nom du noeud Vs nom secondaire du noeud
Hadoop est cohérent et tolérant la partition, c'est-à-dire qu'il relève de la catégorie CP de la théorie CAP.
Hadoop n'est pas disponible car tous les noeuds dépendent du noeud du nom. Si le noeud de nom tombe le cluster descend.
mais considérant le fait que le cluster HDFS a un noeud de nom secondaire pourquoi ne pouvons-nous pas appeler hadoop comme disponible. Si le noeud de nom est en bas, le noeud de nom secondaire peut être utilisé pour les Écritures.
Quelle est la différence majeure entre le noeud de nom et le noeud de nom secondaire qui rend hadoop indisponible.
Merci d'avance.
7 réponses
la méthode de stockage des données stocke les informations du système de fichiers HDFS dans un fichier nommé fsimage. Les mises à jour du système de fichiers (Ajouter/Supprimer des blocs) ne mettent pas à jour le fichier fsimage, mais sont plutôt enregistrées dans un fichier, de sorte que l'e/s est ajouté rapidement uniquement en streaming par opposition à des Écritures de fichier aléatoires. Lors du redémarrage, le namenode lit le fsimage puis applique toutes les modifications du fichier log pour mettre à jour l'état du système de fichiers en mémoire. Ce processus prend du temps.
le la tâche secondarynamenode ne doit pas être secondaire par rapport au noeud du nom, mais seulement pour lire périodiquement le journal des modifications du système de fichiers et les appliquer dans le fichier fsimage, le mettant ainsi à jour. Cela permet au namenode de démarrer plus rapidement la prochaine fois.
malheureusement, le service secondarynamenode n'est pas un namenode secondaire de réserve, malgré son nom. Plus précisément, il n'offre pas D'AP pour le namenode. C'est bien illustré ici .
Voir Compréhension NameNode au Démarrage des Activités dans HDFS .
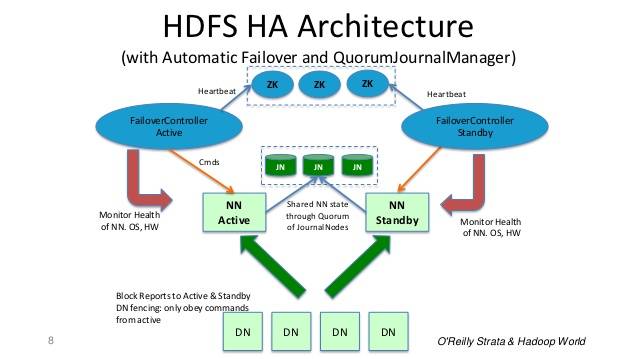
notez que les distributions plus récentes (Hadoop actuel 2.6) introduit namenode haute disponibilité en utilisant NFS (stockage partagé) et/ou namenode haute disponibilité en utilisant Quorum Journal Manager .
les choses ont changé au fil des ans surtout avec Hadoop 2.x . Maintenant, Namenode est très disponible avec la fonctionnalité fail over.
Secondary Namenode est facultatif maintenant & Veille Namenode a été utilisé pour les processus de basculement.
Veille NameNode va rester à jour avec toutes les modifications du système de fichiers Active NameNode fait .
SF Haute disponibilité est possible avec deux options : NFS et le Collège Gestionnaire de Journal mais Quorum Gestionnaire de Journal est l'option privilégiée.
Avoir un coup d'oeil à Apache documentation
de la diapositive 8 de: http://www.slideshare.net/cloudera/hdfs-futures-world2012-widescreen
quand n'importe quelle modification d'espace de noms est effectuée par le noeud actif, il enregistre de façon durable un enregistrement de la modification à une majorité de ces JNs. Le noeud de veille lit ces modifications depuis le JNs et s'applique à son propre espace de nom.
dans le cas d'un basculement, la veille s'assurera qu'elle a lu toutes les éditions des JounalNodes avant de se promouvoir à l'état actif. Cela garantit que l'état namespace est entièrement synchronisé avant qu'un le basculement se produit.
Avoir un coup d'oeil à propos de l'échec du processus connexes SE question :
Comment fonctionne le processus de basculement Hadoop Namenode?
concernant vos requêtes sur la théorie de la PAC pour Hadoop:
- Il peut y avoir une forte cohérence
- HDFS est presque très disponible sauf si vous avez rencontré de la malchance (Si les trois répliques d'un bloc sont en panne, vous n'obtiendrez pas de données)
- supporte la Partition de données
est un noeud primaire dans lequel toutes les métadonnées sont stockées dans des fichiers fsimage et editlog périodiquement. Mais, lorsque le noeud de nom vers le bas du noeud secondaire sera en ligne, mais ce noeud ont seulement l'accès de lecture aux fichiers fsimage et editlog et n'ont pas l'accès d'écriture à eux . Toutes les opérations du noeud secondaire seront stockées dans le dossier temp . lorsque le noeud de nom sera de nouveau en ligne, ce dossier temporaire sera copié sur le noeud de nom et le namenode mettra à jour les fichiers fsimage et editlog.
même en haute disponibilité HDFS, où il y a deux NameNodes au lieu d'un NameNode et D'un SecondaryNameNode, il n'y a pas de disponibilité au sens strict du CAP. Il ne s'applique qu'au composant NameNode, et même là, si une partition réseau sépare le client des deux NameNodes, alors le cluster est effectivement indisponible.
si je l'explique de manière simple, supposons que le noeud du nom soit un homme (actif / vivant) et que le noeud du nom secondaire soit un ATM (stockage / stockage de données)
Donc toutes les fonctions effectuées par NN ou men seulement mais si elle descend / échoue alors SNN sera inutile il ne fonctionne pas, mais plus tard il peut être utilisé pour récupérer vos données ou les journaux
lorsque NameNode démarre, il charge FSImage et replay Edit Logs pour créer la dernière mise à jour de l'espace de noms. Ce processus peut prendre beaucoup de temps si la taille du fichier Edit Log est grande et donc augmenter le temps de démarrage. Le travail du noeud secondaire de nom est de vérifier périodiquement le journal d'édition et rejouer pour créer fsimage mis à jour et stocker dans le stockage persistant. Quand le noeud de nom commence, il n'a pas besoin de rejouer éditer le journal pour créer fsimage mis à jour, il utilise FSImage créé par le noeud de nom secondaire.
le namenode est un noeud maître qui contient des métadonnées en termes de fsimage et contient également le journal d'édition. Le journal d'édition contient des informations de bloc récemment ajoutées ou supprimées dans l'espace de noms du namenode. Le fichier fsimage contient les métadonnées de l'ensemble du système hadoop dans un stockage permanent. Chaque fois que nous avons besoin d'effectuer des changements permanents dans fsimage, nous devons redémarrer namenode afin que les informations d'édition de journal puissent être écrites à namenode, mais il faut beaucoup de temps pour le faire.
un code secondaire est utilisé pour mettre fsimage à jour. Le noeud de nom secondaire accédera au journal d'édition et apportera des changements dans fsimage de façon permanente afin que la prochaine fois namenode puisse démarrer plus rapidement.
essentiellement le namenode secondaire est un assistant pour le namenode et exécute la fonctionnalité de ménage pour le namenode.