Sortie de la différence dans deux DataFrames Pandas côte à côte-mettant en évidence la différence
j'essaie de mettre en évidence exactement ce qui a changé entre deux images de données.
supposons que j'ai deux DataFrames Python Pandas:
"StudentRoster Jan-1":
id Name score isEnrolled Comment
111 Jack 2.17 True He was late to class
112 Nick 1.11 False Graduated
113 Zoe 4.12 True
"StudentRoster Jan-2":
id Name score isEnrolled Comment
111 Jack 2.17 True He was late to class
112 Nick 1.21 False Graduated
113 Zoe 4.12 False On vacation
mon but est de produire une table HTML qui:
- identifie les lignes qui ont changé (peut être int, float, booléen, string)
-
sorties avec les mêmes valeurs, anciennes et nouvelles (idéalement dans un tableau HTML) de sorte que le consommateur peut voir clairement ce qui a changé entre deux dataframes:
"StudentRoster Difference Jan-1 - Jan-2": id Name score isEnrolled Comment 112 Nick was 1.11| now 1.21 False Graduated 113 Zoe 4.12 was True | now False was "" | now "On vacation"
je suppose que je pourrais faire une comparaison ligne par ligne et colonne par colonne, mais y a-t-il un moyen plus facile?
11 réponses
La première partie est similaire à Constantine, vous pouvez obtenir le booléen dont les lignes sont vides*:
In [21]: ne = (df1 != df2).any(1)
In [22]: ne
Out[22]:
0 False
1 True
2 True
dtype: bool
alors on peut voir quelles entrées ont changé:
In [23]: ne_stacked = (df1 != df2).stack()
In [24]: changed = ne_stacked[ne_stacked]
In [25]: changed.index.names = ['id', 'col']
In [26]: changed
Out[26]:
id col
1 score True
2 isEnrolled True
Comment True
dtype: bool
ici la première entrée est l'index et la seconde les colonnes qui ont été modifiées.
In [27]: difference_locations = np.where(df1 != df2)
In [28]: changed_from = df1.values[difference_locations]
In [29]: changed_to = df2.values[difference_locations]
In [30]: pd.DataFrame({'from': changed_from, 'to': changed_to}, index=changed.index)
Out[30]:
from to
id col
1 score 1.11 1.21
2 isEnrolled True False
Comment None On vacation
* Note: il est important que df1 et df2 partagent le même index ici. Pour surmonter cette ambiguïté , vous pouvez vous assurer que vous regardez seulement les étiquettes partagées en utilisant df1.index & df2.index , mais je pense que je vais laisser cela comme un exercice.
mettant en évidence la différence entre deux images de données
il est possible d'utiliser la propriété de style DataFrame pour mettre en évidence la couleur de fond des cellules où il y a une différence.
utilisant les données de l'exemple de la question originale
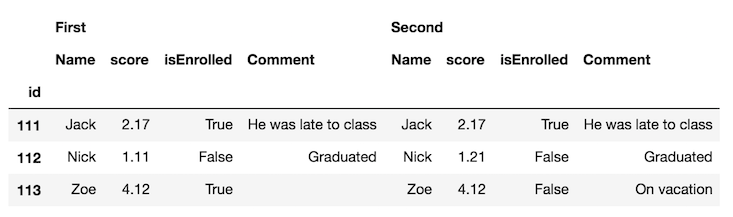
la première étape est de concaténer les images de données horizontalement avec la fonction concat et de distinguer chaque image avec le keys paramètre:
df_all = pd.concat([df.set_index('id'), df2.set_index('id')],
axis='columns', keys=['First', 'Second'])
df_all
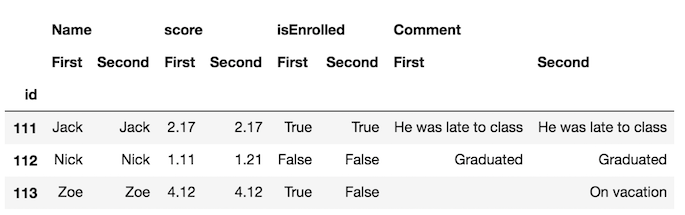
il est probablement plus facile d'échanger les niveaux de colonnes et de mettre les mêmes noms de colonnes les uns à côté des autres:
df_final = df_all.swaplevel(axis='columns')[df.columns[1:]]
df_final
Maintenant, il est beaucoup plus facile de repérer les différences dans les images. Mais, nous pouvons aller plus loin et utiliser la propriété style les cellules qui sont différents. Nous définissons une fonction personnalisée pour faire cela que vous pouvez voir dans cette partie de la documentation .
def highlight_diff(data, color='yellow'):
attr = 'background-color: {}'.format(color)
other = data.xs('First', axis='columns', level=-1)
return pd.DataFrame(np.where(data.ne(other, level=0), attr, ''),
index=data.index, columns=data.columns)
df_final.style.apply(highlight_diff, axis=None)
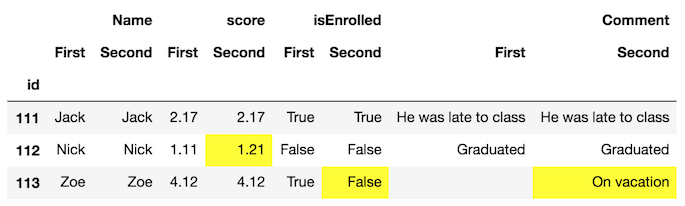
cela mettra en évidence les cellules qui ont toutes deux des valeurs manquantes. Vous pouvez soit les remplir ou fournir la logique supplémentaire de sorte qu'ils ne soient pas mis en évidence.
cette réponse ne fait que prolonger celle de @Andy Hayden, la rendant résistante au moment où les champs numériques sont nan , et l'enveloppant dans une fonction.
import pandas as pd
import numpy as np
def diff_pd(df1, df2):
"""Identify differences between two pandas DataFrames"""
assert (df1.columns == df2.columns).all(), \
"DataFrame column names are different"
if any(df1.dtypes != df2.dtypes):
"Data Types are different, trying to convert"
df2 = df2.astype(df1.dtypes)
if df1.equals(df2):
return None
else:
# need to account for np.nan != np.nan returning True
diff_mask = (df1 != df2) & ~(df1.isnull() & df2.isnull())
ne_stacked = diff_mask.stack()
changed = ne_stacked[ne_stacked]
changed.index.names = ['id', 'col']
difference_locations = np.where(diff_mask)
changed_from = df1.values[difference_locations]
changed_to = df2.values[difference_locations]
return pd.DataFrame({'from': changed_from, 'to': changed_to},
index=changed.index)
donc avec vos données (légèrement modifié pour avoir un NaN dans la colonne score):
import sys
if sys.version_info[0] < 3:
from StringIO import StringIO
else:
from io import StringIO
DF1 = StringIO("""id Name score isEnrolled Comment
111 Jack 2.17 True "He was late to class"
112 Nick 1.11 False "Graduated"
113 Zoe NaN True " "
""")
DF2 = StringIO("""id Name score isEnrolled Comment
111 Jack 2.17 True "He was late to class"
112 Nick 1.21 False "Graduated"
113 Zoe NaN False "On vacation" """)
df1 = pd.read_table(DF1, sep='\s+', index_col='id')
df2 = pd.read_table(DF2, sep='\s+', index_col='id')
diff_pd(df1, df2)
sortie:
from to
id col
112 score 1.11 1.21
113 isEnrolled True False
Comment On vacation
j'ai affronté cette question, mais j'ai trouvé une réponse avant de trouver ce post:
basé sur la réponse d'unutbu, chargez vos données...
import pandas as pd
import io
texts = ['''\
id Name score isEnrolled Date
111 Jack True 2013-05-01 12:00:00
112 Nick 1.11 False 2013-05-12 15:05:23
Zoe 4.12 True ''',
'''\
id Name score isEnrolled Date
111 Jack 2.17 True 2013-05-01 12:00:00
112 Nick 1.21 False
Zoe 4.12 False 2013-05-01 12:00:00''']
df1 = pd.read_fwf(io.BytesIO(texts[0]), widths=[5,7,25,17,20], parse_dates=[4])
df2 = pd.read_fwf(io.BytesIO(texts[1]), widths=[5,7,25,17,20], parse_dates=[4])
...définissez votre fonction diff ...
def report_diff(x):
return x[0] if x[0] == x[1] else '{} | {}'.format(*x)
alors vous pouvez simplement utiliser un panneau pour conclure:
my_panel = pd.Panel(dict(df1=df1,df2=df2))
print my_panel.apply(report_diff, axis=0)
# id Name score isEnrolled Date
#0 111 Jack nan | 2.17 True 2013-05-01 12:00:00
#1 112 Nick 1.11 | 1.21 False 2013-05-12 15:05:23 | NaT
#2 nan | nan Zoe 4.12 True | False NaT | 2013-05-01 12:00:00
d'ailleurs, si vous êtes dans IPython Notebook, vous pouvez utiliser un coloré diff fonction pour donner des couleurs selon que les cellules sont différentes, égales ou Gauche/Droite null:
from IPython.display import HTML
pd.options.display.max_colwidth = 500 # You need this, otherwise pandas
# will limit your HTML strings to 50 characters
def report_diff(x):
if x[0]==x[1]:
return unicode(x[0].__str__())
elif pd.isnull(x[0]) and pd.isnull(x[1]):
return u'<table style="background-color:#00ff00;font-weight:bold;">'+\
'<tr><td>%s</td></tr><tr><td>%s</td></tr></table>' % ('nan', 'nan')
elif pd.isnull(x[0]) and ~pd.isnull(x[1]):
return u'<table style="background-color:#ffff00;font-weight:bold;">'+\
'<tr><td>%s</td></tr><tr><td>%s</td></tr></table>' % ('nan', x[1])
elif ~pd.isnull(x[0]) and pd.isnull(x[1]):
return u'<table style="background-color:#0000ff;font-weight:bold;">'+\
'<tr><td>%s</td></tr><tr><td>%s</td></tr></table>' % (x[0],'nan')
else:
return u'<table style="background-color:#ff0000;font-weight:bold;">'+\
'<tr><td>%s</td></tr><tr><td>%s</td></tr></table>' % (x[0], x[1])
HTML(my_panel.apply(report_diff, axis=0).to_html(escape=False))
import pandas as pd
import io
texts = ['''\
id Name score isEnrolled Comment
111 Jack 2.17 True He was late to class
112 Nick 1.11 False Graduated
113 Zoe 4.12 True ''',
'''\
id Name score isEnrolled Comment
111 Jack 2.17 True He was late to class
112 Nick 1.21 False Graduated
113 Zoe 4.12 False On vacation''']
df1 = pd.read_fwf(io.BytesIO(texts[0]), widths=[5,7,25,21,20])
df2 = pd.read_fwf(io.BytesIO(texts[1]), widths=[5,7,25,21,20])
df = pd.concat([df1,df2])
print(df)
# id Name score isEnrolled Comment
# 0 111 Jack 2.17 True He was late to class
# 1 112 Nick 1.11 False Graduated
# 2 113 Zoe 4.12 True NaN
# 0 111 Jack 2.17 True He was late to class
# 1 112 Nick 1.21 False Graduated
# 2 113 Zoe 4.12 False On vacation
df.set_index(['id', 'Name'], inplace=True)
print(df)
# score isEnrolled Comment
# id Name
# 111 Jack 2.17 True He was late to class
# 112 Nick 1.11 False Graduated
# 113 Zoe 4.12 True NaN
# 111 Jack 2.17 True He was late to class
# 112 Nick 1.21 False Graduated
# 113 Zoe 4.12 False On vacation
def report_diff(x):
return x[0] if x[0] == x[1] else '{} | {}'.format(*x)
changes = df.groupby(level=['id', 'Name']).agg(report_diff)
print(changes)
imprime
score isEnrolled Comment
id Name
111 Jack 2.17 True He was late to class
112 Nick 1.11 | 1.21 False Graduated
113 Zoe 4.12 True | False nan | On vacation
si vos deux dataframes ont les mêmes identifiants, trouver ce qui a changé est en fait assez facile. Juste en faisant frame1 != frame2 vous donnera une base de données booléenne où chaque True est des données qui ont changé. De là, vous pouvez facilement obtenir l'index de chaque rangée changée en faisant changedids = frame1.index[np.any(frame1 != frame2,axis=1)] .
Une approche différente à l'aide de concat et drop_duplicates:
import sys
if sys.version_info[0] < 3:
from StringIO import StringIO
else:
from io import StringIO
import pandas as pd
DF1 = StringIO("""id Name score isEnrolled Comment
111 Jack 2.17 True "He was late to class"
112 Nick 1.11 False "Graduated"
113 Zoe NaN True " "
""")
DF2 = StringIO("""id Name score isEnrolled Comment
111 Jack 2.17 True "He was late to class"
112 Nick 1.21 False "Graduated"
113 Zoe NaN False "On vacation" """)
df1 = pd.read_table(DF1, sep='\s+', index_col='id')
df2 = pd.read_table(DF2, sep='\s+', index_col='id')
#%%
dictionary = {1:df1,2:df2}
df=pd.concat(dictionary)
df.drop_duplicates(keep=False)
sortie:
Name score isEnrolled Comment
id
1 112 Nick 1.11 False Graduated
113 Zoe NaN True
2 112 Nick 1.21 False Graduated
113 Zoe NaN False On vacation
extension de la réponse de @cge, qui est assez cool pour plus de lisibilité du résultat:
a[a != b][np.any(a != b, axis=1)].join(DataFrame('a<->b', index=a.index, columns=['a<=>b'])).join(
b[a != b][np.any(a != b, axis=1)]
,rsuffix='_b', how='outer'
).fillna('')
démonstration Complète exemple:
a = DataFrame(np.random.randn(7,3), columns=list('ABC'))
b = a.copy()
b.iloc[0,2] = np.nan
b.iloc[1,0] = 7
b.iloc[3,1] = 77
b.iloc[4,2] = 777
a[a != b][np.any(a != b, axis=1)].join(DataFrame('a<->b', index=a.index, columns=['a<=>b'])).join(
b[a != b][np.any(a != b, axis=1)]
,rsuffix='_b', how='outer'
).fillna('')
après avoir tripoté la réponse de @journois, j'ai réussi à la faire fonctionner en utilisant MultiIndex au lieu du Panneau en raison de la dépose du Panneau .
d'abord, créer quelques données factices:
df1 = pd.DataFrame({
'id': ['111', '222', '333', '444', '555'],
'let': ['a', 'b', 'c', 'd', 'e'],
'num': ['1', '2', '3', '4', '5']
})
df2 = pd.DataFrame({
'id': ['111', '222', '333', '444', '666'],
'let': ['a', 'b', 'c', 'D', 'f'],
'num': ['1', '2', 'Three', '4', '6'],
})
alors, définissez votre fonction diff , dans ce cas je vais utiliser celui de sa réponse report_diff reste le même:
def report_diff(x):
return x[0] if x[0] == x[1] else '{} | {}'.format(*x)
alors, je vais concaténer le des données dans un MultiIndex dataframe:
df_all = pd.concat(
[df1.set_index('id'), df2.set_index('id')],
axis='columns',
keys=['df1', 'df2'],
join='outer'
)
df_all = df_all.swaplevel(axis='columns')[df1.columns[1:]]
et enfin je vais appliquer le report_diff dans chaque groupe de colonnes:
df_final.groupby(level=0, axis=1).apply(lambda frame: frame.apply(report_diff, axis=1))
Ce sorties:
let num
111 a 1
222 b 2
333 c 3 | Three
444 d | D 4
555 e | nan 5 | nan
666 nan | f nan | 6
Et c'est tout!
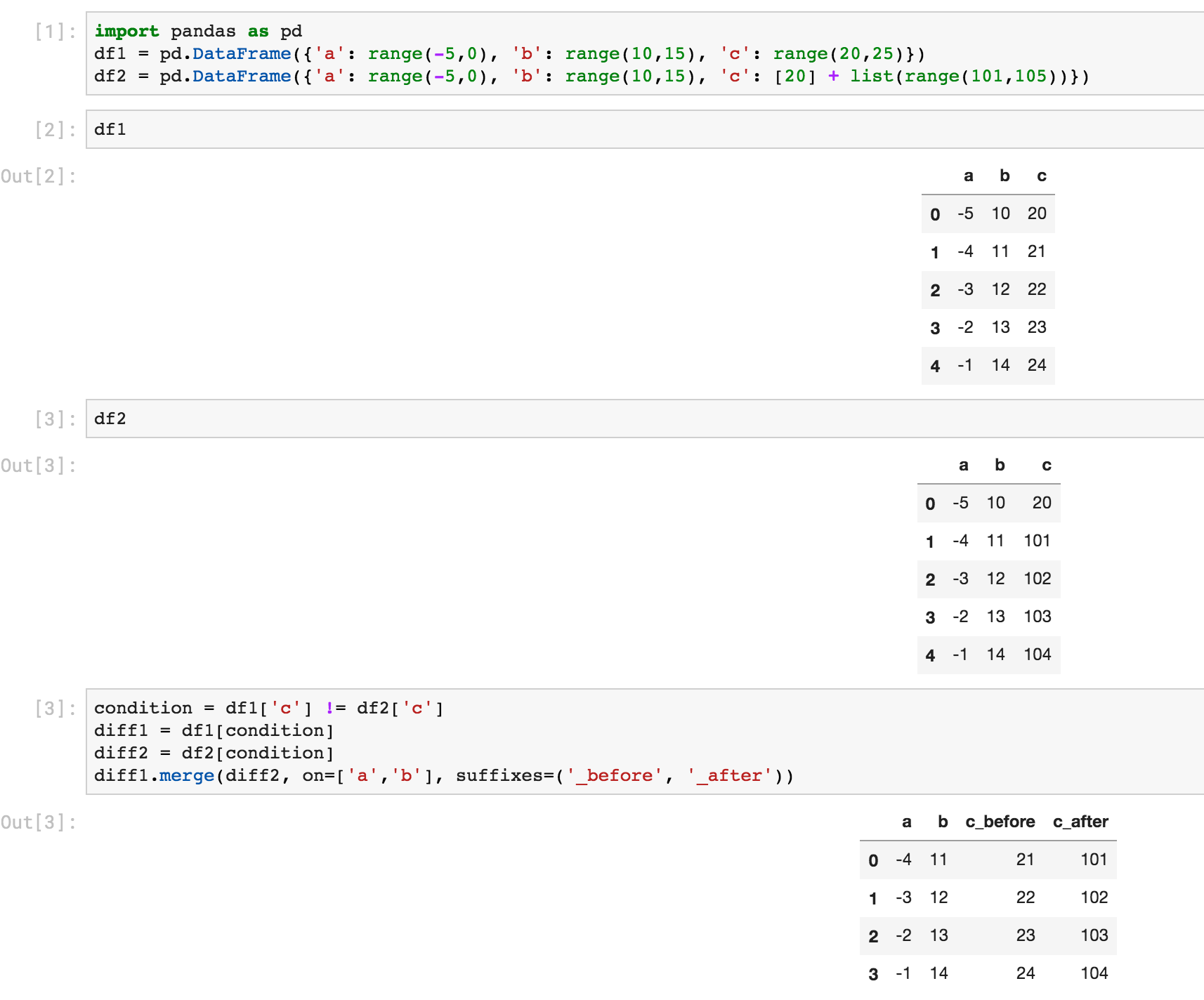
voici une autre façon d'utiliser select et merge:
In [6]: # first lets create some dummy dataframes with some column(s) different
...: df1 = pd.DataFrame({'a': range(-5,0), 'b': range(10,15), 'c': range(20,25)})
...: df2 = pd.DataFrame({'a': range(-5,0), 'b': range(10,15), 'c': [20] + list(range(101,105))})
In [7]: df1
Out[7]:
a b c
0 -5 10 20
1 -4 11 21
2 -3 12 22
3 -2 13 23
4 -1 14 24
In [8]: df2
Out[8]:
a b c
0 -5 10 20
1 -4 11 101
2 -3 12 102
3 -2 13 103
4 -1 14 104
In [10]: # make condition over the columns you want to comapre
...: condition = df1['c'] != df2['c']
...:
...: # select rows from each dataframe where the condition holds
...: diff1 = df1[condition]
...: diff2 = df2[condition]
In [11]: # merge the selected rows (dataframes) with some suffixes (optional)
...: diff1.merge(diff2, on=['a','b'], suffixes=('_before', '_after'))
Out[11]:
a b c_before c_after
0 -4 11 21 101
1 -3 12 22 102
2 -2 13 23 103
3 -1 14 24 104
Voici la même chose d'une capture D'écran de Jupyter:
une fonction qui trouve une différence asymétrique entre deux bases de données est implémentée ci-dessous: (Basé sur différence pour les pandas ) GIST: https://gist.github.com/oneryalcin/68cf25f536a25e65f0b3c84f9c118e03
def diff_df(df1, df2, how="left"):
"""
Find Difference of rows for given two dataframes
this function is not symmetric, means
diff(x, y) != diff(y, x)
however
diff(x, y, how='left') == diff(y, x, how='right')
Ref: /q/set-difference-for-pandas-53354/"""
if (df1.columns != df2.columns).any():
raise ValueError("Two dataframe columns must match")
if df1.equals(df2):
return None
elif how == 'right':
return pd.concat([df2, df1, df1]).drop_duplicates(keep=False)
elif how == 'left':
return pd.concat([df1, df2, df2]).drop_duplicates(keep=False)
else:
raise ValueError('how parameter supports only "left" or "right keywords"')
exemple:
df1 = pd.DataFrame(d1)
Out[1]:
Comment Name isEnrolled score
0 He was late to class Jack True 2.17
1 Graduated Nick False 1.11
2 Zoe True 4.12
df2 = pd.DataFrame(d2)
Out[2]:
Comment Name isEnrolled score
0 He was late to class Jack True 2.17
1 On vacation Zoe True 4.12
diff_df(df1, df2)
Out[3]:
Comment Name isEnrolled score
1 Graduated Nick False 1.11
2 Zoe True 4.12
diff_df(df2, df1)
Out[4]:
Comment Name isEnrolled score
1 On vacation Zoe True 4.12
# This gives the same result as above
diff_df(df1, df2, how='right')
Out[22]:
Comment Name isEnrolled score
1 On vacation Zoe True 4.12