Détection des valeurs aberrantes dans l'exploration de données [fermé]
j'ai quelques questions concernant la détection des valeurs aberrantes:
pouvons-nous trouver des valeurs aberrantes en utilisant k-means et est-ce une bonne approche?
Existe-t-il un algorithme de regroupement qui n'accepte aucune entrée de l'utilisateur?
pouvons-nous utiliser une machine vectorielle de soutien ou tout autre algorithme d'apprentissage supervisé pour la détection des valeurs aberrantes?
Quels sont les avantages et les inconvénients de chaque approche?
4 réponses
je vais me limiter à ce que je pense être essentiel pour donner quelques indices sur toutes vos questions, parce que c'est le sujet d'un grand nombre de manuels et ils pourraient probablement être mieux abordés dans des questions séparées.
Je n'utiliserais pas k-means pour repérer les valeurs aberrantes dans un ensemble de données multivariées, pour la simple raison que l'algorithme de k-means n'est pas construit à cette fin: vous finirez toujours par trouver une solution qui minimise la somme totale des les carrés (et donc maximise la SS entre les grappes parce que la variance totale est fixe), et la ou les valeurs aberrantes ne définiront pas nécessairement leur propre grappe. Prenons L'exemple suivant dans R:
set.seed(123) sim.xy <- function(n, mean, sd) cbind(rnorm(n, mean[1], sd[1]), rnorm(n, mean[2],sd[2])) # generate three clouds of points, well separated in the 2D plane xy <- rbind(sim.xy(100, c(0,0), c(.2,.2)), sim.xy(100, c(2.5,0), c(.4,.2)), sim.xy(100, c(1.25,.5), c(.3,.2))) xy[1,] <- c(0,2) # convert 1st obs. to an outlying value km3 <- kmeans(xy, 3) # ask for three clusters km4 <- kmeans(xy, 4) # ask for four clusterscomme on peut le voir dans la figure suivante, la valeur excentrée n'est jamais récupérée en tant que telle: elle appartiendra toujours à l'un des autres clusters.
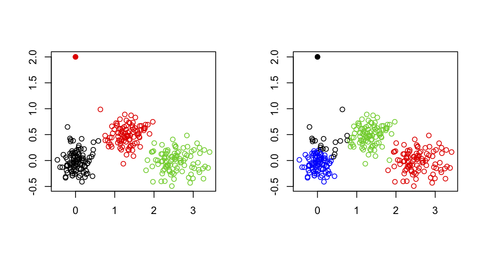
Une possibilité, cependant, est d'utiliser une approche en deux étapes où l'on enlève les points extrêmes (ici définis comme un vecteur éloigné de leurs centroïdes d'amas) d'une manière itérative, comme décrit dans l'article suivant: amélioration des K-Means par suppression des valeurs aberrantes (Hautamäki,et al.).
cela ressemble quelque peu à ce qui est fait dans les études génétiques pour détecter et enlever les individus qui présentent une erreur de génotypage, ou les individus qui sont des frères et sœurs/jumeaux (ou quand nous voulons identifier la sous-structure de la population), alors que nous voulons seulement garder sans rapport dans ce cas, nous utilisons une échelle multidimensionnelle (qui est équivalente à PCA, jusqu'à une constante pour les deux premiers axes) et supprimons les observations au-dessus ou au-dessous de 6 SD sur l'un quelconque des 10 ou 20 axes supérieurs (voir, par exemple, Structure de la Population et analyse des conditions de vie, Patterson et coll., PLoS Genetics 2006 2(12)).
une alternative courante est d'utiliser des distances de mahalanobis robustes ordonnées qui peuvent être tracées (dans un graphique QQ) par rapport à la les quantiles d'un khi-deux, comme indiqué dans le document suivant:
R. G. Garrett (1989). Le chi-carré: un outils pour multivariée des valeurs aberrantes reconnaissance. Journal de l'Exploration Géochimique 32(1/3): 319-341.
(Il est disponible dans les mvoutlier R package.)
Cela dépend de ce que vous appelez la saisie de l'utilisateur. J'interprète votre question comme si certains l'algorithme peut traiter automatiquement une matrice de distance ou des données brutes et s'arrêter sur un nombre optimal de grappes. Si c'est le cas, et pour tout algorithme de partitionnement basé sur la distance, alors vous pouvez utiliser n'importe lequel des indices de validité disponibles pour l'analyse de regroupement; un bon aperçu est donné dans
Handl, J., Knowles, J., et Kell, D. B. (2005). Calcul de validation de cluster dans la post-génomique de l'analyse des données. Bioinformatique 21 (15): 3201-3212.
que j'ai discuté sur Validation Croisée. Vous pouvez par exemple exécuter plusieurs instances de l'algorithme sur différents échantillons aléatoires (en utilisant bootstrap) des données, pour une gamme de nombres d'amas (disons, k=1 à 20) et sélectionner k selon les critères optimisés taht a été considérée (largeur de silhouette moyenne, corrélation cophénétique, etc.); il peut être entièrement automatisé, pas besoin de la saisie de l'utilisateur.
Il existe d'autres formes de regroupement, basé sur la densité (les grappes sont vues comme des régions où les objets sont inhabituellement communs) ou la distribution (les grappes sont des ensembles d'objets qui suivent une distribution de probabilité donnée). Regroupement basé sur le modèle, tel qu'il est mis en œuvre dans Mclust, par exemple, permet d'identifier les grappes dans un ensemble de données multivariées en couvrant une gamme de formes pour la matrice de variance-covariance pour un nombre variable de grappes et de choisir le meilleur modèle selon le BIC critère.
Il s'agit d'un sujet brûlant dans la classification, et certaines études ont mis l'accent sur la MVS pour détecter les valeurs aberrantes, surtout lorsqu'elles sont mal classées. Une simple requête Google retournera beaucoup de résultats, par exemple Machine à Vecteurs de Support pour la Détection des valeurs Aberrantes dans le Cancer du Sein de la Survie de Prédiction par Thongkam et al. ( Lecture Notes in Computer Science 2008 4977/2008 99-109; cet article comprend une comparaison avec les méthodes d'ensemble). La très de base l'idée est d'utiliser un SVM d'une seule classe pour capturer la structure principale des données en y ajustant une distribution multivariée (par exemple gaussienne); les objets qui sur ou juste à l'extérieur de la limite peuvent être considérés comme des valeurs aberrantes potentielles. (Dans un certain sens, le regroupement basé sur la densité fonctionnerait aussi bien que la définition de ce qu'est vraiment une valeur aberrante est plus simple étant donné une distribution attendue.)
D'autres approches pour l'apprentissage non supervisé, semi-supervisé, ou supervisé sont facilement trouvé sur Google, par exemple
- Hodge, V. J. et Austin, J. a Enquête de Détection de valeurs Aberrantes Méthodologies.
- Vinueza, A. et Grudic, G. Z. détection non supervisée des valeurs aberrantes et apprentissage Semi-supervisé.
- Escalante, H. J. A Comparaison des Algorithmes de Détection de valeurs Aberrantes pour l'Apprentissage de la Machine.
Un sujet connexe est détection d'anomalie, qui vous trouverez un grand nombre de documents.Qui mérite vraiment une nouvelle (et probablement plus) question :-)
1) peut-on trouver des valeurs aberrantes en utilisant k-means, est-ce une bonne approche?
les approches basées sur les grappes sont optimales pour trouver des grappes et peuvent être utilisées pour détecter les valeurs aberrantes les sous-produits. Dans les processus de regroupement, les valeurs aberrantes peuvent affecter les emplacements des centres de regroupement, même en se regroupant en micro-regroupement. Ces caractéristiques font de la grappe approches impossible de compliqué bases de données.
2) y a-t-il un algorithme de regroupement qui n'accepte aucune entrée de l'utilisateur?
peut-être Pouvez-vous acquérir de précieuses connaissances sur ce sujet: Dirichlet Processus De Clustering
l'algorithme de regroupement basé sur Dirichlet peut déterminer de façon adaptative le nombre de grappes en fonction de la distribution des données d'observation.
3) pouvons-nous utiliser une machine vectorielle de soutien ou tout autre algorithme d'apprentissage supervisé pour la détection des valeurs aberrantes?
tout algorithme D'apprentissage supervisé nécessite suffisamment de données de formation étiquetées construire des classificateurs. Cependant, un ensemble équilibré de données de formation n'est pas toujours disponible pour les problèmes réels, tels que la détection d'intrusion, les diagnostics médicaux. Selon la définition de Hawkins Aberrantes("Identification des valeurs Aberrantes". Chapman et Hall, Londres, 1980), le nombre de données normales est beaucoup plus élevé que celui des valeurs aberrantes. La plupart des algorithmes d'apprentissage supervisés ne peuvent pas atteindre un classificateur efficace sur l'ensemble de données déséquilibré ci-dessus.
4) Quels sont les avantages et les inconvénients de chaque approche?
au cours des dernières décennies, la recherche sur la détection des valeurs aberrantes varie du calcul global à l'analyse locale, et les descriptions des valeurs aberrantes varient des interprétations binaires aux représentations probabilistes. Selon les hypothèses des modèles de détection des valeurs aberrantes, les algorithmes de détection des valeurs aberrantes peuvent être divisés en quatre catégories: les algorithmes basés sur des statistiques, les algorithmes basés sur des grappes, les algorithmes basés sur le voisinage le plus proche et les algorithmes basés sur des classificateurs. Il existe plusieurs études utiles sur la détection des valeurs aberrantes:
Hodge, V. et Austin, J. "Une enquête de détection de valeurs aberrantes méthodes", Revue d'Intelligence Artificielle, Révision, 2004.
k-means est plutôt sensible au bruit dans les données. Cela fonctionne mieux lorsque vous retirez les valeurs aberrantes à l'avance.
Non. Cluster algorithme d'analyse qui prétend être sans paramètre est généralement très limitée, et a souvent des paramètres cachés - un paramètre commun est la fonction de distance, par exemple. Tout algorithme d'analyse de groupe flexible acceptera au moins une fonction de distance personnalisée.
une classe les classificateurs sont une méthode populaire d'apprentissage automatique de la détection des valeurs aberrantes. Cependant, les approches supervisées ne sont pas toujours appropriées pour détecter les objets _previewly_unseen_. De plus, ils peuvent s'en servir lorsque les données contiennent déjà des valeurs aberrantes.
Chaque approche a ses avantages et inconvénients, c'est pourquoi elles existent. Dans un contexte réel, vous devrez essayer la plupart d'entre eux pour voir ce qui fonctionne pour vos données et de la configuration. C'est pourquoi la détection des valeurs aberrantes est appelé connaissance découverte - vous avez à explorer si vous voulez découvrir quelque chose ...
Vous voudrez peut-être avoir un coup d'oeil à l' ELKI cadre de l'exploration de données. Il s'agit censément de la plus grande collection d'algorithmes d'exploration de données de détection de valeurs aberrantes. Il s'agit d'un logiciel libre, mis en œuvre en Java, qui comprend plus de 20 algorithmes de détection des valeurs aberrantes. Voir le liste des algorithmes disponibles.
Notez que la plupart de ces algorithmes sont ce n'est pas basée sur le regroupement. De nombreux algorithmes de regroupement (en particulier k-means) vont essayer de regrouper instances "quoi qu'il arrive". Seuls quelques algorithmes de clustering (par exemple DBSCAN) considèrent en fait le cas qui peut-être pas toutes les instances appartiennent à des clusters! Ainsi, pour certains algorithmes, les valeurs aberrantes sera effectivement prévenir un bon regroupement!