Requête MySQL pour obtenir "intersection" de nombreuses requêtes avec des limites
supposons que j'ai une seule table mySQL (utilisateurs) avec les champs suivants:
userid
gender
region
age
ethnicity
income
je veux pouvoir retourner le nombre total d'enregistrements basé sur le nombre qu'un utilisateur entre. En outre, ils fourniront également des critères supplémentaires.
dans l'exemple le plus simple, ils peuvent demander 1000 enregistrements, où 600 enregistrements devraient avoir le genre = "masculin" et 400 enregistrements où le genre = "féminin". C'est assez simple à faire.
maintenant, allez un peu plus loin. Supposons qu'ils veulent maintenant spécifier la région:
GENDER
Male: 600 records
Female: 400 records
REGION
North: 100 records
South: 200 records
East: 300 records
West: 400 records
encore une fois, seulement 1000 enregistrements devraient être retournés, mais à la fin, il doit y avoir 600 mâles, 400 femelles, 100 Nordistes, 200 Sudistes, 300 Esterners et 400 Ouesterners.
je sais que ce n'est pas une syntaxe valide, mais en utilisant le code pseudo-mySQL, j'espère qu'il illustre ce que j'essaie de faire:
(SELECT * FROM users WHERE gender = 'Male' LIMIT 600
UNION
SELECT * FROM users WHERE gender = 'Female' LIMIT 400)
INTERSECT
(SELECT * FROM users WHERE region = 'North' LIMIT 100
UNION
SELECT * FROM users WHERE region = 'South' LIMIT 200
UNION
SELECT * FROM users WHERE region = 'East' LIMIT 300
UNION
SELECT * FROM users WHERE region = 'West' LIMIT 400)
notez que je ne cherche pas une requête unique. Le nombre total de dossiers et le nombre d'enregistrements dans chaque critère sera constamment modifié en fonction des commentaires de l'utilisateur. Donc, je vais essayer de trouver une solution générique qui peut être ré-utilisé, pas codé en dur solution.
pour rendre les choses plus compliquées, ajoutez maintenant plus de critères. Il pourrait aussi y avoir l'âge, l'origine ethnique et le revenu, chacun avec son propre nombre de dossiers établi pour chaque groupe, code additionnel ajouté ci-dessus:
INTERSECT
(SELECT * FROM users WHERE age >= 18 and age <= 24 LIMIT 300
UNION
SELECT * FROM users WHERE age >= 25 and age <= 36 LIMIT 200
UNION
SELECT * FROM users WHERE age >= 37 and age <= 54 LIMIT 200
UNION
SELECT * FROM users WHERE age >= 55 LIMIT 300)
INTERSECT
etc.
je ne sais pas si c'est possible d'écrire dans une même requête, ou si cela nécessite déclarations et itérations multiples.
10 réponses
Aplatissez Vos Critères
vous pouvez aplatir vos critères multidimensionnels en un seul critère de niveau
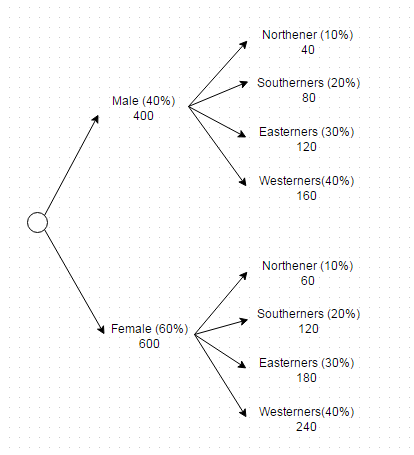
maintenant ce critère peut être atteint dans une requête comme suit
(SELECT * FROM users WHERE gender = 'Male' AND region = 'North' LIMIT 40) UNION ALL
(SELECT * FROM users WHERE gender = 'Male' AND region = 'South' LIMIT 80) UNION ALL
(SELECT * FROM users WHERE gender = 'Male' AND region = 'East' LIMIT 120) UNION ALL
(SELECT * FROM users WHERE gender = 'Male' AND region = 'West' LIMIT 160) UNION ALL
(SELECT * FROM users WHERE gender = 'Female' AND region = 'North' LIMIT 60) UNION ALL
(SELECT * FROM users WHERE gender = 'Female' AND region = 'South' LIMIT 120) UNION ALL
(SELECT * FROM users WHERE gender = 'Female' AND region = 'East' LIMIT 180) UNION ALL
(SELECT * FROM users WHERE gender = 'Female' AND region = 'West' LIMIT 240)
Problème
- Il n'est pas toujours le bon résultat. Par exemple, s'il y a moins de 40 utilisateurs qui sont des hommes et du Nord, alors la requête retournera moins de 1000 enregistrements.
Ajustez Vos Critères
disons qu'il y a moins de 40 utilisateurs de sexe masculin et du Nord. Ensuite, vous devez ajuster la quantité d'autres critères pour couvrir la quantité manquante de "mâle"et " Nord". Je pense qu'il n'est pas possible de le faire avec du SQL nu. C'est un pseudo-code que j'ai en tête. Dans un souci de simplification, je pense que nous ne nous adresserons qu'aux hommes, aux femmes, au nord et au sud.
conditions.add({ gender: 'Male', region: 'North', limit: 40 })
conditions.add({ gender: 'Male', region: 'South', limit: 80 })
conditions.add({ gender: 'Female', region: 'North', limit: 60 })
conditions.add({ gender: 'Female', region: 'South', limit: 120 })
foreach(conditions as condition) {
temp = getResultFromDatabaseByCondition(condition)
conditions.remove(condition)
// there is not enough result for this condition,
// increase other condition quantity
if (temp.length < condition.limit) {
adjust(...);
}
}
disons qu'il n'y a que 30 hommes de northener. Nous devons donc ajuster + 10 mâle, et + 10 northener.
To Adjust
---------------------------------------------------
Male +10
North +10
Remain Conditions
----------------------------------------------------
{ gender: 'Male', region: 'South', limit: 80 }
{ gender: 'Female', region: 'North', limit: 60 }
{ gender: 'Female', region: 'South', limit: 120 }
"mâle" + " Sud "Est la première condition qui correspond à la condition d'ajustement "mâle". Augmentez-le de +10, et retirez-le de la liste "reste condition". Depuis, nous augmentons le Sud, nous devons réduire à la condition d'autres. Ajoutez donc la condition "Sud" dans la liste "ajuster"
To Adjust
---------------------------------------------------
South -10
North +10
Remain Conditions
----------------------------------------------------
{ gender: 'Female', region: 'North', limit: 60 }
{ gender: 'Female', region: 'South', limit: 120 }
Final Conditions
----------------------------------------------------
{ gender: 'Male', region: 'South', limit: 90 }
trouver l'état qui correspond le "Sud" et répéter le même processus.
To Adjust
---------------------------------------------------
Female +10
North +10
Remain Conditions
----------------------------------------------------
{ gender: 'Female', region: 'North', limit: 60 }
Final Conditions
----------------------------------------------------
{ gender: 'Female', region: 'South', limit: 110 }
{ gender: 'Male', region: 'South', limit: 90 }
Et enfin
{ gender: 'Female', region: 'North', limit: 70 }
{ gender: 'Female', region: 'South', limit: 110 }
{ gender: 'Male', region: 'South', limit: 90 }
Je n'ai pas encore trouvé l'application exacte de l'ajustement. Il est plus difficile que j'ai prévu. Je mettrai à jour une fois que j'aurai trouvé comment l'implémenter.
le problème que vous décrivez est un problème de modélisation multidimensionnelle. En particulier, vous essayez d'obtenir un échantillon stratifié à plusieurs dimensions en même temps. La clé pour cela est d'aller jusqu'au plus petit niveau de granularité et de construire l'échantillon à partir de là.
je suppose en outre que vous voulez que l'échantillon soit représentatif à tous les niveaux. C'est-à-dire que vous ne voulez pas que tous les utilisateurs du "Nord" soient des femmes. Ou tous les "mâles" à partir de "l'Ouest", même si cela répond aux critères finaux.
commencez par penser en termes de nombre total de documents, de dimensions et de répartitions le long de chaque dimension. Par exemple, pour le premier échantillon, il pense que:
- 1000 enregistrements
- 2 dimensions: sexe, région
- répartition par sexe: 60%, 40%
- répartition par région: 10%, 20%, 30%, 40%
ensuite, vous voulez attribuer ces nombres à chaque combinaison sexe/région. Le les numéros sont les suivants:
- Nord, Mâle: 60
- Nord, Femelle: 40
- Sud, Mâle: 120
- Sud, Femelle: 80
- Est, Mâle: 180
- Est, Femelle: 120
- Ouest, Mâle: 240
- Ouest, Femelle: 160
vous verrez que ceux-ci s'additionnent le long des dimensions.
Le calcul des nombres dans chaque cellule est assez facile. Il est le produit de la pourcentages multipliés par le total. Donc, "est, femme" est de 30%*40% * 1000 . . . Voila! La valeur est de 120.
Voici la solution:
- prendre l'entrée le long de chaque dimension comme pourcentages du total. Et être sûr à 100% le long de chaque dimension.
- créer un tableau des pourcentages prévus pour chacune des cellules. C'est le produit des pourcentages le long de chaque dimension.
- Plusieurs attendus pourcentages de la population totale.
- la requête finale est décrite ci-dessous.
supposons que vous avez une table cells avec le comte et les données d'origine (