MyISAM contre InnoDB [fermé]
je travaille sur un projet qui implique beaucoup de bases de données écrit, je dirais ( 70% inserts et 30% lit ). Ce ratio inclurait également les mises à jour que je considère comme une lecture et une écriture. Les lectures peuvent être sales (par exemple, je n'ai pas besoin d'informations exactes à 100% au moment de la lecture).
La tâche en question consistera à effectuer plus d'un million de transactions de base de données par heure.
j'ai lu un tas de trucs sur le web sur les différences entre MyISAM et InnoDB, et MyISAM semble être le choix évident pour moi pour la base de données particulière/tables que je vais utiliser pour cette tâche. De ce que je semble lire, InnoDB est bon si les transactions sont nécessaires puisque le verrouillage de niveau de rangée est supporté.
est-ce que quelqu'un a de l'expérience avec ce type de charge (ou plus)? MyISAM est-elle la voie à suivre?
27 réponses
j'ai brièvement discuté cette question dans un tableau afin que vous puissiez conclure si aller avec InnoDB ou MyISAM .
voici un petit aperçu du moteur de stockage db que vous devez utiliser dans quelle situation:
MyISAM InnoDB
----------------------------------------------------------------
Required full-text search Yes 5.6.4
----------------------------------------------------------------
Require transactions Yes
----------------------------------------------------------------
Frequent select queries Yes
----------------------------------------------------------------
Frequent insert, update, delete Yes
----------------------------------------------------------------
Row locking (multi processing on single table) Yes
----------------------------------------------------------------
Relational base design Yes
pour résumer:
Frequent reading, almost no writing => MyISAM Full-text search in MySQL <= 5.5 => MyISAM
dans toutes les autres circonstances, InnoDB est habituellement la meilleure façon de aller.
Je ne suis pas un expert en bases de données, et je ne parle pas par expérience. Toutefois:
les tables MyISAM utilisation de la table de verrouillage au niveau de la . Sur la base de vos estimations de trafic, vous avez près de 200 écrits par seconde. Avec MyISAM, seul l'un d'entre eux pouvait être en cours à tout moment . Vous devez vous assurer que votre matériel peut suivre ces transactions pour éviter d'être dépassé, c'est-à-dire qu'une seule requête ne peut prendre plus de 5ms.
qui me suggère que vous auriez besoin d'un moteur de stockage qui soutient le verrouillage de niveau de rangée, i.e., InnoDB.
d'un autre côté, il devrait être assez trivial d'écrire quelques scripts simples pour simuler la charge avec chaque moteur de stockage, puis comparer les résultats.
les gens parlent souvent de performance, de lecture ou d'écriture, de clés étrangères, etc. mais il ya un autre must-have caractéristique pour un moteur de stockage à mon avis: mises à jour atomiques.
essayez ceci:
- faites une mise à jour de votre table MyISAM qui prend 5 secondes.
- pendant que la mise à jour est en cours, dites 2,5 secondes, appuyez sur Ctrl-C pour l'interrompre.
- observer la effets sur la table. Combien de lignes ont été mises à jour? Combien n'ont pas été mis à jour? La table est-elle même lisible, ou a-t-elle été corrompue lorsque vous avez cliqué sur Ctrl-C?
- essayez la même expérience avec UPDATE contre une table InnoDB, interrompant la requête en cours.
- observer la table InnoDB. zero les lignes ont été mises à jour. InnoDB a assuré que vous avez des mises à jour atomiques, et si la mise à jour complète ne peut pas être engagée, il renverse l'ensemble changement. Aussi, le tableau n'est pas corrompu. Cela fonctionne même si vous utilisez
killall -9 mysqldpour simuler un accident.
la Performance est évidemment souhaitable, mais ne pas perdre de données devrait l'emporter.
j'ai travaillé sur un système à haut volume en utilisant MySQL et j'ai essayé à la fois MyISAM et InnoDB.
j'ai constaté que le verrouillage au niveau de la table dans MyISAM a causé de graves problèmes de performance pour notre charge de travail qui ressemble à la vôtre. Malheureusement, J'ai également constaté que la performance sous InnoDB était aussi pire que je l'espérais.
à la fin, j'ai résolu la question de la prétention en fragmentant les données de sorte que les inserts sont allés dans une table "chaude" et sélectionne Je n'ai jamais questionné la table chaude.
cela permettait également des suppressions (les données étaient sensibles au temps et nous n'avons conservé que la valeur de X jours) pour se produire sur des tables" périmées " qui encore une fois n'ont pas été touchées par les requêtes select. InnoDB semble avoir de mauvaises performances sur les suppressions de masse donc si vous planifiez sur les données de purge vous pourriez vouloir structurer de telle manière que les anciennes données est dans une table périmée qui peut simplement être abandonné au lieu d'exécuter des suppressions sur elle.
bien sûr, je n'avez aucune idée de ce que votre application est, mais espérons que cela vous donne un aperçu de certains des problèmes avec MyISAM et InnoDB.
un peu en retard au jeu...Mais voici un post très complet que j'ai écrit il y a quelques mois , détaillant les principales différences entre MYISAM et InnoDB. Prenez une tasse de thé (et peut-être un biscuit) et d'en profiter.
la principale différence entre MyISAM et InnoDB réside dans l'intégrité référentielle et les transactions. Il y a aussi d'autres différences telles que le verrouillage, Les retours en arrière et les recherches en texte intégral.
Intégrité Référentielle
intégrité référentielle assure que les relations entre les tables restent cohérentes. Plus précisément, cela signifie que lorsqu'une table (p. ex. une liste) a une clé étrangère (p. ex. L'ID du produit) pointant vers une table différente (p. ex. les produits), lorsque des mises à jour ou des suppressions se produisent à la table pointée-vers, ces changements sont transmis en cascade à la table de liaison. Dans notre exemple, si un produit est renommé, les clés étrangères de la table de liaison seront également mises à jour; si un produit est supprimé dans le tableau "produits", les inscriptions qui pointent vers la rubrique supprimée sont également supprimées. De plus, toute nouvelle inscription doit comporter cette clé étrangère indiquant une entrée valide et existante.
InnoDB est un SGBDR relationnel et possède donc une intégrité référentielle, contrairement à MyISAM.
Les Transactions Et L'Atomicité
les données d'une table sont gérées à l'aide d'instructions du langage de Manipulation des données (DML), telles que SELECT, INSERT, UPDATE et les SUPPRIMER. Une transaction regroupe deux ou plusieurs déclarations DML en une seule unité de travail, donc soit l'unité entière est appliquée, soit rien de tout cela ne l'est.
MyISAM do not support transactions while InnoDB does.
si une opération est interrompue en utilisant une table MyISAM, l'opération est interrompue immédiatement, et les lignes (ou même les données à l'intérieur de chaque ligne) qui sont affectées restent affectées, même si l'opération n'est pas terminée.
si une opération est interrompue en utilisant une table InnoDB, parce qu'elle utilise des transactions, qui ont atomicité, toute transaction qui n'est pas allé à l'achèvement ne prendra pas effet, puisqu'aucune commit n'est faite.
table-verrouillage vs ligne-verrouillage
quand une requête s'exécute contre une table MyISAM, la table entière dans laquelle elle est interrogée sera verrouillée. Cela signifie que les requêtes suivantes ne seront exécutées qu'après celui en cours est terminé. Si vous sont en train de lire une grande table, et/ou il y a des opérations fréquentes de lecture et d'écriture, cela peut signifier un énorme arriéré de requêtes.
Lorsqu'une requête s'exécute contre une table InnoDB, seules les lignes qui sont impliquées sont verrouillées, le reste de la table reste disponible pour les opérations CRUD. Cela signifie que les requêtes peuvent être exécutées simultanément sur la même table, à condition qu'elles n'utilisent pas la même ligne.
cette caractéristique de L'InnoDB est connue sous le nom de simultanéité. Aussi grand que la concurrence is, il y a un inconvénient majeur qui s'applique à une sélection de tables, en ce sens qu'il y a un overhead dans la commutation entre les threads du noyau, et vous devriez définir une limite sur les threads du noyau pour empêcher le serveur de s'arrêter.
Des Opérations Et Des Restaurations
lorsque vous exécutez une opération dans MyISAM, les changements sont définis; dans InnoDB, ces changements peuvent être annulés. Les commandes les plus courantes utilisées pour contrôler les transactions sont COMMIT, ROLLBACK et SAVEPOINT. 1. COMMIT - vous pouvez écrire plusieurs opérations DML, mais les modifications ne seront sauvegardées que lorsqu'une propagation est effectuée 2. Retour en arrière - vous pouvez rejeter toute opération qui n'a pas encore été engagée 3. SAVEPOINT-définit un point dans la liste des opérations pour lesquelles une opération de roll back peut être
fiabilité
MyISAM n'offre aucune intégrité des données - les pannes matérielles, les arrêts malsains et les opérations annulées peuvent entraîner la corruption des données. Ce nécessiterait la réparation complète ou la reconstruction des index et des tableaux.
InnoDB, d'autre part, utilise un journal transactionnel, un tampon à double écriture et vérification automatique et de validation pour prévenir la corruption. Avant toute modification, InnoDB enregistre les données avant les transactions dans un fichier de tablespace système appelé ibdata1. S'il y a un crash, InnoDB autorecover à travers le replay de ces logs.
indexation texte intégral
InnoDB ne supporte pas l'indexation en texte intégral jusqu'à ce que MySQL version 5.6.4. Au moment de la rédaction de ce post, la version MySQL de nombreux fournisseurs d'hébergement partagé est toujours inférieure à 5.6.4, ce qui signifie que L'indexation en texte intégral n'est pas prise en charge pour les tables InnoDB.
cependant, ce n'est pas une raison valable pour utiliser MyISAM. Il est préférable de passer à un fournisseur d'hébergement qui prend en charge les versions les plus récentes de MySQL. Non pas qu'une table MyISAM qui utilise l'indexation plein-texte ne puisse pas être convertie en InnoDB table.
Conclusion
en conclusion, InnoDB devrait être votre moteur de stockage par défaut de choix. Choisissez MyISAM ou d'autres types de données lorsqu'ils répondent à un besoin spécifique.
pour un chargement avec plus d'Écritures et de lectures, vous bénéficierez de InnoDB. Parce que InnoDB fournit le verrouillage de ligne plutôt que le verrouillage de table, vos SELECT s peuvent être concurrents, non seulement entre eux, mais aussi avec de nombreux INSERT s. Cependant, sauf si vous avez l'intention d'utiliser des transactions SQL, définissez InnoDB commit flush à 2 ( innodb_flush_log_at_trx_commit ). Cela vous donne beaucoup de performance brute que vous perdriez autrement en déplaçant des tables de MyISAM à InnoDB.
également, envisager d'ajouter la réplication. Cela vous donne une certaine échelle de lecture et puisque vous avez déclaré que vos lectures ne doivent pas être à jour, vous pouvez laisser la réplication prendre du retard. Assurez-vous juste qu'il peut rattraper sous n'importe quoi mais le trafic le plus lourd ou il sera toujours derrière et ne sera jamais rattraper. Si vous allez par là, Cependant, je fortement vous recommande d'isoler la lecture des esclaves et la gestion du décalage de réplication à votre gestionnaire de base. Il est tellement plus simple si le code d'application ne sait pas à ce sujet.
enfin, être conscient des différentes charges de tableau. Vous n'aurez pas le même rapport lecture/écriture sur tous les tableaux. Certaines petites tables avec près de 100% lit pourrait se permettre de rester MyISAM. De même, si vous avez des tables qui sont près de 100% write, vous pouvez bénéficier de INSERT DELAYED , mais qui est seulement supporté dans MyISAM (la clause DELAYED est ignorée pour une table InnoDB).
mais benchmark pour être sûr.
pour ajouter au large choix de réponses ici couvrant les différences mécaniques entre les deux moteurs, je présente une étude empirique de comparaison de vitesse.
en termes de vitesse pure, il n'est pas toujours le cas que MyISAM est plus rapide que InnoDB, mais dans mon expérience, il a tendance à être plus rapide pour les environnements de travail de lecture PURE par un facteur d'environ 2,0-2,5 fois. Il est clair que ce n'est pas approprié pour tous les environnements - comme D'autres l'ont écrit, MyISAM manque de tels des choses comme des transactions et les clés étrangères.
j'ai fait un peu de benchmarking ci - dessous-j'ai utilisé python pour la boucle et la bibliothèque timeit pour des comparaisons de temps. Pour l'intérêt, j'ai également inclus le moteur de mémoire, ce qui donne la meilleure performance dans l'ensemble bien qu'il ne soit adapté pour les petites tables (vous rencontrez continuellement The table 'tbl' is full quand vous dépassez la limite de mémoire MySQL). Les quatre types de select que je regarde sont:
- vanille sélectionne
- compte
- selects conditionnels
- sous-sélections indexées et non indexées
tout d'abord, j'ai créé trois tables en utilisant le SQL suivant
CREATE TABLE
data_interrogation.test_table_myisam
(
index_col BIGINT NOT NULL AUTO_INCREMENT,
value1 DOUBLE,
value2 DOUBLE,
value3 DOUBLE,
value4 DOUBLE,
PRIMARY KEY (index_col)
)
ENGINE=MyISAM DEFAULT CHARSET=utf8
avec "MyISAM" remplacé par "InnoDB" et "mémoire" dans les deuxième et troisième tableaux.
1) vanille choisit
Requête: SELECT * FROM tbl WHERE index_col = xx
Résultat: dessiner
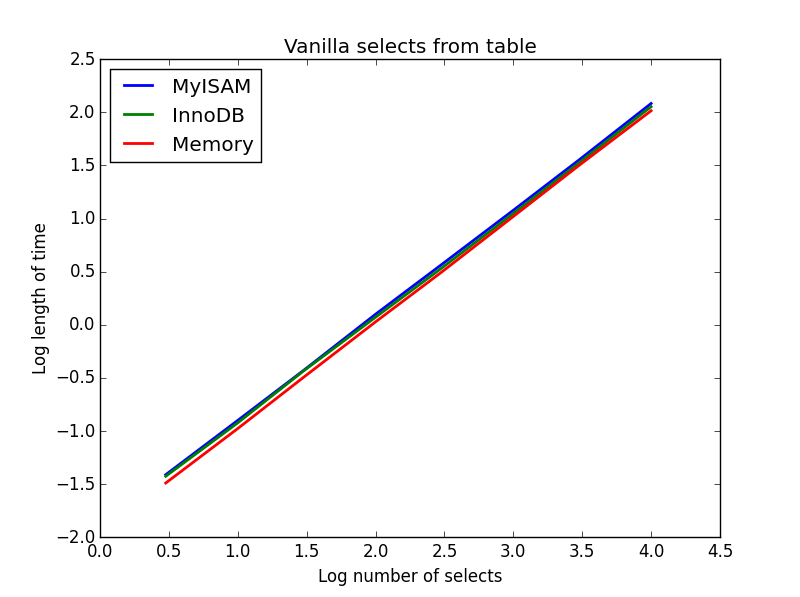
la vitesse de ces derniers est globalement la même, et comme prévu est linéaire dans le nombre de colonnes à sélectionner. InnoDB semble légèrement plus rapide que MyISAM, mais c'est vraiment marginal.
Code:
import timeit
import MySQLdb
import MySQLdb.cursors
import random
from random import randint
db = MySQLdb.connect(host="...", user="...", passwd="...", db="...", cursorclass=MySQLdb.cursors.DictCursor)
cur = db.cursor()
lengthOfTable = 100000
# Fill up the tables with random data
for x in xrange(lengthOfTable):
rand1 = random.random()
rand2 = random.random()
rand3 = random.random()
rand4 = random.random()
insertString = "INSERT INTO test_table_innodb (value1,value2,value3,value4) VALUES (" + str(rand1) + "," + str(rand2) + "," + str(rand3) + "," + str(rand4) + ")"
insertString2 = "INSERT INTO test_table_myisam (value1,value2,value3,value4) VALUES (" + str(rand1) + "," + str(rand2) + "," + str(rand3) + "," + str(rand4) + ")"
insertString3 = "INSERT INTO test_table_memory (value1,value2,value3,value4) VALUES (" + str(rand1) + "," + str(rand2) + "," + str(rand3) + "," + str(rand4) + ")"
cur.execute(insertString)
cur.execute(insertString2)
cur.execute(insertString3)
db.commit()
# Define a function to pull a certain number of records from these tables
def selectRandomRecords(testTable,numberOfRecords):
for x in xrange(numberOfRecords):
rand1 = randint(0,lengthOfTable)
selectString = "SELECT * FROM " + testTable + " WHERE index_col = " + str(rand1)
cur.execute(selectString)
setupString = "from __main__ import selectRandomRecords"
# Test time taken using timeit
myisam_times = []
innodb_times = []
memory_times = []
for theLength in [3,10,30,100,300,1000,3000,10000]:
innodb_times.append( timeit.timeit('selectRandomRecords("test_table_innodb",' + str(theLength) + ')', number=100, setup=setupString) )
myisam_times.append( timeit.timeit('selectRandomRecords("test_table_myisam",' + str(theLength) + ')', number=100, setup=setupString) )
memory_times.append( timeit.timeit('selectRandomRecords("test_table_memory",' + str(theLength) + ')', number=100, setup=setupString) )
2) Nombre 1519330920"
Requête: SELECT count(*) FROM tbl
résultat: MyISAM gagne
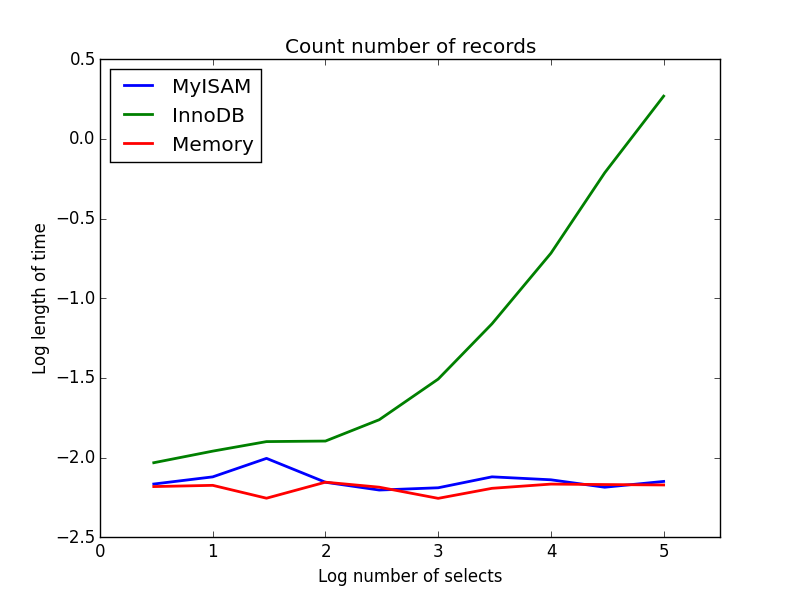
celui - ci démontre une grande différence entre MyISAM et InnoDB-MyISAM (et la mémoire) garde la trace du nombre d'enregistrements dans la table, donc cette transaction est rapide et O(1). Le temps nécessaire à InnoDB pour compter augmente de façon super-linéaire avec la taille de la table dans le gamme j'ai étudié. Je soupçonne que beaucoup d'accélérations des requêtes MyISAM qui sont observées dans la pratique sont dues à des effets similaires.
Code:
myisam_times = []
innodb_times = []
memory_times = []
# Define a function to count the records
def countRecords(testTable):
selectString = "SELECT count(*) FROM " + testTable
cur.execute(selectString)
setupString = "from __main__ import countRecords"
# Truncate the tables and re-fill with a set amount of data
for theLength in [3,10,30,100,300,1000,3000,10000,30000,100000]:
truncateString = "TRUNCATE test_table_innodb"
truncateString2 = "TRUNCATE test_table_myisam"
truncateString3 = "TRUNCATE test_table_memory"
cur.execute(truncateString)
cur.execute(truncateString2)
cur.execute(truncateString3)
for x in xrange(theLength):
rand1 = random.random()
rand2 = random.random()
rand3 = random.random()
rand4 = random.random()
insertString = "INSERT INTO test_table_innodb (value1,value2,value3,value4) VALUES (" + str(rand1) + "," + str(rand2) + "," + str(rand3) + "," + str(rand4) + ")"
insertString2 = "INSERT INTO test_table_myisam (value1,value2,value3,value4) VALUES (" + str(rand1) + "," + str(rand2) + "," + str(rand3) + "," + str(rand4) + ")"
insertString3 = "INSERT INTO test_table_memory (value1,value2,value3,value4) VALUES (" + str(rand1) + "," + str(rand2) + "," + str(rand3) + "," + str(rand4) + ")"
cur.execute(insertString)
cur.execute(insertString2)
cur.execute(insertString3)
db.commit()
# Count and time the query
innodb_times.append( timeit.timeit('countRecords("test_table_innodb")', number=100, setup=setupString) )
myisam_times.append( timeit.timeit('countRecords("test_table_myisam")', number=100, setup=setupString) )
memory_times.append( timeit.timeit('countRecords("test_table_memory")', number=100, setup=setupString) )
3) sélections conditionnelles
Requête: SELECT * FROM tbl WHERE value1<0.5 AND value2<0.5 AND value3<0.5 AND value4<0.5
résultat: MyISAM gagne
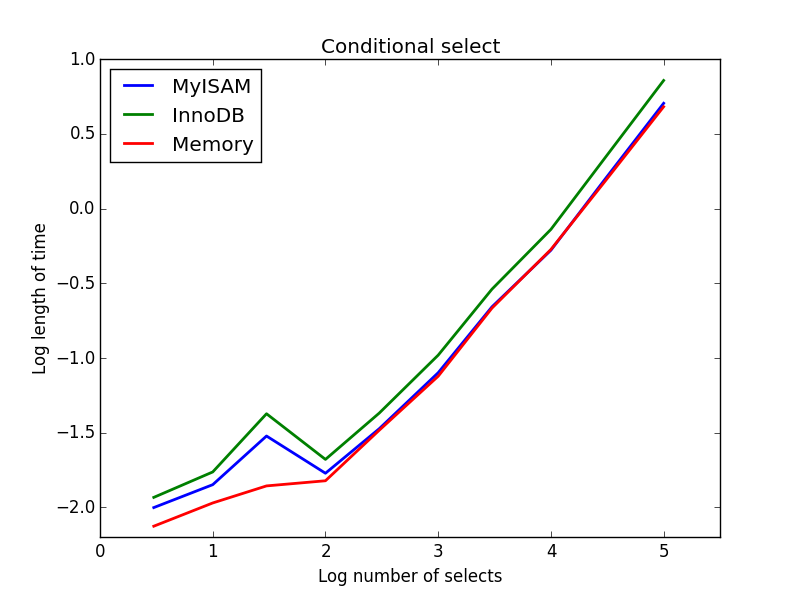
ici, MyISAM et mémoire effectuer à peu près la même chose, et battre InnoDB d'environ 50% pour les grandes tables. C'est le genre de requête pour laquelle les avantages de MyISAM semblent être maximisés.
Code:
myisam_times = []
innodb_times = []
memory_times = []
# Define a function to perform conditional selects
def conditionalSelect(testTable):
selectString = "SELECT * FROM " + testTable + " WHERE value1 < 0.5 AND value2 < 0.5 AND value3 < 0.5 AND value4 < 0.5"
cur.execute(selectString)
setupString = "from __main__ import conditionalSelect"
# Truncate the tables and re-fill with a set amount of data
for theLength in [3,10,30,100,300,1000,3000,10000,30000,100000]:
truncateString = "TRUNCATE test_table_innodb"
truncateString2 = "TRUNCATE test_table_myisam"
truncateString3 = "TRUNCATE test_table_memory"
cur.execute(truncateString)
cur.execute(truncateString2)
cur.execute(truncateString3)
for x in xrange(theLength):
rand1 = random.random()
rand2 = random.random()
rand3 = random.random()
rand4 = random.random()
insertString = "INSERT INTO test_table_innodb (value1,value2,value3,value4) VALUES (" + str(rand1) + "," + str(rand2) + "," + str(rand3) + "," + str(rand4) + ")"
insertString2 = "INSERT INTO test_table_myisam (value1,value2,value3,value4) VALUES (" + str(rand1) + "," + str(rand2) + "," + str(rand3) + "," + str(rand4) + ")"
insertString3 = "INSERT INTO test_table_memory (value1,value2,value3,value4) VALUES (" + str(rand1) + "," + str(rand2) + "," + str(rand3) + "," + str(rand4) + ")"
cur.execute(insertString)
cur.execute(insertString2)
cur.execute(insertString3)
db.commit()
# Count and time the query
innodb_times.append( timeit.timeit('conditionalSelect("test_table_innodb")', number=100, setup=setupString) )
myisam_times.append( timeit.timeit('conditionalSelect("test_table_myisam")', number=100, setup=setupString) )
memory_times.append( timeit.timeit('conditionalSelect("test_table_memory")', number=100, setup=setupString) )
4) sous-sélections
résultat: InnoDB gagne
pour cette requête, j'ai créé un ensemble supplémentaire de tables pour la sous-sélection. Chacun est simplement deux colonnes de BIGINTs, une avec un index primaire et une sans aucun index. En raison de la Grande Taille de la table, je n'ai pas testé le moteur mémoire. La commande de création de table SQL était
CREATE TABLE
subselect_myisam
(
index_col bigint NOT NULL,
non_index_col bigint,
PRIMARY KEY (index_col)
)
ENGINE=MyISAM DEFAULT CHARSET=utf8;
où, encore une fois, "MyISAM" remplace "InnoDB" dans le deuxième tableau.
dans cette requête, je laisse la taille de la table de sélection à 1000000 et à la place varier la taille des colonnes sous-sélectionnées.
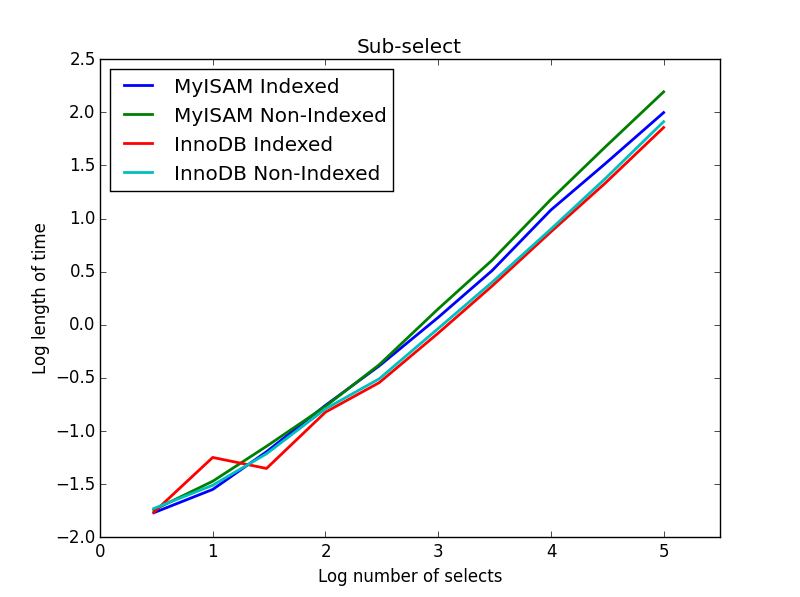
ici L'InnoDB gagne facilement. Après nous arrivons à une table de taille raisonnable les deux moteurs échelle linéairement avec la taille de la sous-sélection. L'index accélère la commande MyISAM, mais il est intéressant de noter qu'il a peu d'effet sur la vitesse InnoDB. sous-sélection.png
Code:
myisam_times = []
innodb_times = []
myisam_times_2 = []
innodb_times_2 = []
def subSelectRecordsIndexed(testTable,testSubSelect):
selectString = "SELECT * FROM " + testTable + " WHERE index_col in ( SELECT index_col FROM " + testSubSelect + " )"
cur.execute(selectString)
setupString = "from __main__ import subSelectRecordsIndexed"
def subSelectRecordsNotIndexed(testTable,testSubSelect):
selectString = "SELECT * FROM " + testTable + " WHERE index_col in ( SELECT non_index_col FROM " + testSubSelect + " )"
cur.execute(selectString)
setupString2 = "from __main__ import subSelectRecordsNotIndexed"
# Truncate the old tables, and re-fill with 1000000 records
truncateString = "TRUNCATE test_table_innodb"
truncateString2 = "TRUNCATE test_table_myisam"
cur.execute(truncateString)
cur.execute(truncateString2)
lengthOfTable = 1000000
# Fill up the tables with random data
for x in xrange(lengthOfTable):
rand1 = random.random()
rand2 = random.random()
rand3 = random.random()
rand4 = random.random()
insertString = "INSERT INTO test_table_innodb (value1,value2,value3,value4) VALUES (" + str(rand1) + "," + str(rand2) + "," + str(rand3) + "," + str(rand4) + ")"
insertString2 = "INSERT INTO test_table_myisam (value1,value2,value3,value4) VALUES (" + str(rand1) + "," + str(rand2) + "," + str(rand3) + "," + str(rand4) + ")"
cur.execute(insertString)
cur.execute(insertString2)
for theLength in [3,10,30,100,300,1000,3000,10000,30000,100000]:
truncateString = "TRUNCATE subselect_innodb"
truncateString2 = "TRUNCATE subselect_myisam"
cur.execute(truncateString)
cur.execute(truncateString2)
# For each length, empty the table and re-fill it with random data
rand_sample = sorted(random.sample(xrange(lengthOfTable), theLength))
rand_sample_2 = random.sample(xrange(lengthOfTable), theLength)
for (the_value_1,the_value_2) in zip(rand_sample,rand_sample_2):
insertString = "INSERT INTO subselect_innodb (index_col,non_index_col) VALUES (" + str(the_value_1) + "," + str(the_value_2) + ")"
insertString2 = "INSERT INTO subselect_myisam (index_col,non_index_col) VALUES (" + str(the_value_1) + "," + str(the_value_2) + ")"
cur.execute(insertString)
cur.execute(insertString2)
db.commit()
# Finally, time the queries
innodb_times.append( timeit.timeit('subSelectRecordsIndexed("test_table_innodb","subselect_innodb")', number=100, setup=setupString) )
myisam_times.append( timeit.timeit('subSelectRecordsIndexed("test_table_myisam","subselect_myisam")', number=100, setup=setupString) )
innodb_times_2.append( timeit.timeit('subSelectRecordsNotIndexed("test_table_innodb","subselect_innodb")', number=100, setup=setupString2) )
myisam_times_2.append( timeit.timeit('subSelectRecordsNotIndexed("test_table_myisam","subselect_myisam")', number=100, setup=setupString2) )
je pense que le message à retenir de tout cela est que si vous êtes vraiment préoccupé par la vitesse, vous devez comparez les requêtes que vous faites plutôt que de faire des hypothèses sur quel moteur sera plus approprié.
légèrement hors sujet, mais pour des raisons de documentation et d'exhaustivité, j'aimerais ajouter ce qui suit.
en général en utilisant InnoDB résultera en une application beaucoup moins complexe, probablement aussi plus libre de bug. Parce que vous pouvez mettre toute l'intégrité référentielle (clé étrangère-contraintes) dans le datamodel, vous n'avez pas besoin d'autant de code d'application que vous en aurez besoin avec MyISAM.
chaque fois que vous insérez, supprimez ou remplacez un enregistrez, vous devrez vérifier et maintenir les relations. Par exemple: si vous supprimez un parent, tous les enfants doivent être supprimés aussi. Par exemple, même dans un système de blogging simple, si vous supprimez un blogposting enregistrement, vous devrez supprimer les enregistrements de commentaires, les likes, etc. Dans InnoDB cela est fait automatiquement par le moteur de base de données (si vous avez spécifié les contraintes dans le modèle) et ne nécessite pas de code d'application. Dans MyISAM cela devra être codé dans l'application, ce qui est très difficile dans les serveurs web. Les serveurs Web sont par nature très concurrents / parallèles et comme ces actions doivent être atomiques et que MyISAM ne supporte aucune transaction réelle, L'utilisation de MyISAM pour les serveurs web est risquée / sujette à erreur.
également dans la plupart des cas généraux, InnoDB fonctionnera beaucoup mieux, pour une multitude de raisons, l'une D'entre elles étant capable d'utiliser le verrouillage de niveau d'enregistrement par opposition au verrouillage de niveau de table. Non seulement dans une situation où l'écriture est plus fréquente que la lecture, également dans des situations avec des jointures complexes sur de grands ensembles de données. Nous avons remarqué une augmentation de la performance de 3 fois rien qu'en utilisant des tables InnoDB sur des tables MyISAM pour de très grandes jointures (ce qui prend plusieurs minutes).
je dirais qu'en général InnoDB (en utilisant un datamodel 3NF complet avec intégrité référentielle) devrait être le choix par défaut lors de L'utilisation de MySQL. MyISAM ne doit être utilisé que dans des cas très spécifiques. Il sera très probablement moins performante, résultant en une application plus grande et plus buggy.
Après avoir dit cela. Datamodelling est un art rarement trouvé parmi les webdesigners / - programmeurs. Ne le prenez pas mal, mais ça explique L'utilisation de MyISAM.
InnoDB offre:
ACID transactions
row-level locking
foreign key constraints
automatic crash recovery
table compression (read/write)
spatial data types (no spatial indexes)
dans InnoDB toutes les données dans une rangée sauf pour le texte et BLOB peut occuper 8.000 bytes au plus. Aucune indexation en texte intégral N'est disponible pour InnoDB. Dans InnoDB le nombre (*) s (lorsque, GROUP BY, ou JOIN n'est pas utilisé) s'exécute plus lentement que dans MyISAM parce que le nombre de lignes n'est pas stocké en interne. InnoDB stocke les données et les index dans un seul fichier. InnoDB utilise un pool de buffer pour mettre en cache les données et les index.
MyISAM offre:
fast COUNT(*)s (when WHERE, GROUP BY, or JOIN is not used)
full text indexing
smaller disk footprint
very high table compression (read only)
spatial data types and indexes (R-tree)
MyISAM possède un verrouillage de niveau de table, mais pas de verrouillage de niveau de rangée. Pas de transactions. Pas de récupération automatique de crash, mais il offre la fonctionnalité de table de réparation. Aucune contrainte étrangère. Les tables MyISAM sont généralement plus compactes en taille sur le disque que les tables InnoDB. Les tables MyISAM pourraient être encore plus réduites en taille en comprimant avec myisampack si nécessaire, mais devenir en lecture seule. MyISAM stocke les index dans un fichier et les données dans un autre. MyISAM utilise la clé tampons pour les index de mise en cache et laisse la gestion de mise en cache des données au système d'exploitation.
dans l'ensemble, je recommande InnoDB pour la plupart des utilisations et MyISAM pour des utilisations spécialisées seulement. InnoDB est maintenant le moteur par défaut dans les nouvelles versions MySQL.
si vous utilisez MyISAM, vous ne ferez pas n'importe quelles transactions par heure, à moins que vous considériez chaque déclaration DML comme une transaction (qui dans tous les cas, ne sera pas durable ou atomique dans le cas d'un crash).
donc je pense que vous devez utiliser InnoDB.
300 transactions par seconde ressemble beaucoup. Si vous avez absolument besoin de ces transactions pour être durable à travers une panne de courant, assurez-vous que votre sous-système D'E/S peut manipulez ce nombre écrit par seconde facilement. Vous aurez besoin au moins d'un contrôleur RAID avec cache sur batterie.
si vous pouvez prendre un petit coup de durabilité, vous pouvez utiliser InnoDB avec innodb_flush_log_at_trx_commit réglé à 0 ou 2 (voir docs pour plus de détails), vous pouvez améliorer les performances.
il existe un certain nombre de patches qui peuvent augmenter la concurrence de Google et d'autres - ceux-ci peuvent être d'intérêt si vous ne pouvez toujours pas obtenir assez de performances sans eux.
la Question et la plupart des réponses sont périmées .
Oui, C'est un conte de vieilles femmes que MyISAM est plus rapide que InnoDB. notez la date de la Question: 2008; il est maintenant près d'une décennie plus tard. InnoDB a fait des progrès significatifs en matière de performance depuis lors.
le graphique dramatique était pour le seul cas où MyISAM gagne: COUNT(*) sans a WHERE clause. Mais est-ce vraiment ce que vous passez votre temps à faire?
Si vous l'exécutez simultanéité test, InnoDB est très probablement la victoire, même contre MEMORY .
si vous faites n'importe quel écrit tout en comparant SELECTs , MyISAM et MEMORY sont susceptibles de perdre en raison du verrouillage de niveau de table.
en fait, Oracle est si sûr que InnoDB est mieux qu'ils ont tout sauf enlevé MyISAM à partir de 8.0.
la Question a été écrite au début du 5.1. Depuis lors, ces principales versions ont été marquées "disponibilité générale":
- 2010: 5.5 (.8 Déc.)
- 2013: 5.6 (.10 en février)
- 2015: 5.7 (.9 dans Oct.)
- 2018: 8.0 (.11 en Avr.)
conclusion: N'utilisez pas MyISAM
MYISAM:
-
MYISAM prend en charge au niveau de la Table de Verrouillage
-
MyISAM conçu pour le besoin de vitesse
- MyISAM ne supporte pas les clés étrangères donc nous appelons MySQL avec MYISAM is DBMS
- MyISAM stocke ses tables, données et Index dans l'espace disque en utilisant trois fichiers distincts. (tablename.FRM, tablename.MYD, tablename.MYI)
- MYISAM ne supporte pas la transaction. Vous ne pouvez pas vous engager et reculer avec MYISAM. Une fois que vous émettez une commande c'est fait.
INNODB:
- InnoDB prend en charge le Verrouillage de Ligne
- InnoDB conçu pour une performance maximale lors du traitement de volumes élevés de données
- InnoDB supporte les clés étrangères donc nous appelons MySQL avec InnoDB is RDBMS
- InnoDB stocke ses tables et Index dans un espace de table
- InnoDB supporte la transaction. Vous pouvez vous engager et reculer avec InnoDB
prendre note que mon éducation formelle et de l'expérience avec Oracle, alors que mon travail avec MySQL a été entièrement personnelle et sur mon propre temps, donc si je dis des choses qui sont vraies pour l'Oracle, mais ne sont pas vraies pour MySQL, je m'en excuse. Alors que les deux systèmes partagent beaucoup, la théorie relationnelle/algèbre est la même, et les bases de données relationnelles sont encore des bases de données relationnelles, Il ya encore beaucoup de différences!!
j'aime particulièrement (ainsi comme le verrouillage au niveau de la ligne) que InnoDB est basé sur la transaction, ce qui signifie que vous pouvez mettre à jour/insérer/créer/modifier/laisser tomber/etc plusieurs fois pour une "opération" de votre application web. Le problème qui se pose est que si seulement certains de ces changements/opérations finissent par être commis, mais d'autres non, vous finirez la plupart du temps (selon la conception spécifique de la base de données) avec une base de données avec des données/structure conflictuelles.
Note: avec Oracle, les déclarations create/alter/drop sont appelées "DDL" (définition des données), et déclenchent implicitement une propagation. Les instructions Insert/update/delete, appelées "DML" (manipulation de données), sont et non engagées automatiquement, mais seulement lorsqu'un DDL, commit, ou exit/quit est effectué (ou si vous définissez votre session à "auto-commit", ou si votre client auto-commit). Il est impératif d'être conscient de cela en travaillant avec Oracle, mais je ne suis pas sûr comment MySQL gère les deux types de déclarations. Pour cette raison, je tiens à préciser que je ne suis pas sûr de cela quand il s'agit de MySQL; seulement avec Oracle.
un exemple de quand les moteurs basés sur les transactions excel:
disons que j'ai ou que vous êtes sur une page web pour s'inscrire pour participer à un événement gratuit, et l'un des principaux objectifs de ce système est de permettre seulement jusqu'à 100 personnes pour vous inscrire, car c'est la limite des places pour l'événement. Une fois de 100 les inscriptions sont atteintes, le système désactiverait d'autres inscriptions, au moins jusqu'à ce que d'autres annulent.
dans ce cas, il peut y avoir une table pour les invités (nom, téléphone, email, etc.), et une deuxième table qui suit le nombre d'invités qui se sont inscrits. Nous avons donc deux opérations pour une "transaction". Supposons maintenant qu'une fois les informations guest ajoutées à la table GUESTS, il y ait une perte de connexion, ou une erreur avec le même impact. La table des invités a été mise à jour (insérée dans), mais la connexion a été perdue avant que les "sièges disponibles" puissent être mis à jour.
maintenant nous avons un invité ajouté à la table des invités, mais le nombre de sièges disponibles est maintenant incorrect (par exemple, la valeur est de 85 alors qu'il est en fait 84).
bien sûr il y a plusieurs façons de gérer cela, comme suivre les sièges disponibles avec "100 moins le nombre de rangées dans la table des invités", ou un code qui vérifie que l'information est cohérente, etc.... Mais avec un moteur de base de données basé sur les transactions comme InnoDB, soit toutes des opérations sont engagées, ou aucune d'entre eux sont. Cela peut être utile dans de nombreux cas, mais comme je l'ai dit, ce n'est pas la seule façon d'être sûr, non (une belle façon, cependant, géré par la base de données, pas le programmeur/script-writer).
C'est tout" basé sur la transaction " signifie essentiellement dans ce contexte, à moins que je manque quelque chose -- que soit l'ensemble transaction réussit comme il se doit, ou rien est modifié, car faire seulement des changements partiels pourrait faire un désordre mineur à grave de la base de données, peut-être même la corrompre...
Mais je vais le dire une fois de plus, ce n'est pas le seul moyen d'éviter de faire un gâchis. Mais c'est l'une des méthodes que le moteur lui-même gère, vous laissant à code/script avec seulement besoin de se soucier de "a été la transaction réussie ou non, et ce que je fais si non (tels que réessayez), "au lieu d'écrire manuellement le code pour le vérifier "manuellement" de l'extérieur de la base de données, et faire beaucoup plus de travail pour de tels événements.
enfin, une note sur le verrouillage de table vs le verrouillage de ligne:
AVERTISSEMENT: j'ai peut-être tort dans tout ce qui suit en ce qui concerne MySQL, et l'hypothétique/exemple les situations sont des choses à découvrir, mais j'ai peut-être tort dans ce exactement est possible à cause de la corruption avec MySQL. Les exemples sont cependant très réels dans la programmation générale, même si MySQL a plus de mécanismes pour éviter de telles choses...
de toute façon, je suis assez sûr d'être d'accord avec ceux qui ont fait valoir que combien de connexions sont permises à la fois fait pas travail autour d'une table verrouillée. En fait, les connexions multiples sont le point entier de verrouillage d'une table!! de sorte que d'autres processus / utilisateurs / applications ne sont pas en mesure de corrompre la base de données en y apportant des modifications en même temps.
comment deux ou plusieurs connexions travaillant sur la même rangée feraient-elles une très mauvaise journée pour vous?? Supposons qu'il y ait deux processus qui veulent/doivent mettre à jour la même valeur dans la même rangée, disons parce que la rangée est un enregistrement d'un tour en bus, et que chacun des deux processus veut mettre à jour simultanément le champ "riders" ou "disponable_seats" comme "la valeur courante plus 1."
nous allons faire cette hypothèse, étape par étape:
- processus on lit la valeur actuelle, disons qu'elle est vide, donc '0' jusqu'à présent.
- processus deux lit la valeur courante ainsi, qui est toujours 0.
- le Processus d'écriture (courant + 1) qui est de 1.
- deux devrait écrire 2, mais depuis qu'il a lu la valeur actuelle avant le processus d'écriture de la nouvelle valeur, il écrit aussi 1 à la table.
je suis Je ne suis pas certain que deux connexions puissent se mêler comme ça, les deux lisant Avant que le premier n'écrive... Mais si non, alors je verrais encore un problème avec:
- processus on lit la valeur courante, qui est 0.
- le Processus d'écriture (courant + 1), qui est 1.
- processus deux lit la valeur courante maintenant. Mais alors que process one a écrit (update), il n'a pas engagé les données, donc seul ce même processus peut lire la nouvelle valeur qu'il a mise à jour, alors que tous les autres voient la valeur plus ancienne, jusqu'à ce qu'il y ait une propagation.
en outre, au moins avec les bases de données Oracle, Il ya des niveaux d'isolement, que je ne vais pas perdre notre temps à essayer de paraphraser. Voici un bon article sur ce sujet, et chaque niveau d'isolement a ses avantages et inconvénients, ce qui irait de pair avec la façon dont les moteurs de transactions importants peuvent se trouver dans une base de données...
enfin, il pourrait y avoir différentes mesures de protection en place au sein de MyISAM, plutôt que des clés étrangères et une interaction fondée sur la transaction. Eh bien, pour un, il ya le fait qu'une table entière est verrouillée, ce qui rend moins probable que les transactions/FKs sont nécessaire .
Et hélas, si vous êtes conscient de ces problèmes de concurrence, oui, vous pouvez jouer moins fort et juste écrivez vos applications, configurez vos systèmes de sorte que de telles erreurs ne soient pas possibles (votre code est alors responsable, plutôt que la base de données elle-même). Cependant, à mon avis, je dirais qu'il est toujours préférable d'utiliser autant de garanties que possible, de la programmation, sur la défensive, et toujours être conscient que l'erreur humaine est impossible d'éviter complètement. Cela arrive à tout le monde, et quiconque dit qu'il est immunisé doit mentir, ou n'a pas fait plus que d'écrire une application/script "Hello World". ;- )
j'espère que CERTAINS de qui est utile à certains, et même plus-donc, j'espère que je n'ai pas seulement été un coupable d'hypothèses et d'être un homme dans l'erreur!! Mes excuses si c'est le cas, mais les exemples sont bons à réfléchir, à rechercher le risque de, et ainsi de suite, même s'ils ne sont pas potentiels dans ce contexte spécifique.
n'hésitez pas à me corriger, à modifier cette" réponse", voire à la rejeter. S'il vous plaît essayer d'améliorer, plutôt que de corriger un mauvais hypothèse de la mine avec un autre. ;- )
c'est ma première réponse, alors veuillez pardonner la longueur due à tous les disclaimers, etc... Je ne veux pas paraître arrogant quand je ne suis pas absolument certain!
je pense que c'est un excellent article sur l'explication des différences et lorsque vous utilisez l'un sur l'autre: http://tag1consulting.com/MySQL_Engines_MyISAM_vs_InnoDB
aussi vérifier quelques remplacements pour MySQL lui-même:
MariaDB
MariaDB est un serveur de base de données qui offre des fonctionnalités de remplacement pour MySQL. MariaDB est construit par certains des Auteurs originaux de MySQL, avec l'aide de la communauté plus large des développeurs de logiciels libres et open source. Outre le noyau de l' fonctionnalité de MySQL, MariaDB offre un riche ensemble d'améliorations de fonctionnalités, y compris les moteurs de stockage alternatifs, les optimisations de serveur, et les correctifs.
Percona Server
https://launchpad.net/percona-server
une solution de remplacement améliorée pour MySQL, avec de meilleures performances, de meilleurs diagnostics et des fonctionnalités supplémentaires.
MyISAM
le MyISAM engine est le moteur par défaut dans la plupart des installations MySQL et est un dérivé du type de moteur ISAM d'origine pris en charge dans les premières versions du système MySQL. Le moteur offre la meilleure combinaison de performances et de fonctionnalités, bien qu'il ne dispose pas de capacités de transaction (utilisez les moteurs InnoDB ou BDB ) et utilise table-level locking .
FlashMAX et Flashmax Connect: à la tête de la Transformation de la plateforme Flash Télécharger Maintenant Sauf si vous avez besoin de transactions, il y a peu de bases de données et d'applications qui ne peuvent pas être efficacement stockées en utilisant le moteur MyISAM. Cependant, les applications très performantes où il y a un grand nombre d'inserts/mises à jour de données par rapport au nombre de lectures peuvent causer des problèmes de performance pour le moteur MyISAM. Il a été conçu à l'origine avec l'idée que plus de 90% de l'accès à la base de données D'une table MyISAM serait lit, plutôt que de l'écrit.
avec le verrouillage au niveau de la table, une base de données avec un nombre élevé d'inserts de ligne ou de mises à jour devient un goulot d'étranglement de performance que la table est verrouillée tandis que les données sont ajoutées. Heureusement, cette limitation fonctionne aussi bien dans les limites d'une base de données sans transaction.
MyISAM Summary
Nom - MyISAM
introduit - v3.23.
installation par défaut - Oui
limitations des données - aucune
limitations de L'Index -64 index par tableau (32 pre 4.1.2); Max 16 colonnes par index
soutien de Transaction - No
niveau de verrouillage - Table
InnoDB
le InnoDB Engine est fourni par Innobase Oy et prend en charge toutes les fonctionnalités de base de données (et plus) du moteur MyISAM et ajoute également des capacités de transaction complète (avec conformité complète ACID (atomicité, cohérence, Isolation, et durabilité)) et le verrouillage de niveau de ligne des données.
la clé du système InnoDB est une structure de base de données, de mise en cache et d'indexation où les index et les données sont mis en mémoire en plus d'être stocké sur disque. Cela permet une récupération très rapide, et fonctionne même sur de très grands ensembles de données. En supportant le verrouillage de niveau de ligne, vous pouvez ajouter des données à une table InnoDB sans que le moteur bloque la table avec chaque insertion et cela accélère à la fois la récupération et le stockage de l'information dans la base de données.
comme pour MyISAM , il y a peu de types de données qui ne peuvent pas être efficacement stockés dans une base de données InnoDB. En fait, il n'y a pas significative raisons pour lesquelles vous ne devriez pas toujours utiliser une base de données InnoDB. Les frais généraux de gestion pour InnoDB est légèrement plus onéreux, et obtenir l'optimisation juste pour les tailles de la mémoire et sur les caches de disque et les fichiers de base de données peut être complexe au début. Cependant, cela signifie également que vous obtenez plus de flexibilité sur ces valeurs et une fois mis, les avantages de performance peuvent facilement l'emporter sur le temps initial passé. Vous pouvez aussi laisser MySQL gérer cela automatiquement pour vous.
si vous êtes prêt (et capable) de configurer les paramètres InnoDB pour votre serveur, alors je vous recommande de passer le temps d'optimiser la configuration de votre serveur et ensuite d'utiliser le moteur InnoDB par défaut.
InnoDB Summary
Nom - InnoDB
introduit - v3.23 (source seulement), v4.0 (source et binaire)
Installation par défaut - Non
limitations des données - aucune
limitations de L'indice - aucune
support de Transaction - Oui (conforme à L'acide)
niveau de verrouillage - rangée
D'après mon expérience, MyISAM était un meilleur choix tant que vous ne faites pas des suppressions, des mises à jour, tout un tas d'insertions simples, des transactions, et l'indexation en texte intégral. La table à cocher est horrible. Comme le tableau grandit en termes de nombre de lignes, vous ne savez pas quand ce sera la fin.
J'ai compris que même si Myisam a des problèmes de verrouillage, il est toujours plus rapide que InnoDb dans la plupart des scénarios en raison du système d'acquisition de verrouillage rapide qu'il utilise. J'ai essayé plusieurs fois Innodb et je retombe toujours sur MyIsam pour une raison ou une autre. Aussi InnoDB peut être très intensif CPU dans les charges d'écriture énormes.
chaque application a son propre profil de performance pour utiliser une base de données, et il est probable qu'il va changer avec le temps.
la meilleure chose à faire est de tester vos options. Basculer entre MyISAM et InnoDB est trivial, alors chargez quelques données d'essai et le jmeter de feu contre votre site et voir ce qui se passe.
j'ai essayé d'exécuter l'insertion de données aléatoires dans MyISAM et InnoDB tables. Le résultat fut assez choquant. MyISAM a eu besoin de quelques secondes de moins pour insérer 1 million de lignes que InnoDB pour seulement 10 000!
myisam est un NOGO pour ce type de travail (haute simultanéité écrit), je n'ai pas beaucoup d'expérience avec innodb (testé 3 fois et a trouvé, dans chaque cas, les performances sont mauvaises, mais il a été un moment depuis le dernier test) si vous n'êtes pas forcé d'exécuter mysql, envisagez de donner à postgres un essai car il gère écrit concurremment beaucoup mieux
je sais que ce ne sera pas populaire Mais voici:
myISAM ne supporte pas les bases de données essentielles comme les transactions et l'intégrité référentielle qui entraîne souvent des applications Buggy / Buggy. Vous ne pouvez pas apprendre les fondamentaux de conception de base de données si elles ne sont même pas prises en charge par votre moteur de base de données.
ne pas utiliser l'intégrité référentielle ou des transactions dans le monde des bases de données est comme ne pas utiliser la programmation orientée objet dans le logiciel monde.
InnoDB existe maintenant, utilisez cela à la place! Même les développeurs MySQL ont finalement concédé de changer cela au moteur par défaut dans les nouvelles versions, malgré myISAM étant le moteur d'origine qui était le défaut dans tous les systèmes hérités.
Non cela n'a pas d'importance si vous êtes en train de lire ou d'écrire ou quelles sont les considérations de performance que vous avez, l'utilisation de myISAM peut entraîner une variété de problèmes, comme celui que je viens de rencontrer: j'effectuais une synchronisation de base de données et en même temps, quelqu'un d'autre accédait à une application qui accédait à une table placée sur myISAM. En raison du manque de support de transaction et de la fiabilité généralement faible de ce moteur, cela a écrasé l'ensemble de la base de données et j'ai dû redémarrer manuellement mysql!
au cours des 15 dernières années de développement, j'ai utilisé de nombreuses bases de données et de moteurs. myISAM s'est écrasé sur moi une douzaine de fois pendant cette période, d'autres bases de données, une seule fois! Et c'était une base de données Microsoft SQL où certains le développeur a écrit un code CLR défectueux (langage commun runtime - code C# qui s'exécute à l'intérieur de la base de données), soit dit en passant, ce n'était pas exactement la faute du moteur de la base de données.
je suis d'accord avec les autres réponses ici qui disent que haute disponibilité de qualité, les applications haute performance ne doivent pas utiliser myISAM car il ne fonctionnera pas, il n'est pas assez robuste ou stable pour entraîner une expérience sans frustration. Voir le projet de Loi Karwin la réponse pour plus de détails.
P. S. vous allez adorer quand myISAM fanboys downvote, mais ne peut pas vous dire quelle partie de cette réponse est incorrecte.
pour ce rapport de lecture / écriture, je suppose que InnoDB sera plus performant. Puisque vous êtes d'accord avec les lectures obscures, vous pourriez (Si vous en avez les moyens) répliquer à un esclave et laisser toutes vos lectures aller à l'esclave. En outre, envisager d'insérer en vrac, plutôt que d'un enregistrement à la fois.
presque chaque fois que je commence un nouveau projet, Je Google cette même question pour voir si je trouve de nouvelles réponses.
il se résume finalement à-je prends la dernière version de MySQL et exécuter des tests.
j'ai des tables où je veux faire des recherches de clés/valeurs... et c'est tout. J'ai besoin d'obtenir la valeur (0-512 octets) pour une clé de hachage. Il n'y a pas beaucoup de transactions sur cette base de données. La table reçoit des mises à jour de temps en temps (dans son intégralité), mais 0 transaction.
Donc, nous ne parlons pas d'un système complexe ici, nous parlons d'une recherche simple,.. et comment (autre que rendre la table résident RAM) nous pouvons optimiser les performances.
je fais aussi des tests sur d'autres bases de données (NoSQL) pour voir s'il y a un endroit où je peux obtenir un avantage. Le plus grand avantage que j'ai trouvé est dans la cartographie des clés, mais en ce qui concerne la recherche, MyISAM est en train de les surpasser toutes.
Bien Que, Je ne effectuerait pas de transactions financières avec les tables MyISAM, mais pour des recherches simples, vous devriez le tester.. typiquement 2x à 5x les requêtes / sec.
la Tester, je vous souhaite la bienvenue débat.
S'il est 70% inserts et 30% lit, alors il est plus comme sur le côté InnoDB.
en bref, InnoDB est bon si vous travaillez sur quelque chose qui a besoin d'une base de données fiable qui peut gérer beaucoup D'INSERT et des instructions de mise à jour.
et, MyISAM est bon si vous avez besoin d'une base de données qui sera la plupart du temps de prendre beaucoup d'instructions de lecture (sélectionner) plutôt que d'écrire (INSERT et mises à jour), compte tenu de son inconvénient sur la chose table-lock.
vous pouvez vérifier;
les avantages et les inconvénients de InnoDB
avantages et inconvénients de MyISAM
bottomline: si vous travaillez hors ligne avec selects sur de grands blocs de données, MyISAM vous donnera probablement de meilleures (bien meilleures) vitesses.
il y a certaines situations où MyISAM est infiniment plus efficace que InnoDB: lors de la manipulation de grandes données décharge hors ligne (en raison de table lock).
exemple: je convertissais un fichier csv (15m records) de NOAA qui utilise les champs VARCHAR comme clés. InnoDB prenait une éternité, même avec de grandes morceaux de mémoire disponibles.
ceci est un exemple de csv (premier et troisième champs sont des clés).
USC00178998,20130101,TMAX,-22,,,7,0700
USC00178998,20130101,TMIN,-117,,,7,0700
USC00178998,20130101,TOBS,-28,,,7,0700
USC00178998,20130101,PRCP,0,T,,7,0700
USC00178998,20130101,SNOW,0,T,,7,
puisque ce que j'ai besoin de faire est d'exécuter une mise à jour de lot hors ligne des phénomènes météorologiques observés, J'utilise la table MyISAM pour recevoir des données et exécuter des jointures sur les touches de sorte que je puisse nettoyer le fichier entrant et remplacer les champs VARCHAR avec les touches INT (qui sont liées aux tables externes où les valeurs VARCHAR originales sont stockées).