Amélioration de l'algorithme de ROC
je crée un ROC basé sur Java. Mon objectif est d'extraire du texte d'un fichier vidéo (post-traitement).
il a été une recherche difficile, en essayant de trouver libre, open-source OCR qui fonctionne purement sur Java. J'ai trouvé que Tess4J était la seule option populaire, mais étant donné le besoin de l'interface native, je me suis senti en quelque sorte enclin à développer l'algorithme à partir de zéro.
j'ai besoin de créer un fiable OCR qui identifie correctement l'anglais alphabets (informatisé Dactylographiez seulement, pas de texte écrit à la main) avec une précision raisonnable, étant donné que la région dans laquelle le texte se trouve dans le cadre vidéo est prédéfinie. On peut aussi supposer que la couleur du texte est donnée.
Ce que j'ai fait jusqu'à présent:
(Tous les traitement de l'image fait à l'aide de Java liaisons pour openCV)
j'ai extrait des fonctionnalités pour la formation de mon classificateur en utilisant:
<!-A. intensités des pixels, après sous-échantillonnage de l'image de caractère de 12 X 12 de la résolution. (144 disposent de vecteurs)B. Gabor transformée en ondelettes dans 8 différents angles (0, 11.25, 22.5 ...etc) et l'énergie calculée en utilisant la valeur quadratique moyenne du signal pour tous ces angles. (8 disposent de vecteurs)
A+B me donne le vecteur caractéristique des images. (Total de 152 vecteurs caractéristiques)
j'ai 62 classes pour la classification, c'est-à-dire. 0,1,2...9 / a,b,c, D...y, z | A, B, C, D...Y, Z
j'former le classificateur à l'aide de 20 x 62 échantillons (20 pour chaque classe).
pour la classification, j'ai utilisé les deux approches suivantes:
A. ANN avec 1 couche cachée (de 120 noeuds). La couche d'entrée a 152 noeuds et la sortie a 62. La couche cachée et la couche de sortie ont la fonction d'activation sigmoïde et le réseau est formé en utilisant la Propagation élastique arrière.
B. classification kNN pour la totalité des 152 dimension.
là Où j'en suis:
k-La recherche du voisin le plus proche s'avère être un meilleur Classificateur que le réseau neuronal (jusqu'à présent). Cependant, même avec kNN, je trouve difficile de classer des lettres comme:
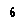 OR
OR  .
.
de plus, il classifie  comme Z... pour ne nommer que quelques-unes des anomalies.
comme Z... pour ne nommer que quelques-unes des anomalies.
ce que je cherche:
je veux trouver de la manière suivante:
pourquoi ANN est-elle sous-performante? Quelle configuration de réseau utiliser pour augmenter les performances? Pouvons-nous peaufiner ANN pour mieux performer que kNN search?
quels autres vecteurs de fonctionnalité puis-je utiliser pour rendre la ROC plus robuste?
toute autre suggestion d'optimisation des performances est la bienvenue.
2 réponses
KNN algorithme n'a pas besoin de beaucoup de réglage, contrairement aux réseaux neuronaux, de sorte que vous pouvez obtenir de bonnes performances facilement, mais un perceptron multicouche peut dépasser kNN kNN. Actuellement, je pense que le meilleur résultat sont atteints en utilisant deep-learning, vous devriez jeter un oeil à convolutional neural network par exemple.
à Partir de wikipedia:
un CNN est composé d'une ou de plusieurs couches de convolutions avec couches (correspondant à ceux typiques artificielle neuronal réseaux) sur le dessus. Il utilise également des poids liés et des couches de mise en commun. Ce l'architecture permet à CNNs de profiter de la structure 2D de les données d'entrée. En comparaison avec d'autres architectures profondes, les réseaux neuronaux commencent à montrer des résultats supérieurs dans les deux images et des applications vocales. Ils peuvent également être formés avec backropagation. Les CNN sont plus faciles à former que d'autres réguliers, profonds, les réseaux neuronaux de feed-forward et ont beaucoup moins de paramètres à estimation, ce qui en fait une architecture très attrayante à utiliser.
en parlant de votre MLP, il y a beaucoup d'algorithmes pour rechercher de meilleurs paramètres, par exemple la recherche de grille ou l'optimisation d'essaims. J'aime utiliser un algorithme génétique pour régler les paramètres d'un NN, c'est assez simple et donne de bonnes performances.
je vous recommande JGap, une belle algorithme génétique cadre en java, ce qui peut être utilisé en dehors-de-le-boîte :)
Voici le JGAP de la présentation de l'algorithme génétique, qui serait mieux que n'importe quel de ma présentation:
les algorithmes génétiques (GA) sont des algorithmes de recherche qui processus de la sélection naturelle. Ils commencent par un échantillon de des solutions potentielles qui évoluent ensuite vers un ensemble de solutions plus optimales solution. Dans l'ensemble de l'échantillon, les solutions qui sont pauvres ont tendance à mourir hors tandis que de meilleures solutions s'accouplent et propagent leur avantage des traits, introduisant ainsi plus de des solutions dans l'ensemble qui se vantent plus grand potentiel (la taille totale de l'ensemble reste constante; pour chaque nouveau solution ajoutée, une ancienne est retirée). Une petite mutation aléatoire aide garantie qu'un ensemble ne stagnera pas et simplement remplir avec de nombreux des copies de la même solution.
En général, les algorithmes génétiques ont tendance à travailler mieux que les traditionnels algorithmes d'optimisation parce qu'ils sont moins susceptibles de s'égarer par optima locaux. C'est parce qu'ils ne font pas usage de un seul point règles de transition pour passer d'une seule instance dans la solution l'espace à l'autre. Au lieu de cela, les GA tirent avantage de tout un ensemble de les solutions se répartissent sur l'ensemble de l'espace de solution, expérimenter sur de nombreux optima potentiels.
Cependant, pour que les algorithmes génétiques pour travailler efficacement, quelques les critères doivent être respectés:
Il doit être relativement facile à évaluer comment la "bonne" solution potentielle par rapport aux autres potentiels solution.
il doit être possible de décomposer une solution potentielle en parties discrètes cela peut varier indépendamment. Ces pièces deviennent les "gènes" de l' algorithme génétique.
enfin, les algorithmes génétiques sont mieux adaptés aux situations où la "bonne" réponse suffit, même si ce n'est pas la meilleure réponse.
pour les vecteurs caractéristiques: avez-vous normalisé les intensités? Peut-être utiliser l'égalisation d'histogramme.
pour la classification: jetez un coup d'oeil à t-SNE. Il s'agit d'une méthode stochastique qui consiste à réduire les caractéristiques dimensionnelles élevées dans un plan 2D plus facile à regrouper.