Num PY: trouver le premier indice de valeur rapidement
Comment puis-je trouver l'index de la première occurrence d'un nombre dans un tableau Numpy? La vitesse est importante pour moi. Je ne suis pas intéressé par les réponses suivantes parce qu'ils scannent l'ensemble du tableau et ne s'arrêtent pas quand ils trouvent la première occurrence:
itemindex = numpy.where(array==item)[0][0]
nonzero(array == item)[0][0]
Note 1: aucune des réponses à cette question ne semble pertinente y a-t-il une fonction Numpy pour retourner le premier index de quelque chose dans un tableau?
Note 2: Utilisation une méthode compilée en C est préférée à une boucle Python.
14 réponses
il y a une demande de caractéristique pour cette programmée pour Numpy 2.0.0: https://github.com/numpy/numpy/issues/2269
Bien qu'il soit trop tard pour vous, mais pour référence future: Utiliser numba ( 1 ) est la façon la plus facile jusqu'à ce que numpy l'implante. Si vous utilisez la distribution Anaconda python, elle doit déjà être installée. Le code sera compilé pour être rapide.
@jit(nopython=True)
def find_first(item, vec):
"""return the index of the first occurence of item in vec"""
for i in xrange(len(vec)):
if item == vec[i]:
return i
return -1
et ensuite:
>>> a = array([1,7,8,32])
>>> find_first(8,a)
2
j'ai fait une référence pour plusieurs méthodes:
-
argwhere -
nonzerocomme dans la question -
.tostring()comme dans la réponse de @Rob Reilink - boucle python
- Fortran "en boucle 1519130920"
le code Python et Fortran sont disponibles. J'ai sauté le favorables à ceux comme la conversion d'une liste.
les résultats à l'échelle logarithmique. L'axe X est la position de l'aiguille (il faut plus de temps pour trouver si c'est plus bas dans le tableau); dernière valeur est une aiguille qui n'est pas dans le tableau. L'axe des ordonnées est le temps de le trouver.
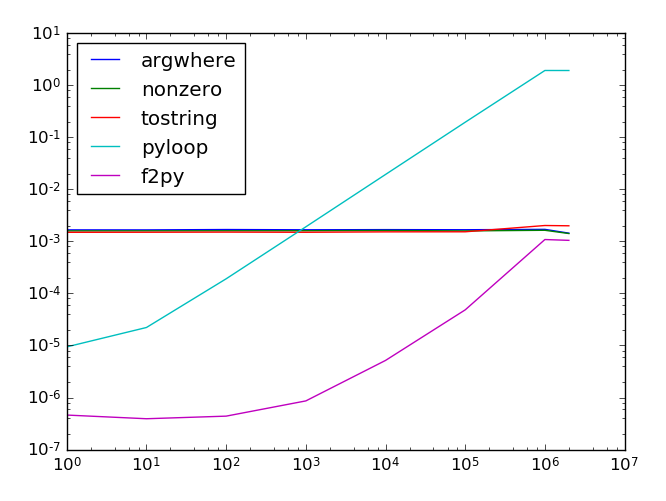
le tableau avait 1 million d'éléments et des tests ont été effectués 100 fois. Les résultats fluctuent encore un peu, mais la tendance qualitative est claire: Python et f2py abandonnent au premier élément pour se dimensionner différemment. Python est trop lent si l'aiguille n'est pas dans le premier 1%, alors que le f2py est rapide (mais vous devez le compiler).
Pour résumer, f2py est la solution la plus rapide , surtout si l'aiguille apparaît assez tôt.
ce n'est pas construit dans ce qui est ennuyeux, mais c'est vraiment juste 2 minutes de travail. Ajouter ce à un fichier appelé search.f90 :
subroutine find_first(needle, haystack, haystack_length, index)
implicit none
integer, intent(in) :: needle
integer, intent(in) :: haystack_length
integer, intent(in), dimension(haystack_length) :: haystack
!f2py intent(inplace) haystack
integer, intent(out) :: index
integer :: k
index = -1
do k = 1, haystack_length
if (haystack(k)==needle) then
index = k - 1
exit
endif
enddo
end
si vous cherchez quelque chose d'autre que integer , changez simplement le type. Puis compilez en utilisant:
f2py -c -m search search.f90
après quoi vous pouvez faire (à partir de Python):
import search
print(search.find_first.__doc__)
a = search.find_first(your_int_needle, your_int_array)
vous pouvez convertir un tableau booléen en chaîne de Python en utilisant array.tostring() puis en utilisant la méthode find ():
(array==item).tostring().find('\x01')
cela implique de copier les données, bien que, puisque les chaînes de Python doivent être immuables. Un avantage est que vous pouvez également rechercher par exemple un bord ascendant en trouvant \x00\x01
je pense que vous avez frappé un problème où une méthode différente et certains a priori connaissance du tableau serait vraiment utile. Le genre de chose où vous avez une probabilité X de trouver votre réponse dans le premier Y pour cent des données. Le fait de diviser le problème avec l'espoir d'avoir de la chance puis de faire cela en python avec une compréhension de liste imbriquée ou quelque chose.
écrire une fonction C pour faire cette force brute n'est pas trop difficile à utiliser ctypes .
le code C que j'ai hacké ensemble (index.c):
long index(long val, long *data, long length){
long ans, i;
for(i=0;i<length;i++){
if (data[i] == val)
return(i);
}
return(-999);
}
et le python:
# to compile (mac)
# gcc -shared index.c -o index.dylib
import ctypes
lib = ctypes.CDLL('index.dylib')
lib.index.restype = ctypes.c_long
lib.index.argtypes = (ctypes.c_long, ctypes.POINTER(ctypes.c_long), ctypes.c_long)
import numpy as np
np.random.seed(8675309)
a = np.random.random_integers(0, 100, 10000)
print lib.index(57, a.ctypes.data_as(ctypes.POINTER(ctypes.c_long)), len(a))
et j'AI 92.
enveloppez le python dans une fonction appropriée et voilà.
la version C est beaucoup plus rapide (~20x) pour cette graine (attention Je ne suis pas bon avec timeit)
import timeit
t = timeit.Timer('np.where(a==57)[0][0]', 'import numpy as np; np.random.seed(1); a = np.random.random_integers(0, 1000000, 10000000)')
t.timeit(100)/100
# 0.09761879920959472
t2 = timeit.Timer('lib.index(57, a.ctypes.data_as(ctypes.POINTER(ctypes.c_long)), len(a))', 'import numpy as np; np.random.seed(1); a = np.random.random_integers(0, 1000000, 10000000); import ctypes; lib = ctypes.CDLL("index.dylib"); lib.index.restype = ctypes.c_long; lib.index.argtypes = (ctypes.c_long, ctypes.POINTER(ctypes.c_long), ctypes.c_long) ')
t2.timeit(100)/100
# 0.005288000106811523
si votre liste est triée , vous pouvez effectuer très rapidement recherche d'index avec le paquet "bisect". C'est O(log(n)) au lieu de O(n).
bisect.bisect(a, x)
trouve x dans le tableau a, certainement plus rapide dans le cas trié que n'importe quelle c-routine passant par tous les premiers éléments (pour des listes assez longues).
Il est bon de savoir parfois.
@tal a déjà présenté une fonction numba pour trouver le premier index mais qui ne fonctionne que pour les tableaux 1D. Avec np.ndenumerate vous pouvez également trouver le premier indice dans un tableau de dimensions arbitrairement:
from numba import njit
import numpy as np
@njit
def index(array, item):
for idx, val in np.ndenumerate(array):
if val == item:
return idx
return None
Exemple de cas:
>>> arr = np.arange(9).reshape(3,3)
>>> index(arr, 3)
(1, 0)
Timings de montrer qu'il est semblable dans la performance x solution:
arr = np.arange(100000)
%timeit index(arr, 5) # 1000000 loops, best of 3: 1.88 µs per loop
%timeit find_first(5, arr) # 1000000 loops, best of 3: 1.7 µs per loop
%timeit index(arr, 99999) # 10000 loops, best of 3: 118 µs per loop
%timeit find_first(99999, arr) # 10000 loops, best of 3: 96 µs per loop
autant que je ne sache que np.tout et np.tous les tableaux booléens sont court-circuités.
dans votre cas, numpy doit passer par le tableau entier deux fois, une fois pour créer la condition booléenne et une seconde fois pour trouver les indices.
Ma recommandation dans ce cas serait d'utiliser cython. Je pense qu'il devrait être facile d'ajuster un exemple pour cette affaire, surtout si vous n'avez pas besoin de beaucoup de flexibilité pour les différents types et formes de dtypes.
j'en avais besoin pour mon travail, alors je me suis formé à L'interface C de Python et Numpy et j'ai écrit la mienne. http://pastebin.com/GtcXuLyd c'est seulement pour les tableaux 1-D, mais fonctionne pour la plupart des types de données (int, float, ou chaînes) et les tests ont montré qu'il est de nouveau environ 20 fois plus rapide que l'approche attendue en Python pur.
juste une note que si vous faites une séquence de recherches, le gain de performance de faire quelque chose d'intelligent comme convertir en chaîne, pourrait être perdu dans la boucle externe si la dimension de recherche n'est pas assez grande. Voir comment la performance de l'itération find1 qui utilise le truc de conversion de chaîne de caractères proposé ci-dessus et find2 qui utilise argmax le long de l'axe interne (plus un ajustement pour assurer une non-correspondance retourne comme -1)
import numpy,time
def find1(arr,value):
return (arr==value).tostring().find('\x01')
def find2(arr,value): #find value over inner most axis, and return array of indices to the match
b = arr==value
return b.argmax(axis=-1) - ~(b.any())
for size in [(1,100000000),(10000,10000),(1000000,100),(10000000,10)]:
print(size)
values = numpy.random.choice([0,0,0,0,0,0,0,1],size=size)
v = values>0
t=time.time()
numpy.apply_along_axis(find1,-1,v,1)
print('find1',time.time()-t)
t=time.time()
find2(v,1)
print('find2',time.time()-t)
sorties
(1, 100000000)
('find1', 0.25300002098083496)
('find2', 0.2780001163482666)
(10000, 10000)
('find1', 0.46200013160705566)
('find2', 0.27300000190734863)
(1000000, 100)
('find1', 20.98099994659424)
('find2', 0.3040001392364502)
(10000000, 10)
('find1', 206.7590000629425)
('find2', 0.4830000400543213)
cela dit, écrit en C serait au moins un peu plus vite que l'autre de ces approches
que pensez-vous de ce
import numpy as np
np.amin(np.where(array==item))
en tant qu'utilisateur de longue date de matlab j'ai été à la recherche d'une solution efficace à ce problème depuis un certain temps. Enfin, j'ai essayé de trouver une solution qui implémente une API similaire à ce qui a été suggéré ici , supportant pour le moment des matrices 1D seulement. Pour l'efficacité, l'extension est écrite en C et devrait donc être assez efficace.
vous trouverez la source, les benchmarks et d'autres détails ici:
https://pypi.python.org/pypi?name=py_find_1st&:action=display
pour l'utilisation dans notre équipe (anaconda sur linux et macos) j'ai fait un programme d'installation anaconda qui simplifie l'installation, vous pouvez l'utiliser comme décrit ici
vous pouvez cacher votre tableau dans un list et utiliser sa méthode index() :
i = list(array).index(item)
autant que je sache, c'est une méthode compilée C.