Des mesures de cycle d'horloge négatives avec rdtsc dos-à-dos?
j'écris un code C pour mesurer le nombre de cycles d'horloge nécessaires pour acquérir un sémaphore. J'utilise le rdtsc, et avant de faire la mesure sur le sémaphore, j'appelle le rdtsc deux fois consécutives, pour mesurer les frais généraux. Je le répète plusieurs fois, dans une boucle, puis j'utilise la valeur moyenne comme charge rdtsc.
est-ce correct, d'utiliser d'abord la valeur moyenne?
néanmoins, le gros problème ici est que parfois je obtenir des valeurs négatives pour la ligne aérienne (pas nécessairement la moyenne,mais au moins les partielles à l'intérieur de la boucle for).
cela affecte également le calcul consécutif du nombre de cycles cpu nécessaires pour l'opération sem_wait() , qui s'avère parfois aussi négative. Si ce que j'ai écrit n'est pas clair, voici une partie du code sur laquelle je travaille.
pourquoi j'obtiens de telles valeurs négatives?
(note de l'éditeur: voir Obtenir le nombre de cycles CPU? pour une façon correcte et portable d'obtenir le timestamp 64 bits complet. Une contrainte asm "=A" n'obtiendra que les 32 bits bas ou haut lorsqu'elle est compilée pour x86-64, selon que l'allocation de registre arrive à choisir RAX ou RDX pour la sortie uint64_t . Il ne sélectionnera pas edx:eax .)
(de l'éditeur 2ème remarque: oups, c'est la réponse à pourquoi nous obtenons des résultats négatifs. Encore la peine de laisser une note ici comme avertissement pour ne pas copier cette implémentation rdtsc .)
#include <semaphore.h>
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <inttypes.h>
static inline uint64_t get_cycles()
{
uint64_t t;
// editor's note: "=A" is unsafe for this in x86-64
__asm volatile ("rdtsc" : "=A"(t));
return t;
}
int num_measures = 10;
int main ()
{
int i, value, res1, res2;
uint64_t c1, c2;
int tsccost, tot, a;
tot=0;
for(i=0; i<num_measures; i++)
{
c1 = get_cycles();
c2 = get_cycles();
tsccost=(int)(c2-c1);
if(tsccost<0)
{
printf("#### ERROR!!! ");
printf("rdtsc took %d clock cyclesn", tsccost);
return 1;
}
tot = tot+tsccost;
}
tsccost=tot/num_measures;
printf("rdtsc takes on average: %d clock cyclesn", tsccost);
return EXIT_SUCCESS;
}
9 réponses
quand Intel a inventé le TSC, il mesurait les cycles CPU. En raison de diverses caractéristiques de gestion de la puissance "cycles par seconde" n'est pas constante; donc TSC était bon à l'origine pour mesurer la performance du code (et mauvais pour mesurer le temps passé).
pour le meilleur et pour le pire; à l'époque, les CPU n'avaient pas vraiment beaucoup de gestion de la puissance, souvent les CPU fonctionnaient à un "cycle par seconde" fixe de toute façon. Certains programmeurs ont eu la mauvaise idée et ont abusé de la TSC pour mesurer le temps et non cycle. Plus tard (lorsque l'utilisation des caractéristiques de gestion de l'énergie est devenue plus courante) ces personnes abusant TSC pour mesurer le temps pleurniché sur tous les problèmes que leur mauvaise utilisation a causé. Les fabricants de CPU (en commençant par AMD) ont changé TSC afin qu'il mesure le temps et non les cycles (ce qui le rend cassé pour mesurer la performance du code, mais correct pour mesurer le temps passé). Cela a causé de la confusion (il était difficile pour le logiciel de déterminer ce que TSC effectivement mesuré), donc un peu plus tard, AMD a ajouté le " TSC Invariant" signal vers CPUID, de sorte que si ce signal est activé, les programmeurs sachent que le TSC est cassé (pour la mesure des cycles) ou fixe (pour la mesure du temps).
Intel a suivi AMD et a modifié le comportement de leur TSC pour mesurer également le temps, et a également adopté le drapeau "TSC Invariant" D'AMD.
cela donne 4 cas différents:
-
TSC mesures à la fois du temps et de la performance (cycles par seconde est constant)
-
TSC mesures de performance pas de temps
-
TSC mesures de temps et de ne pas la performance mais n'utilise pas le "TSC Invariant" drapeau de le dire
-
TSC mesures de temps et de ne pas les performances et n'utiliser le "TSC Invariant" drapeau de le dire (la plupart des Processeurs modernes)
pour les cas où TSC mesure le temps, pour mesurer le rendement/cycles correctement vous il faut utiliser des compteurs de surveillance des performances. Malheureusement, les compteurs de surveillance des performances sont différents selon les CPU (spécifiques au Modèle) et nécessitent l'accès au MSRs (code privilégié). De ce fait, il est très peu pratique pour les applications de mesurer les "cycles".
notez aussi que si le TSC mesure le temps, vous ne pouvez pas savoir quelle échelle de temps il renvoie (combien de nanosecondes dans un "faux cycle") sans utiliser une autre source de temps pour déterminer un facteur d'échelle.
le deuxième problème est que pour les systèmes multi-CPU la plupart des systèmes d'exploitation sont nuls. La bonne façon pour un OS de gérer le TSC est d'empêcher les applications de l'utiliser directement (en positionnant le drapeau TSD dans CR4; de sorte que l'instruction RDTSC provoque une exception). Cela évite diverses vulnérabilités de sécurité (canaux secondaires de synchronisation). Il permet également au système D'exploitation d'émuler le TSC et de s'assurer qu'il renvoie un résultat correct. Par exemple, lorsqu'une application utilise L'instruction RDTSC et causes une exception, le gestionnaire D'exception de L'OS peut trouver un "Global Time stamp" correct à retourner.
bien sûr, différentes UCT ont leur propre TSC. Cela signifie que si une application utilise directement TSC ils obtiennent des valeurs différentes sur des CPU différents. Pour aider les gens à contourner l'échec de l'OS à corriger le problème (en émulant RDTSC comme ils le devraient); AMD a ajouté l'instruction RDTSCP , qui renvoie le TSC et un "ID du processeur" (Intel a fini par adopter le RDTSCP instruction trop). Une application tournant sur un OS cassé peut utiliser le " processeur ID "pour détecter quand ils tournent sur un CPU différent de la dernière fois; et de cette façon (en utilisant l'instruction RDTSCP ) ils peuvent savoir quand" s'est écoulé = TSC - previous_TSC " donne un résultat valide. Cependant, "l'ID du processeur" retourné par cette instruction est juste une valeur dans un MSR, et L'OS doit définir cette valeur sur chaque CPU à quelque chose de différent - sinon RDTSCP dira que le " processeur ID " est zéro sur tous les CPU.
essentiellement; si le CPUs supporte l'instruction RDTSCP , et si L'OS a correctement défini le" processeur ID "(en utilisant le MSR); alors l'instruction RDTSCP peut aider les applications à savoir quand elles ont un mauvais résultat" temps écoulé " (mais il ne fournit pas de toute façon de fixer ou d'éviter le mauvais résultat).
donc, pour faire court, si vous voulez une mesure précise de la performance, vous êtes presque dans la merde. Best vous pouvez espérer de façon réaliste une mesure précise du temps, mais seulement dans certains cas (par exemple, lorsque vous utilisez une machine mono-CPU ou "épinglée" à un CPU spécifique; ou lorsque vous utilisez RDTSCP sur OSs qui le configure correctement tant que vous détectez et rejetez des valeurs invalides).
bien sûr, même dans ce cas, vous obtiendrez des mesures douteuses à cause de choses comme les Qir. Pour cette raison, il est préférable d'exécuter votre code plusieurs fois dans une boucle et jeter tous les résultats qui sont trop supérieur d'autres résultats.
Enfin, si vous voulez vraiment le faire correctement, vous devriez mesurer la surcharge de la mesure. Pour ce faire, vous devez mesurer le temps qu'il faut pour ne rien faire (juste l'instruction RDTSC/RDTSCP seule, tout en écartant les mesures douteuses); puis, soustrayez les frais généraux de la mesure des résultats de la "mesure de quelque chose". Cela vous donne une meilleure estimation du temps "quelque chose" prend en fait.
Note: Si vous pouvez déterrer une copie de Guide de programmation du système Intel depuis la sortie de Pentium (au milieu des années 1990 - Je ne sais pas si c'est encore disponible en ligne - j'en ai archivé des copies depuis les années 1980), Vous constaterez Qu'Intel a documenté le compteur d'horodatage comme quelque chose qui "peut être utilisé pour surveiller et identifier le temps relatif d'occurrence des événements de processeur". Ils ont garanti que (à l'exclusion de l'enroulement de 64 bits) il augmenterait de façon monotone (mais pas qu'il augmenterait à un taux fixe) et qu'il faudrait un minimum de 10 ans avant qu'il enroulé autour. La dernière révision du manuel documente le compteur horodateur avec plus de détails, indiquant que pour les CPU plus anciens (P6, Pentium M, Pentium 4 plus ancien) le compteur horodateur "augmente avec chaque cycle d'horloge interne du processeur" et que" les transitions de Technologie Intel(r) SpeedStep(r) peuvent avoir un impact sur l'horloge du processeur"; et que les CPU plus récents (Pentium 4 Plus Récent, Core Solo, Core Duo, Core 2, Atom) les accroissements TSC à une vitesse constante (et que c'est le comportement aller de l'avant"). Essentiellement, dès le début, c'était un "compteur de cycle interne" (variable) à utiliser pour un horodatage (et non un horodatage à utiliser pour suivre l'Heure de "wall clock"), et ce comportement a changé peu après l'an 2000 (basé sur la date de sortie du Pentium 4).
-
ne pas utiliser la valeur moyenne
utilisez le plus petit ou avg de plus petites valeurs à la place (pour obtenir avg à cause de CACHE) parce que les plus grands ont été interrompus par OS multi tasking.
vous pouvez également vous souvenir de toutes les valeurs, puis trouver la limite de granularité du procédé OS et filtrer toutes les valeurs après cette limite (généralement >
1msqui est facilement détectable)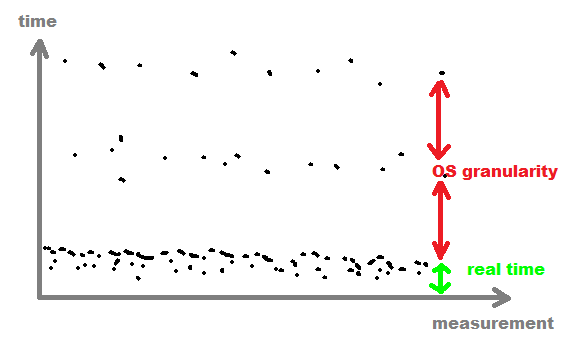
-
pas besoin de mesurer les frais généraux de
RDTSCvous mesurez juste offset par un certain temps et le même offset est présent dans les deux temps et après la soustraction il est parti.
-
pour la source d'horloge variable de
RDTS(comme sur les ordinateurs portables)vous devez changer la vitesse de CPU à son maximum par une boucle de calcul intensif stable habituellement quelques secondes sont suffisantes. Vous devriez mesurer la fréquence CPU de façon continue et commencer à mesurer votre chose seulement quand elle est assez stable.
si vous coder démarre sur un processeur puis Change vers un autre, la différence de timestamp peut être négative en raison du sommeil des processeurs, etc.
Essayez de définir l'affinité du processeur avant de commencer à mesurer.
Je ne vois pas si vous utilisez Windows ou Linux à partir de la question, donc je vais répondre pour les deux.
Windows:
DWORD affinityMask = 0x00000001L;
SetProcessAffinityMask(GetCurrentProcessId(), affinityMask);
Linux:
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(0, &cpuset);
sched_setaffinity (getpid(), sizeof(cpuset), &cpuset)
les autres réponses sont excellentes (allez les lire), mais supposons que rdtsc soit lu correctement. Cette réponse s'attaque au bogue inline-asm qui conduit à des résultats totalement bidons, y compris négatifs.
l'autre possibilité est que vous compiliez ceci sous forme de code 32 bits, mais avec beaucoup plus de répétitions, et que vous obteniez un intervalle négatif occasionnel sur la migration CPU sur un système qui n'a pas d'invariant-TSC (synced TSCs à travers tous les noyaux). Soit un multi-socket système, ou un vieux multi-noyau. CPU TSC opération d'extraction en particulier dans le multicœur multi-processeur de l'environnement .
si vous compiliez pour x86-64, vos résultats négatifs sont entièrement expliqués par votre contrainte de sortie incorrecte "=A" pour asm . Voir Obtenir le nombre de cycles CPU? pour corriger les façons d'utiliser rdtsc qui sont portables pour tous les compilateurs et 32 vs Mode 64 bits. Ou utilisez les sorties "=a" et "=d" et ignorez simplement la moitié haute de la sortie, pour de courts intervalles qui ne déborderont pas de 32 bits.)
(je suis surpris que vous n'ayez pas mentionné qu'ils étaient aussi énormes et très variables, ainsi que débordant tot pour donner une moyenne négative même si aucune mesure individuelle n'était négative. Je vois des moyennes comme -63421899 , ou 69374170 , ou 115365476 .)
le compiler avec gcc -O3 -m32 le fait fonctionner comme prévu, des moyennes d'impression de 24 à 26 (Si exécuté dans une boucle de sorte que le CPU reste à la vitesse maximale, autrement comme 125 cycles de référence pour les 24 cycles de l'horloge centrale entre dos-à-dos rdtsc sur Skylake). https://agner.org/optimize/ pour l'instruction des tables.
Asm détails de ce qui s'est passé avec le "=A" contrainte
rdtsc (insn ref manual entry) always produit les deux moitiés 32-bit hi:lo de son résultat 64-bit en edx:eax , même en mode 64-bit où nous sommes vraiment plutôt l'avoir dans un seul registre 64-bit.
vous vous attendiez à ce que la contrainte de sortie "=A" sélectionne edx:eax pour uint64_t t . Mais ce n'est pas ce qui arrive. pour une variable qui correspond à one , le compilateur sélectionne soit RAX ou RDX et suppose que l'autre est non modifié , tout comme une contrainte "=r" sélectionne un registre et suppose que le reste est non modifié. Ou une contrainte "=Q" choisit une de a,b,C, ou D. (Voir x86 contraintes ).
dans x86-64, Vous ne voulez normalement que "=A" pour un opérande unsigned __int128 , comme un multiple résultat ou entrée div . C'est un peu un piratage car utiliser %0 dans le modèle asm ne fait que s'étendre au registre bas, et il n'y a pas d'avertissement lorsque "=A" ne fait pas utiliser à la fois a et d registres.
pour voir exactement comment cela cause un problème, j'ai ajouté un commentaire dans le modèle asm:
__asm__ volatile ("rdtsc # compiler picked %0" : "=A"(t)); . Donc nous pouvons voir ce que le compilateur attend, basé sur ce que nous lui avons dit avec opérande.
la boucle résultante (dans la syntaxe Intel) ressemble à ceci, à partir de la compilation d'une version nettoyée de votre code sur L'Explorateur Godbolt compilateur pour 64-bit gcc et 32-bit clang:
# the main loop from gcc -O3 targeting x86-64, my comments added
.L6:
rdtsc # compiler picked rax # c1 = rax
rdtsc # compiler picked rdx # c2 = rdx, not realizing that rdtsc clobbers rax(c1)
# compiler thinks RAX=c1, RDX=c2
# actual situation: RAX=low half of c2, RDX=high half of c2
sub edx, eax # tsccost = edx-eax
js .L3 # jump if the sign-bit is set in tsccost
... rest of loop back to .L6
quand le compilateur calcule c2-c1 , c'est en fait calculant hi-lo du 2ème rdtsc , parce que nous avons menti au compilateur sur ce que la déclaration de l'asm le fait. Le 2ème rdtsc tabassé c1
nous lui avons dit qu'il avait un choix de Registre pour obtenir la sortie, Donc il a choisi un registre la première fois, et l'autre la deuxième fois, de sorte qu'il n'aurait pas besoin d'instructions mov .
le TSC compte les cycles de référence depuis le dernier redémarrage. Mais le code ne dépend pas de hi<lo , il dépend juste du signe de hi-lo . Depuis lo enroulement toutes les secondes ou deux (2^32 Hz est proche de 4,3 GHz), l'exécution du programme à tout moment a environ 50% de chance de voir un résultat négatif.
cela ne dépend pas de la valeur courante de hi ; il y a peut-être une partie dans 2^32 biais dans une direction ou l'autre parce que hi change par un quand lo enroule autour.
depuis hi-lo est un entier presque uniformément distribué 32 bits, le débordement de la moyenne est très commun. Votre code est correct si la moyenne est normalement petite. (Mais voyez d'autres réponses pour savoir pourquoi vous ne voulez pas la moyenne; vous voulez la médiane ou quelque chose pour exclure les valeurs aberrantes.)
le point principal de ma question n'était pas la précision du résultat, mais le fait que je reçois des valeurs négatives de temps en temps (le premier appel à rdstc donne une valeur plus grande que le second appel). En faisant plus de recherche (et en lisant d'autres questions sur ce site web), j'ai découvert qu'une façon de faire fonctionner les choses en utilisant rdtsc est de mettre une commande cpuid juste avant. Cette commande sérialise le code. C'est ainsi que je fais les choses maintenant:
static inline uint64_t get_cycles()
{
uint64_t t;
volatile int dont_remove __attribute__((unused));
unsigned tmp;
__asm volatile ("cpuid" : "=a"(tmp), "=b"(tmp), "=c"(tmp), "=d"(tmp)
: "a" (0));
dont_remove = tmp;
__asm volatile ("rdtsc" : "=A"(t));
return t;
}
je suis on obtient toujours une différence négative entre le deuxième appel et le premier appel de la fonction get_cycles. Pourquoi? Je ne suis pas sûr à 100% de la syntaxe du code en ligne de l'assemblage cpuid, c'est ce que j'ai trouvé en regardant sur internet.
face aux interruptions thermiques et de ralenti, le mouvement de la souris et le trafic réseau, quoi qu'il fasse avec le GPU, et tous les autres frais généraux qu'un système multicore moderne peut absorber sans personne beaucoup de soins, je pense que votre seule voie raisonnable pour cela est d'accumuler quelques milliers d'échantillons individuels et juste jeter les valeurs aberrantes avant de prendre la médiane ou la moyenne (pas un statisticien, mais je m'aventure il ne fera pas beaucoup de différence ici).
pensez que tout ce que vous faites pour éliminer le bruit d'un système en cours d'exécution va fausser les résultats bien pire que juste accepter qu'il n'y a aucun moyen que vous ne serez jamais en mesure de prédire de façon fiable combien de temps il faudra n'importe quoi à compléter ces jours.
rdtsc peut être utilisé pour obtenir un temps écoulé fiable et très précis. Si vous utilisez linux, vous pouvez voir si votre processeur supporte un TSC à vitesse constante en regardant dans /proc/cpuinfo pour voir si constant_tsc est défini.
assurez-vous de rester sur le même noyau. Chaque noyau a son propre tsc qui a sa propre valeur. Pour utiliser rdtsc assurez-vous que vous soit taskset , ou SetThreadAffinityMask (windows) ou pthread_setaffinity_np pour s'assurer que votre processus reste sur le même noyau.
ensuite vous divisez ceci par votre taux d'horloge principal qui sur linux peut être trouvé dans / proc / cpuinfo ou vous pouvez le faire à l'exécution par
rdtsc
clock_gettime
dormir 1 seconde
clock_gettime
rdtsc
alors voir combien de tiques par seconde, et alors vous pouvez diviser n'importe quelle différence en tiques pour savoir combien de temps s'est écoulé.
si le thread qui exécute votre code se déplace entre les noyaux, alors il est possible que la valeur rdtsc retournée soit inférieure à la valeur lue sur un autre noyau. Le noyau ne met pas tous le compteur à 0 exactement au même moment où le paquet se met en marche. Assurez-vous donc que vous définissez l'affinité du thread à un noyau spécifique lorsque vous exécutez votre test.
j'ai testé votre code sur ma machine et je me suis dit que pendant le RDTSC, seul uint32_t est raisonnable.
je fais ce qui suit dans mon code pour le corriger:
if(before_t<after_t){ diff_t=before_t + 4294967296 -after_t;}