnes
j'ai le texte suivant DataFrame. Je me demande s'il est possible de fractionner la colonne "données" en plusieurs colonnes. E. g., à partir de ceci:
ID Date data 6 21/05/2016 A: 7, B: 8, C: 5, D: 5, A: 8 6 21/01/2014 B: 5, C: 5, D: 7 6 02/04/2013 A: 4, D:7 7 05/06/2014 C: 25 7 12/08/2014 D: 20 8 18/04/2012 A: 2, B: 3, C: 3, E: 5, B: 4 8 21/03/2012 F: 6, B: 4, F: 5, D: 6, B: 4
en:
ID Date data A B C D E F 6 21/05/2016 A: 7, B: 8, C: 5, D: 5, A: 8 15 8 5 5 0 0 6 21/01/2014 B: 5, C: 5, D: 7 0 5 5 7 0 0 6 02/04/2013 B: 4, D: 7, B: 6 0 10 0 7 0 0 7 05/06/2014 C: 25 0 0 25 0 0 0 7 12/08/2014 D: 20 0 0 0 20 0 0 8 18/04/2012 A: 2, B: 3, C: 3, E: 5, B: 4 2 7 3 0 5 0 8 21/03/2012 F: 6, B: 4, F: 5, D: 6, B: 4 0 8 0 6 0 11
j'ai essayé pandas scinde une chaîne en colonnes et pandas: Comment diviser un texte dans une colonne en plusieurs rangées? mais ça ne fonctionne pas dans mon cas.
EDIT
il y a un peu de complexité la colonne " données "contient des valeurs en double, par exemple dans la première ligne" A "est répété, et donc ces valeurs sont additionnées sous la colonne" A " (voir deuxième tableau).
10
demandé sur
Community
2016-07-14 23:59:41
2 réponses
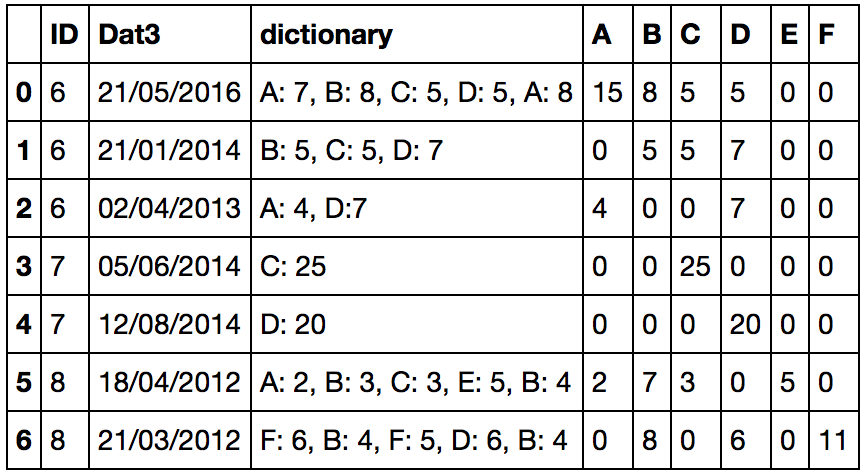
Voici une fonction qui peut convertir la chaîne en un dictionnaire et agréger les valeurs basées sur la clé; après la conversion, il sera facile d'obtenir les résultats avec le pd.Series méthode:
def str_to_dict(str1):
import re
from collections import defaultdict
d = defaultdict(int)
for k, v in zip(re.findall('[A-Z]', str1), re.findall('\d+', str1)):
d[k] += int(v)
return d
pd.concat([df, df['dictionary'].apply(str_to_dict).apply(pd.Series).fillna(0).astype(int)], axis=1)
7
répondu
Psidom
2016-07-14 21:41:12
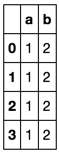
df = pd.DataFrame([
[6, "a: 1, b: 2"],
[6, "a: 1, b: 2"],
[6, "a: 1, b: 2"],
[6, "a: 1, b: 2"],
], columns=['ID', 'dictionary'])
def str2dict(s):
split = s.strip().split(',')
d = {}
for pair in split:
k, v = [_.strip() for _ in pair.split(':')]
d[k] = v
return d
df.dictionary.apply(str2dict).apply(pd.Series)
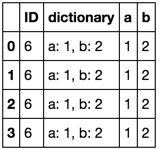
Ou:
pd.concat([df, df.dictionary.apply(str2dict).apply(pd.Series)], axis=1)
3
répondu
piRSquared
2016-07-14 21:43:55