Besoin d'un gestionnaire de mémoire multi-threading
je vais devoir créer un projet multi-threading bientôt j'ai vu des expériences ( delphitools.info/2011/10/13/memory-manager-investigations ) montrant que le gestionnaire de mémoire Delphi par défaut a des problèmes avec le multi-threading.
donc, j'ai trouvé ce SynScaleMM. Quelqu'un peut donner quelques commentaires sur elle ou sur un gestionnaire de mémoire similaire?
Merci
6 réponses
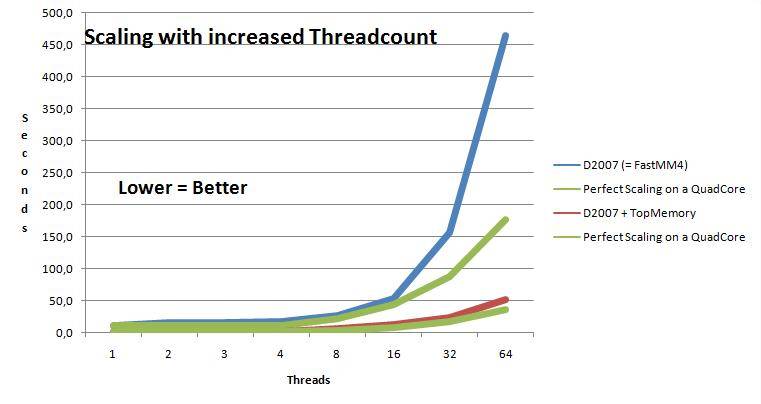
Notre SynScaleMM est encore au stade expérimental.
EDIT: jetez un oeil à la plus stable ScaleMM2 et le tout nouveau SAPMM . Mais mes remarques ci-dessous valent toujours la peine d'être suivies: moins vous faites d'allocation, mieux vous évoluez!
mais cela a fonctionné comme prévu dans un environnement de serveur multi-threadé. L'échelle est bien meilleure que FastMM4, pour quelques tests critiques.
mais le Gestionnaire de mémoire n'est peut-être pas le plus grand goulot d'étranglement dans les applications multi-threads. FastMM4 pourrait bien fonctionner, si vous ne le stressez pas.
voici quelques conseils (pas dogmatiques, juste de l'expérience et de la connaissance de faible niveau Delphi RTL) si vous voulez écrire L'application multi-threaded rapide dans Delphi:
- toujours utiliser
constpour des paramètres de chaîne ou de réseau dynamique comme dansMyFunc(const aString: String)pour éviter d'attribuer une chaîne temporaire par appel; - éviter d'utiliser la concaténation de chaîne (
s := s+'Blabla'+IntToStr(i)), mais s'appuyer sur une écriture tamponnée telle queTStringBuilderdisponible dans les dernières versions de Delphi; -
TStringBuildern'est pas parfait non plus: par exemple, il va créer beaucoup de chaînes temporaires pour ajouter des données numériques, et utilisera la fonction terriblement lenteSysUtils.IntToStr()quand vous ajoutez une certaine valeurinteger- j'ai dû réécrire un grand nombre de fonctions de bas niveau pour éviter la plupart des attributions de chaînes dans notre classeTTextWritercomme défini dans les SynCommons .pas ; - N'abusez pas des sections critiques, qu'elles soient aussi petites que possible, mais utilisez certains modificateurs atomiques si vous avez besoin d'un accès simultané - voir par exemple
InterlockedIncrement / InterlockedExchangeAdd; -
InterlockedExchange(de SysUtils.pas) est une bonne façon de mettre à jour un tampon ou un objet partagé. Vous créez une version mise à jour de un peu de contenu dans votre thread, puis vous échangez un pointeur partagé vers les données (par exemple une instanceTObject) dans une opération CPU de bas niveau. Il notifiera le changement aux autres threads, avec une très bonne mise à l'échelle multi-thread. Vous devrez vous occuper de l'intégrité des données, mais cela fonctionne très bien dans la pratique. - ne partagez pas de données entre les threads, mais plutôt faites votre propre copie privée ou utilisez des tampons en lecture seule (le modèle RCU est mieux pour la mise à l'échelle);
- N'utilisez pas l'accès indexé aux caractères de chaîne, mais faites appel à certaines fonctions optimisées comme
PosEx()par exemple; - Ne pas mélanger
AnsiString/UnicodeStringtype de variables/fonctions, et de vérifier l'asm généré code via Alt-F2 pour piste cachée indésirables de conversion (par exemple,call UStrFromPCharLen); - plutôt utiliser
varparamètres dans unprocedureau lieu defunctionretourner une chaîne (une fonction retourner unstringajoutera unUStrAsg/LStrAsgappel qui a une serrure qui va rincer tous les cœurs CPU); - si vous pouvez, pour l'analyse de vos données ou de vos textes, utiliser des pointeurs et des tampons statiques alloués à la pile au lieu de chaînes temporaires ou de tableaux dynamiques;""
- ne créez pas un
TMemoryStreamà chaque fois que vous en avez besoin, mais faites confiance à une instance privée de votre classe, déjà dimensionnée dans une mémoire suffisante, dans laquelle vous écrirez des données en utilisantPositionpour récupérer la fin des données et ne pas changer sonSize(qui sera le bloc mémoire attribué par le MM); - limitez le nombre d'instances de classe que vous créez: essayez de réutiliser la même instance, et si vous le pouvez, utilisez des pointeurs
record/objectsur des tampons mémoire déjà alloués, en cartographiant les données sans les copier dans une mémoire temporaire; - toujours utiliser le développement basé sur les tests, avec multi-threads test dédié, en essayant d'atteindre le pire cas limite (augmenter le nombre de threads, le contenu des données, ajouter des données incohérentes, s'arrêter au hasard, essayer de mettre l'accent sur l'accès au réseau ou au disque, le benchmark avec le timing sur les données réelles...);
- ne vous fiez jamais à votre instinct, mais utilisez un timing précis sur les données réelles et le processus.
j'ai essayé de suivre ces règles dans notre cadre Open Source, et si vous jetez un oeil à notre code, vous découvrirez beaucoup de code échantillon du monde réel.
si votre application peut accommoder le code sous licence GPL, alors je recommande Hoard . Vous devrez lui écrire votre propre papier, mais c'est très facile. Dans mes tests, je n'ai rien trouvé qui corresponde à ce code. Si votre code n'est pas compatible avec la GPL, vous pouvez obtenir une licence commerciale de Hoard, moyennant des frais importants.
même si vous ne pouvez pas utiliser Hoard dans une version externe de votre code, vous pouvez comparer ses performances avec celles de FastMM à déterminez si oui ou non votre application a des problèmes avec l'évolutivité de l'allocation de tas.
j'ai également trouvé que les allocateurs de mémoire dans les versions de msvcrt.dll distribué avec Windows Vista et échelle plus tard assez bien sous la prétention de fil, certainement beaucoup mieux que FastMM ne. J'ai utiliser ces routines, par la Delphi MM.
unit msvcrtMM;
interface
implementation
type
size_t = Cardinal;
const
msvcrtDLL = 'msvcrt.dll';
function malloc(Size: size_t): Pointer; cdecl; external msvcrtDLL;
function realloc(P: Pointer; Size: size_t): Pointer; cdecl; external msvcrtDLL;
procedure free(P: Pointer); cdecl; external msvcrtDLL;
function GetMem(Size: Integer): Pointer;
begin
Result := malloc(size);
end;
function FreeMem(P: Pointer): Integer;
begin
free(P);
Result := 0;
end;
function ReallocMem(P: Pointer; Size: Integer): Pointer;
begin
Result := realloc(P, Size);
end;
function AllocMem(Size: Cardinal): Pointer;
begin
Result := GetMem(Size);
if Assigned(Result) then begin
FillChar(Result^, Size, 0);
end;
end;
function RegisterUnregisterExpectedMemoryLeak(P: Pointer): Boolean;
begin
Result := False;
end;
const
MemoryManager: TMemoryManagerEx = (
GetMem: GetMem;
FreeMem: FreeMem;
ReallocMem: ReallocMem;
AllocMem: AllocMem;
RegisterExpectedMemoryLeak: RegisterUnregisterExpectedMemoryLeak;
UnregisterExpectedMemoryLeak: RegisterUnregisterExpectedMemoryLeak
);
initialization
SetMemoryManager(MemoryManager);
end.
il est intéressant de souligner que votre application doit marteler l'allocateur tas assez fort avant la tension du fil dans FastMM devient un obstacle à la performance. Typiquement dans mon expérience cela arrive quand votre application fait beaucoup de traitement de chaîne.
mon principal conseil pour quiconque souffre d'une dispute sur l'allocation du tas est de retravailler le code pour éviter de frapper le tas. Non seulement vous évitez la dispute, mais vous évitez également la dépense de l'allocation de tas – un classique deux!
c'est verrouillage qui fait la différence!
il y a deux questions dont il faut tenir compte:
- Utilisation du préfixe
LOCKpar le Delphi lui-même (système.dcu); - comment FastMM4 gère-t-il la tension du fil et ce qu'il fait après qu'il n'a pas réussi à acquérir une serrure.
Utilisation du préfixe LOCK par le Delphi lui-même
Borland Delphi 5, publié en 1999, est celui qui a introduit le préfixe lock dans les opérations de string. Comme vous le savez, lorsque vous assignez une chaîne à une autre, elle ne copie pas la chaîne entière, mais augmente simplement le compteur de référence à l'intérieur de la chaîne. Si vous modifiez la chaîne, il s'agit de supprimer les références, de diminuer le compteur de référence et d'attribuer un espace séparé pour la chaîne modifiée.
à Delphi 4 et plus tôt, les opérations d'augmenter et diminuer le compteur de référence étaient normales opérations de mémoire. Les programmeurs qui ont utilisé Delphi savaient et, et s'ils utilisaient des chaînes à travers les fils, c'est-à-dire passer une chaîne d'un fil à l'autre, ont utilisé leur propre mécanisme de verrouillage seulement pour les chaînes pertinentes . Les programmeurs ont également utilisé une copie de chaîne de caractères en lecture seule qui ne modifiait en aucune façon la chaîne source et ne nécessitait pas de verrouillage, par exemple:
function AssignStringThreadSafe(const Src: string): string;
var
L: Integer;
begin
L := Length(Src);
if L <= 0 then Result := '' else
begin
SetString(Result, nil, L);
Move(PChar(Src)^, PChar(Result)^, L*SizeOf(Src[1]));
end;
end;
mais en Delphi 5, Borland ont ajouté le préfixe LOCK aux opérations de chaîne et ils sont devenus très lents, par rapport à Delphi 4, même pour les applications mono-filetées.
pour surmonter cette lenteur, les programmeurs ont commencé à utiliser un système" simple fileté".PAS de patch fichiers avec lock commenté.
s'il vous Plaît voir https://synopse.info/forum/viewtopic.php?id=57&p=1 pour plus d'informations.
FastMM4 Thread La Contention de 1519230920"
vous pouvez modifier le code source FastMM4 pour un meilleur mécanisme de verrouillage, ou utiliser N'importe quelle fourche FastMM4 existante, par exemple https://github.com/maximmasiutin/FastMM4
FastMM4 n'est pas le plus rapide pour l'opération multicore, surtout quand le nombre de threads est plus que le nombre de sockets physiques est parce qu'il, par défaut, sur la prétention de thread (c.-à-d. quand un thread ne peut pas acquérir l'accès aux données, verrouillé par un autre thread) appelle la fonction API Windows Sleep(0), puis, si le verrou n'est toujours pas disponible, entre dans une boucle en appelant Sleep (1) après chaque vérification du verrou.
chaque appel au Sommeil (0) fait l'expérience du coût coûteux d'un commutateur de contexte, qui peut être 10000+ cycles; il souffre également le coût des transitions de l'anneau 3 à l'anneau 0, qui peut être 1000+ cycles. Comme sur le Sommeil(1) – outre les coûts associés au Sommeil(0) – il retarde également l'exécution d'au moins 1 milliseconde, céder le contrôle à d'autres threads, et, s'il n'y a pas de threads qui attendent d'être exécutés par un noyau CPU physique, met le noyau en veille, réduisant efficacement l'utilisation CPU et la consommation d'énergie.
C'est pourquoi, sur les wotk multithred avec FastMM, L'utilisation de CPU n'a jamais atteint 100% - en raison du sommeil(1) émis par FastMM4. Cette façon d'acquérir des serrures n'est pas optimale. Une meilleure façon aurait été un verrou tournant d'environ 5000 pause instructions, et, si la serrure était encore occupée, appel à L'appel de L'API SwitchToThread (). Si pause n'est pas disponible (sur les processeurs très anciens sans support SSE2) ou que L'appel API SwitchToThread() n'est pas disponible (sur les versions très anciennes de Windows, antérieures à Windows 2000), la meilleure solution serait d'utiliser EnterCriticalSection/LeaveCriticalSection, qui n'ont pas de latence associée à Sleep(1), et qui cède également très efficacement le contrôle du noyau CPU à d'autres threads.
la fourche que j'ai mentionnée utilise un nouveau approche à l'attente d'une serrure, recommandée par Intel dans son Optimization Manual pour les développeurs - un spinloop de pause + SwitchToThread(), et, si l'un d'eux n'est pas disponible: CriticalSections au lieu de Sleep(). Avec ces options, Sleep () ne sera jamais utilisé mais EnterCriticalSection/LeaveCriticalSection sera utilisé à la place. Les essais ont montré que l'approche de L'utilisation des sections critiques au lieu du sommeil (qui a été utilisé par défaut avant dans FastMM4) fournit un gain significatif dans les situations où le nombre de threads travaillant avec le gestionnaire de mémoire est le même ou plus élevé que le nombre de noyaux physiques. Le gain est encore plus évident sur les ordinateurs avec plusieurs CPU physiques et accès à la mémoire non uniforme (NUMA). J'ai mis en place des options de compilation pour supprimer L'approche FastMM4 originale de L'utilisation de Sleep (InitialSleepTime) puis Sleep (AdditionalSleepTime) (ou Sleep(0) et Sleep (1)) et les remplacer par La section entrecritique / LeaveCriticalSection permet d'économiser les précieux cycles CPU gaspillés par le sommeil(0) et d'améliorer la vitesse (réduire la latence) qui a été affectée à chaque fois d'au moins 1 milliseconde par le sommeil(1), parce que les Sections critiques sont beaucoup plus favorables au CPU et ont certainement une latence plus faible que le sommeil(1).
lorsque ces options sont activées, FastMM4-AVX vérifie: (1) si le CPU Supporte SSE2 et donc l'instruction "pause", et (2) si le système d'exploitation a le SwitchToThread() appelle L'API, et, si les deux conditions sont remplies, utilise la boucle de spin "pause" pour 5000 itérations, puis SwitchToThread() à la place des sections critiques; si un CPU n'a pas l'instruction "pause" ou que Windows n'a pas la fonction API SwitchToThread (), il utilisera EnterCriticalSection/LeaveCriticalSection.
vous pouvez voir les résultats des tests, y compris fait sur un ordinateur avec plusieurs CPU physiques (sockets) dans cette fourchette.
voir aussi le Spin-wait Loops de longue durée sur la technologie Hyper-Threading a permis aux processeurs Intel article. Voici ce Qu'Intel écrit sur cette question - et il s'applique très bien à FastMM4:
la boucle spin-wait de longue durée dans ce modèle de filetage pose rarement un problème de performance sur les systèmes multiprocesseurs conventionnels. Mais il peut introduire une pénalité sévère sur un système avec la technologie Hyper-Threading parce que les ressources du processeur peut être consommé par le fil maître pendant qu'il attend les fils ouvriers. Sleep (0) dans la boucle peut suspendre l'exécution du thread maître, mais seulement lorsque tous les processeurs disponibles ont été pris par les threads worker pendant toute la période d'attente. Cette condition exige que tous les fils d'ouvrier accomplissent leur travail en même temps. En d'autres termes, les charges de travail attribuées aux fils de worker doivent être équilibrées. Si l'un des fils de travail termine son travail plus tôt que les autres et libère le processeur, le thread maître peut toujours fonctionner sur un processeur.
sur un système multiprocesseur conventionnel, cela ne cause pas de problèmes de performance car aucun autre thread n'utilise le processeur. Mais sur un système avec la Technologie Hyper-Threading, le processeur maître thread s'exécute est une logique qui partage les ressources du processeur avec l'un des autres threads.
la nature de nombreuses applications rend difficile de garantir que les charges de travail attribuées aux fils des travailleurs sont équilibrées. Une application 3D multithreaded, par exemple, peut assigner les tâches pour la transformation d'un bloc de sommets de coordonnées du monde à des coordonnées de visualisation à une équipe de threads de travail. La quantité de travail pour un thread worker est déterminée non seulement par le nombre de Sommets mais aussi par le statut clipped du sommet, qui n'est pas prévisible lorsque le thread master divise la charge de travail pour les threads working.
A l'argument non-zéro dans la fonction Sleep force le thread à sleep N millisecondes, indépendamment de la disponibilité du processeur. Il peut effectivement bloquer le thread d'attente de la consommation des ressources processeur si la période d'attente est réglée correctement. Mais si la période d'attente est imprévisible de la charge de travail à la charge de travail, alors une grande valeur de N peut faire dormir le fil d'attente trop longtemps, et une valeur plus petite de N peut le faire se réveiller trop rapidement.
donc le la solution préférée pour éviter de gaspiller les ressources du processeur dans une boucle de spin-wait de longue durée est de remplacer la boucle par une API de blocage de thread du système d'exploitation, comme L'API de threading de Microsoft Windows*., WaitForMultipleObjects. Cet appel provoque le système d'exploitation pour bloquer le thread d'attente de la consommation des ressources du processeur.
se réfère à utilisant des Spin-Loops sur processeur Intel Pentium 4 et processeur Intel Xeon note d'application.
vous pouvez également trouver une très bonne mise en œuvre spin-loop ici à stackoverflow .
il charge aussi des charges normales juste pour vérifier avant d'émettre un lock - ed magasin, juste pour ne pas inonder le CPU avec des opérations verrouillées dans une boucle, qui verrouillerait le bus.
FastMM4 en soi est très bonne. Seulement d'améliorer le verrouillage et vous obtiendrez un excellent multi-thread gestionnaire de mémoire.
veuillez également noter que chaque type de petit bloc est verrouillé séparément dans FastMM4.
vous pouvez mettre du rembourrage entre les zones de contrôle des petits blocs, pour que chaque zone ait sa propre ligne de cache, non partagée avec d'autres tailles de blocs, et pour vous assurer qu'elle commence à une limite de taille de ligne de cache. Vous pouvez utiliser CPUID pour déterminer la taille de la ligne de cache CPU.
donc, avec verrouillage correctement mis en œuvre pour répondre à vos besoins (c.-à-d. Si vous besoin NUMA ou non,si d'utiliser lock - libération, etc., vous pouvez obtenir les résultats que les routines d'allocation de mémoire seraient plusieurs fois plus rapides et ne souffriraient pas si sévèrement de la discorde de thread.
FastMM traite avec multi-threading très bien. Il est le gestionnaire de mémoire par défaut pour Delphi 2006 et plus.
si vous utilisez une ancienne version de Delphi (Delphi 5 et plus), vous pouvez toujours utiliser FastMM. Il est disponible sur SourceForge .
vous pouvez utiliser TopMM: http://www.topsoftwaresite.nl/
vous pouvez aussi essayer ScaleMM2 ( SynScaleMM est basé sur ScaleMM1) mais je dois corriger un bug concernant la mémoire interthread, donc pas encore prêt pour la production :-( http://code.google.com/p/scalemm/
Deplhi 6 le gestionnaire de mémoire est dépassé et complètement mauvais. Nous utilisions RecyclerMM à la fois sur un serveur de production à forte charge et sur une application de bureau multi-threadée, et nous n'avions aucun problème avec cela: c'est rapide, fiable et ne provoque pas de fragmentation excessive. (Fragmentation a été Delphi des actions du gestionnaire de mémoire pire problème).
le seul inconvénient de RecyclerMM est qu'il n'est pas compatible avec MemCheck sorti de la boîte. Cependant, une petite modification de la source était suffisant pour la rendre compatible.