Moyenne mobile ou moyenne courante
Existe-t-il une fonction scipy ou une fonction numpy ou un module pour python qui calcule la moyenne courante D'un tableau 1D donné une fenêtre spécifique?
22 réponses
Pour une solution courte et rapide qui fait le tout en une seule boucle, sans dépendances, le code ci-dessous fonctionne très bien.
mylist = [1, 2, 3, 4, 5, 6, 7]
N = 3
cumsum, moving_aves = [0], []
for i, x in enumerate(mylist, 1):
cumsum.append(cumsum[i-1] + x)
if i>=N:
moving_ave = (cumsum[i] - cumsum[i-N])/N
#can do stuff with moving_ave here
moving_aves.append(moving_ave)
UPD: plus efficace des solutions ont été proposées par Alleo et jasaarim.
, Vous pouvez utiliser np.convolve pour qui:
np.convolve(x, np.ones((N,))/N, mode='valid')
Explication
L'exécution veux dire, c'est un cas de l'opération mathématique de convolution. Pour la moyenne courante, vous faites glisser une fenêtre le long de l'entrée et calculez la moyenne du contenu de la fenêtre. Pour les signaux 1D discrets, la convolution est la même chose, sauf au lieu de la moyenne que vous calculer une combinaison linéaire arbitraire, c'est à dire multiplier chaque élément par un coefficient et d'additionner les résultats. Ces coefficients, un pour chaque position dans la fenêtre, sont parfois appelés convolution kernel . Maintenant, la moyenne arithmétique de n valeurs est (x_1 + x_2 + ... + x_N) / N, donc le noyau correspondant est (1/N, 1/N, ..., 1/N), et c'est exactement ce que nous obtenons en utilisant np.ones((N,))/N.
Bords
L'argument mode de np.convolve spécifie comment gérer les bords. J'ai choisi le mode valid ici parce que Je pense que c'est comme ça que la plupart des gens s'attendent à ce que la course fonctionne, mais vous pouvez avoir d'autres priorités. Voici un graphique qui illustre la différence entre les modes:
import numpy as np
import matplotlib.pyplot as plt
modes = ['full', 'same', 'valid']
for m in modes:
plt.plot(np.convolve(np.ones((200,)), np.ones((50,))/50, mode=m));
plt.axis([-10, 251, -.1, 1.1]);
plt.legend(modes, loc='lower center');
plt.show()
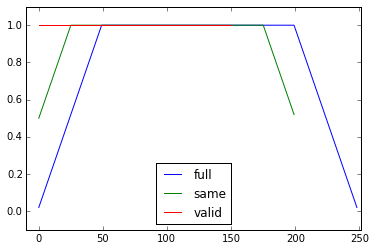
Efficace
La Convolution est bien meilleure que l'approche simple, mais (je suppose) elle utilise FFT et donc assez lente. Cependant, spécialement pour calculer la moyenne en cours d'exécution, l'approche suivante fonctionne bien
def running_mean(x, N):
cumsum = numpy.cumsum(numpy.insert(x, 0, 0))
return (cumsum[N:] - cumsum[:-N]) / float(N)
Le code à vérifier
In[3]: x = numpy.random.random(100000)
In[4]: N = 1000
In[5]: %timeit result1 = numpy.convolve(x, numpy.ones((N,))/N, mode='valid')
10 loops, best of 3: 41.4 ms per loop
In[6]: %timeit result2 = running_mean(x, N)
1000 loops, best of 3: 1.04 ms per loop
Remarque que numpy.allclose(result1, result2) est True, deux méthodes sont équivalentes.
Le plus grand N, la plus grande différence de temps.
Pandas est plus approprié pour cela que NumPy ou SciPy. Sa fonction rolling_mean fait le travail convenablement. Il renvoie également un tableau NumPy lorsque l'entrée est un tableau.
Il est difficile de battre rolling_mean en performance avec une implémentation Python pure personnalisée. Voici un exemple de performance par rapport à deux des solutions proposées:
In [1]: import numpy as np
In [2]: import pandas as pd
In [3]: def running_mean(x, N):
...: cumsum = np.cumsum(np.insert(x, 0, 0))
...: return (cumsum[N:] - cumsum[:-N]) / N
...:
In [4]: x = np.random.random(100000)
In [5]: N = 1000
In [6]: %timeit np.convolve(x, np.ones((N,))/N, mode='valid')
10 loops, best of 3: 172 ms per loop
In [7]: %timeit running_mean(x, N)
100 loops, best of 3: 6.72 ms per loop
In [8]: %timeit pd.rolling_mean(x, N)[N-1:]
100 loops, best of 3: 4.74 ms per loop
In [9]: np.allclose(pd.rolling_mean(x, N)[N-1:], running_mean(x, N))
Out[9]: True
Il y a aussi de bonnes options pour gérer les valeurs de bord.
Vous pouvez calculer une moyenne courante avec:
import numpy as np
def runningMean(x, N):
y = np.zeros((len(x),))
for ctr in range(len(x)):
y[ctr] = np.sum(x[ctr:(ctr+N)])
return y/N
Mais c'est lent.
Heureusement, numpy inclut une fonction convolve que nous pouvons utiliser pour accélérer les choses. La moyenne courante est équivalente à convolving x avec un vecteur qui est N long, avec tous les membres égaux à 1/N. L'implémentation numpy de convolve inclut le transitoire de départ, vous devez donc supprimer les premiers N-1 points:
def runningMeanFast(x, N):
return np.convolve(x, np.ones((N,))/N)[(N-1):]
Sur ma machine, la version rapide est 20-30 fois plus rapide, en fonction de la longueur du vecteur d'entrée et de la taille de la fenêtre de moyenne.
Notez que convolve inclut un mode 'same' qui semble devoir résoudre le problème transitoire de départ, mais il le divise entre le début et la fin.
Ou module pour python qui calcule
Dans mes tests à Tradewave.net TA-lib gagne toujours:
import talib as ta
import numpy as np
import pandas as pd
import scipy
from scipy import signal
import time as t
PAIR = info.primary_pair
PERIOD = 30
def initialize():
storage.reset()
storage.elapsed = storage.get('elapsed', [0,0,0,0,0,0])
def cumsum_sma(array, period):
ret = np.cumsum(array, dtype=float)
ret[period:] = ret[period:] - ret[:-period]
return ret[period - 1:] / period
def pandas_sma(array, period):
return pd.rolling_mean(array, period)
def api_sma(array, period):
# this method is native to Tradewave and does NOT return an array
return (data[PAIR].ma(PERIOD))
def talib_sma(array, period):
return ta.MA(array, period)
def convolve_sma(array, period):
return np.convolve(array, np.ones((period,))/period, mode='valid')
def fftconvolve_sma(array, period):
return scipy.signal.fftconvolve(
array, np.ones((period,))/period, mode='valid')
def tick():
close = data[PAIR].warmup_period('close')
t1 = t.time()
sma_api = api_sma(close, PERIOD)
t2 = t.time()
sma_cumsum = cumsum_sma(close, PERIOD)
t3 = t.time()
sma_pandas = pandas_sma(close, PERIOD)
t4 = t.time()
sma_talib = talib_sma(close, PERIOD)
t5 = t.time()
sma_convolve = convolve_sma(close, PERIOD)
t6 = t.time()
sma_fftconvolve = fftconvolve_sma(close, PERIOD)
t7 = t.time()
storage.elapsed[-1] = storage.elapsed[-1] + t2-t1
storage.elapsed[-2] = storage.elapsed[-2] + t3-t2
storage.elapsed[-3] = storage.elapsed[-3] + t4-t3
storage.elapsed[-4] = storage.elapsed[-4] + t5-t4
storage.elapsed[-5] = storage.elapsed[-5] + t6-t5
storage.elapsed[-6] = storage.elapsed[-6] + t7-t6
plot('sma_api', sma_api)
plot('sma_cumsum', sma_cumsum[-5])
plot('sma_pandas', sma_pandas[-10])
plot('sma_talib', sma_talib[-15])
plot('sma_convolve', sma_convolve[-20])
plot('sma_fftconvolve', sma_fftconvolve[-25])
def stop():
log('ticks....: %s' % info.max_ticks)
log('api......: %.5f' % storage.elapsed[-1])
log('cumsum...: %.5f' % storage.elapsed[-2])
log('pandas...: %.5f' % storage.elapsed[-3])
log('talib....: %.5f' % storage.elapsed[-4])
log('convolve.: %.5f' % storage.elapsed[-5])
log('fft......: %.5f' % storage.elapsed[-6])
Résultats:
[2015-01-31 23:00:00] ticks....: 744
[2015-01-31 23:00:00] api......: 0.16445
[2015-01-31 23:00:00] cumsum...: 0.03189
[2015-01-31 23:00:00] pandas...: 0.03677
[2015-01-31 23:00:00] talib....: 0.00700 # <<< Winner!
[2015-01-31 23:00:00] convolve.: 0.04871
[2015-01-31 23:00:00] fft......: 0.22306
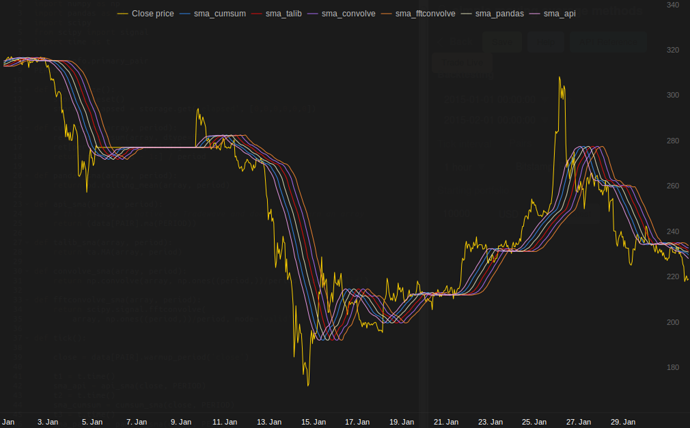
Pour une solution prête à l'emploi, voir http://www.scipy.org/Cookbook/SignalSmooth .
Il fournit la moyenne courante avec le type de fenêtre flat. Notez que c'est un peu plus sophistiqué que la simple méthode convolve do-it-yourself, car elle essaie de gérer les problèmes au début et à la fin des données en les reflétant (ce qui peut ou non fonctionner dans votre cas...).
Pour commencer, vous pouvez essayer:
a = np.random.random(100)
plt.plot(a)
b = smooth(a, window='flat')
plt.plot(b)
Je sais que c'est une vieille question, Mais voici une solution qui n'utilise pas de structures de données ou de bibliothèques supplémentaires. Il est linéaire dans le nombre d'éléments de la liste d'entrée et je ne peux pas penser à un autre moyen de le rendre plus efficace (en fait, si quelqu'un connaît une meilleure façon d'allouer le résultat, faites-le moi savoir).
NOTE: ce serait beaucoup plus rapide en utilisant un tableau numpy au lieu d'une liste, mais je voulais éliminer toutes les dépendances. Il serait également possible d'améliorer performance par exécution multithread
La fonction suppose que la liste d'entrée est unidimensionnelle, alors soyez prudent.
### Running mean/Moving average
def running_mean(l, N):
sum = 0
result = list( 0 for x in l)
for i in range( 0, N ):
sum = sum + l[i]
result[i] = sum / (i+1)
for i in range( N, len(l) ):
sum = sum - l[i-N] + l[i]
result[i] = sum / N
return result
Je n'ai pas encore vérifié à quelle vitesse c'est, mais vous pourriez essayer:
from collections import deque
cache = deque() # keep track of seen values
n = 10 # window size
A = xrange(100) # some dummy iterable
cum_sum = 0 # initialize cumulative sum
for t, val in enumerate(A, 1):
cache.append(val)
cum_sum += val
if t < n:
avg = cum_sum / float(t)
else: # if window is saturated,
cum_sum -= cache.popleft() # subtract oldest value
avg = cum_sum / float(n)
Un peu en retard à la fête, mais j'ai fait ma propre petite fonction qui ne s'enroule pas autour des extrémités ou des pads avec des zéros qui sont ensuite utilisés pour trouver la moyenne. Comme un autre traitement est, qu'il rééchantillonne également le signal à des points linéairement espacés. Personnaliser le code à volonté pour obtenir d'autres fonctionnalités.
La méthode est une simple multiplication matricielle avec un noyau gaussien normalisé.
def running_mean(y_in, x_in, N_out=101, sigma=1):
'''
Returns running mean as a Bell-curve weighted average at evenly spaced
points. Does NOT wrap signal around, or pad with zeros.
Arguments:
y_in -- y values, the values to be smoothed and re-sampled
x_in -- x values for array
Keyword arguments:
N_out -- NoOf elements in resampled array.
sigma -- 'Width' of Bell-curve in units of param x .
'''
N_in = size(y_in)
# Gaussian kernel
x_out = np.linspace(np.min(x_in), np.max(x_in), N_out)
x_in_mesh, x_out_mesh = np.meshgrid(x_in, x_out)
gauss_kernel = np.exp(-np.square(x_in_mesh - x_out_mesh) / (2 * sigma**2))
# Normalize kernel, such that the sum is one along axis 1
normalization = np.tile(np.reshape(sum(gauss_kernel, axis=1), (N_out, 1)), (1, N_in))
gauss_kernel_normalized = gauss_kernel / normalization
# Perform running average as a linear operation
y_out = gauss_kernel_normalized @ y_in
return y_out, x_out
Une utilisation simple sur un signal sinusoïdal avec ajout normal distribué bruit:
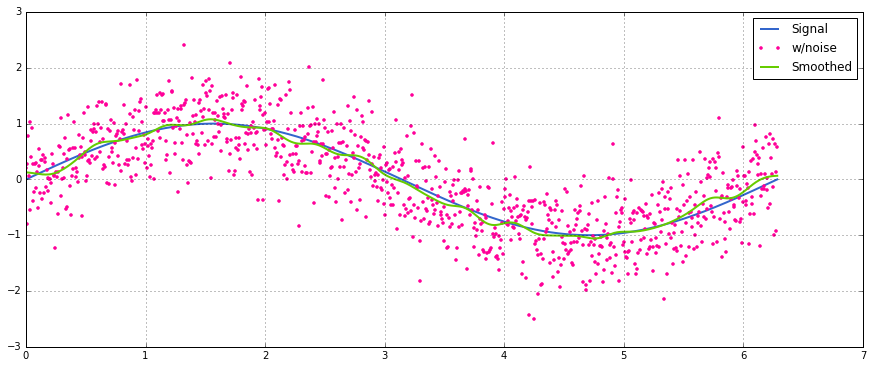
S'il est important de conserver les dimensions de l'entrée (au lieu de limiter la sortie à la zone 'valid' d'une convolution), vous pouvez utiliser scipy.ndimage.filtrer.uniform_filter1d :
import numpy as np
from scipy.ndimage.filters import uniform_filter1d
N = 1000
x = np.random.random(100000)
y = uniform_filter1d(x, size=N)
y.shape == x.shape
>>> True
uniform_filter1d permet plusieurs façons de gérer la bordure où 'reflect' est la valeur par défaut, mais dans mon cas, je voulais plutôt 'nearest'.
Il est également assez rapide (près de 50 fois plus rapide que np.convolve):
%timeit y1 = np.convolve(x, np.ones((N,))/N, mode='same')
100 loops, best of 3: 9.28 ms per loop
%timeit y2 = uniform_filter1d(x, size=N)
10000 loops, best of 3: 191 µs per loop
Une autre approche pour trouver la moyenne mobile Sans en utilisant numpy, panda
import itertools
sample = [2, 6, 10, 8, 11, 10]
list(itertools.starmap(lambda a,b: b/a,
enumerate(itertools.accumulate(sample), 1)))
Va imprimer [2.0, 4.0, 6.0, 6.5, 7.4, 7.833333333333333]
Cette question est maintenant encore plus ancienne que lorsque NeXuS a écrit à ce sujet le mois dernier, mais j'aime la façon dont son code traite des cas de bord. Cependant, parce qu'il s'agit d'une "moyenne mobile simple", ses résultats sont en retard sur les données auxquelles ils s'appliquent. Je pensais que traiter les cas de bord d'une manière plus satisfaisante que les modes de NumPy valid, same, et full pourrait être réalisé en appliquant une approche similaire à une méthode basée sur convolution().
Ma contribution utilise une moyenne courante centrale pour aligner ses résultats avec leurs données. Lorsqu'il y a trop peu de points disponibles pour que la fenêtre pleine grandeur soit utilisée, les moyennes courantes sont calculées à partir de fenêtres successivement plus petites sur les bords du tableau. [En fait, à partir de fenêtres successivement plus grandes, mais c'est un détail d'implémentation.]
import numpy as np
def running_mean(l, N):
# Also works for the(strictly invalid) cases when N is even.
if (N//2)*2 == N:
N = N - 1
front = np.zeros(N//2)
back = np.zeros(N//2)
for i in range(1, (N//2)*2, 2):
front[i//2] = np.convolve(l[:i], np.ones((i,))/i, mode = 'valid')
for i in range(1, (N//2)*2, 2):
back[i//2] = np.convolve(l[-i:], np.ones((i,))/i, mode = 'valid')
return np.concatenate([front, np.convolve(l, np.ones((N,))/N, mode = 'valid'), back[::-1]])
C'est relativement lent car il utilise convolve(), et pourrait probablement être amélioré beaucoup par un vrai Pythonista, cependant, je crois que l'idée est valable.
Au lieu de numpy ou scipy, je recommanderais aux pandas de le faire plus rapidement:
df['data'].rolling(3).mean()
Cela prend la moyenne mobile (MA) de 3 périodes de la colonne "données". Vous pouvez également calculer les versions décalées, par exemple celle qui exclut la cellule actuelle (décalée en arrière) peut être calculée facilement comme:
df['data'].shift(periods=1).rolling(3).mean()
Bien qu'il existe des solutions pour cette question ici, veuillez jeter un oeil à ma solution. Il est très simple et fonctionne bien.
import numpy as np
dataset = np.asarray([1, 2, 3, 4, 5, 6, 7])
ma = list()
window = 3
for t in range(0, len(dataset)):
if t+window <= len(dataset):
indices = range(t, t+window)
ma.append(np.average(np.take(dataset, indices)))
else:
ma = np.asarray(ma)
Il y a beaucoup de réponses ci-dessus sur le calcul d'une moyenne courante. Ma réponse ajoute deux fonctionnalités supplémentaires:
- ignore les valeurs nan
- calcule la moyenne des N valeurs voisines N'incluant pas la valeur d'intérêt elle-même
Cette deuxième caractéristique est particulièrement utile pour déterminer quelles valeurs diffèrent d'une certaine manière de la tendance générale.
J'utilise numpy.cumsum puisque c'est la méthode la plus efficace en temps (voir la réponse D'Alleo ci-dessus).
N=10 # number of points to test on each side of point of interest, best if even
padded_x = np.insert(np.insert( np.insert(x, len(x), np.empty(int(N/2))*np.nan), 0, np.empty(int(N/2))*np.nan ),0,0)
n_nan = np.cumsum(np.isnan(padded_x))
cumsum = np.nancumsum(padded_x)
window_sum = cumsum[N+1:] - cumsum[:-(N+1)] - x # subtract value of interest from sum of all values within window
window_n_nan = n_nan[N+1:] - n_nan[:-(N+1)] - np.isnan(x)
window_n_values = (N - window_n_nan)
movavg = (window_sum) / (window_n_values)
Ce code fonctionne même pour Ns seulement. Il peut être ajusté pour les nombres impairs en changeant le np.insert de padded_x et n_nan.
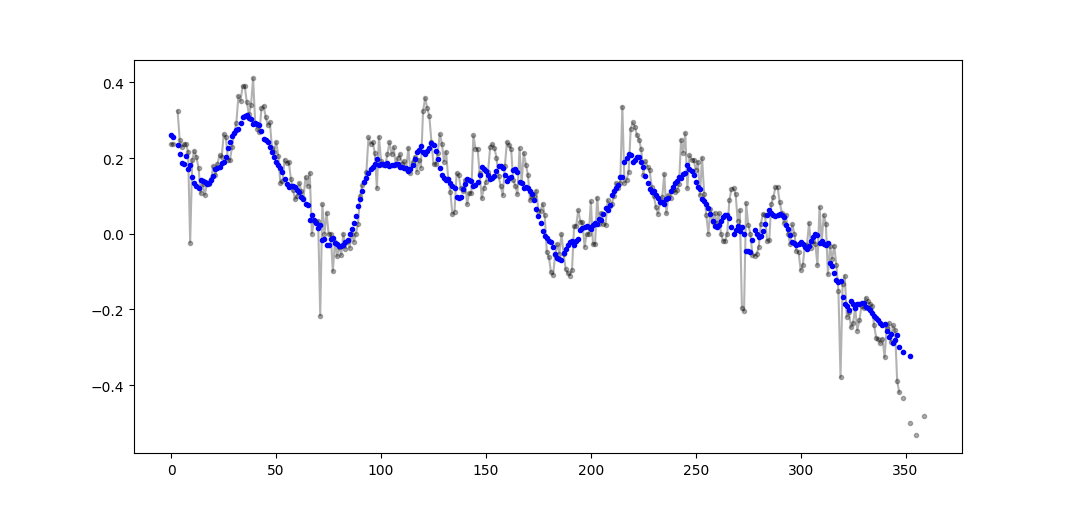
Exemple de sortie (raw en noir, movavg en bleu):
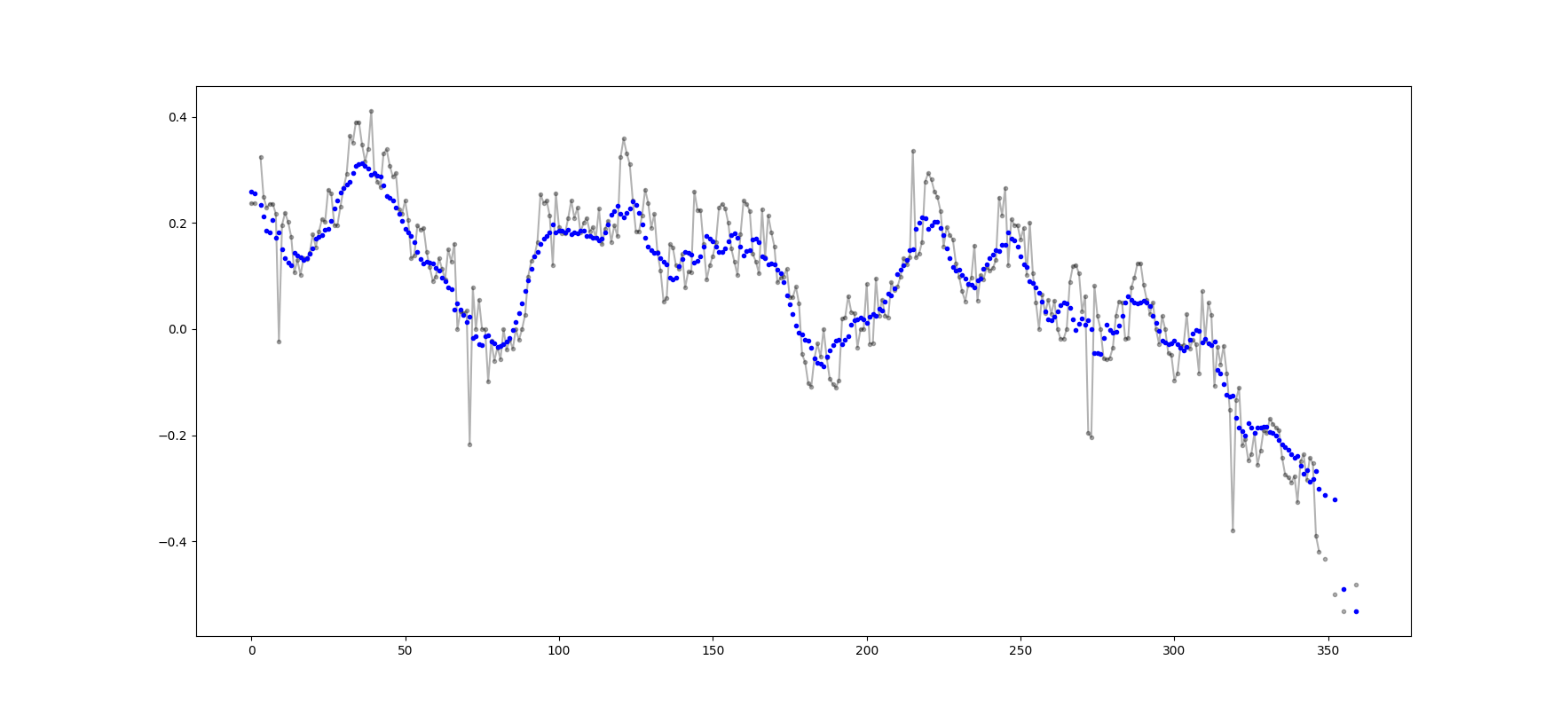
Ce code peut être facilement adapté pour supprimer toutes les valeurs moyennes mobiles calculées à partir de moins de cutoff = 3 valeurs non-nan.
window_n_values = (N - window_n_nan).astype(float) # dtype must be float to set some values to nan
cutoff = 3
window_n_values[window_n_values<cutoff] = np.nan
movavg = (window_sum) / (window_n_values)
Utilisez Uniquement La Bibliothèque Python Stadnard (Mémoire Efficace)
Donnez simplement une autre version de l'utilisation de la bibliothèque standard deque uniquement. Il est assez surprenant pour moi que la plupart des réponses utilisent pandas ou numpy.
def moving_average(iterable, n=3):
d = deque(maxlen=n)
for i in iterable:
d.append(i)
if len(d) == n:
yield sum(d)/n
r = moving_average([40, 30, 50, 46, 39, 44])
assert list(r) == [40.0, 42.0, 45.0, 43.0]
Actaully j'ai trouvé une autre implémentation dans les docs python
def moving_average(iterable, n=3):
# moving_average([40, 30, 50, 46, 39, 44]) --> 40.0 42.0 45.0 43.0
# http://en.wikipedia.org/wiki/Moving_average
it = iter(iterable)
d = deque(itertools.islice(it, n-1))
d.appendleft(0)
s = sum(d)
for elem in it:
s += elem - d.popleft()
d.append(elem)
yield s / n
Cependant, l'implémentation me semble un peu plus complexe qu'elle ne devrait l'être. Mais il doit être dans les documents Python standard pour une raison, quelqu'un pourrait-il Commenter le mise en œuvre de la mine et de la norme doc?
En lisant les autres réponses, Je ne pense pas que ce soit ce que la question demandait, mais je suis arrivé ici avec le besoin de garder une moyenne courante d'une liste de valeurs qui augmentait en taille.
Donc, si vous voulez conserver une liste de valeurs que vous achetez quelque part (un site, un appareil de mesure, etc.) et la moyenne des dernières valeurs n mises à jour, vous pouvez utiliser le code ci-dessous, qui minimise l'effort d'ajout de nouveaux éléments:
class Running_Average(object):
def __init__(self, buffer_size=10):
"""
Create a new Running_Average object.
This object allows the efficient calculation of the average of the last
`buffer_size` numbers added to it.
Examples
--------
>>> a = Running_Average(2)
>>> a.add(1)
>>> a.get()
1.0
>>> a.add(1) # there are two 1 in buffer
>>> a.get()
1.0
>>> a.add(2) # there's a 1 and a 2 in the buffer
>>> a.get()
1.5
>>> a.add(2)
>>> a.get() # now there's only two 2 in the buffer
2.0
"""
self._buffer_size = int(buffer_size) # make sure it's an int
self.reset()
def add(self, new):
"""
Add a new number to the buffer, or replaces the oldest one there.
"""
new = float(new) # make sure it's a float
n = len(self._buffer)
if n < self.buffer_size: # still have to had numbers to the buffer.
self._buffer.append(new)
if self._average != self._average: # ~ if isNaN().
self._average = new # no previous numbers, so it's new.
else:
self._average *= n # so it's only the sum of numbers.
self._average += new # add new number.
self._average /= (n+1) # divide by new number of numbers.
else: # buffer full, replace oldest value.
old = self._buffer[self._index] # the previous oldest number.
self._buffer[self._index] = new # replace with new one.
self._index += 1 # update the index and make sure it's...
self._index %= self.buffer_size # ... smaller than buffer_size.
self._average -= old/self.buffer_size # remove old one...
self._average += new/self.buffer_size # ...and add new one...
# ... weighted by the number of elements.
def __call__(self):
"""
Return the moving average value, for the lazy ones who don't want
to write .get .
"""
return self._average
def get(self):
"""
Return the moving average value.
"""
return self()
def reset(self):
"""
Reset the moving average.
If for some reason you don't want to just create a new one.
"""
self._buffer = [] # could use np.empty(self.buffer_size)...
self._index = 0 # and use this to keep track of how many numbers.
self._average = float('nan') # could use np.NaN .
def get_buffer_size(self):
"""
Return current buffer_size.
"""
return self._buffer_size
def set_buffer_size(self, buffer_size):
"""
>>> a = Running_Average(10)
>>> for i in range(15):
... a.add(i)
...
>>> a()
9.5
>>> a._buffer # should not access this!!
[10.0, 11.0, 12.0, 13.0, 14.0, 5.0, 6.0, 7.0, 8.0, 9.0]
Decreasing buffer size:
>>> a.buffer_size = 6
>>> a._buffer # should not access this!!
[9.0, 10.0, 11.0, 12.0, 13.0, 14.0]
>>> a.buffer_size = 2
>>> a._buffer
[13.0, 14.0]
Increasing buffer size:
>>> a.buffer_size = 5
Warning: no older data available!
>>> a._buffer
[13.0, 14.0]
Keeping buffer size:
>>> a = Running_Average(10)
>>> for i in range(15):
... a.add(i)
...
>>> a()
9.5
>>> a._buffer # should not access this!!
[10.0, 11.0, 12.0, 13.0, 14.0, 5.0, 6.0, 7.0, 8.0, 9.0]
>>> a.buffer_size = 10 # reorders buffer!
>>> a._buffer
[5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0, 13.0, 14.0]
"""
buffer_size = int(buffer_size)
# order the buffer so index is zero again:
new_buffer = self._buffer[self._index:]
new_buffer.extend(self._buffer[:self._index])
self._index = 0
if self._buffer_size < buffer_size:
print('Warning: no older data available!') # should use Warnings!
else:
diff = self._buffer_size - buffer_size
print(diff)
new_buffer = new_buffer[diff:]
self._buffer_size = buffer_size
self._buffer = new_buffer
buffer_size = property(get_buffer_size, set_buffer_size)
Et vous pouvez le tester avec, pour exemple:
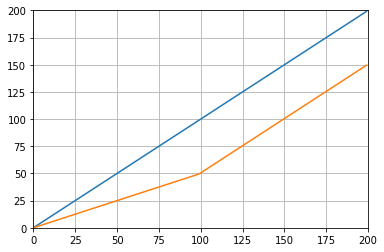
def graph_test(N=200):
import matplotlib.pyplot as plt
values = list(range(N))
values_average_calculator = Running_Average(N/2)
values_averages = []
for value in values:
values_average_calculator.add(value)
values_averages.append(values_average_calculator())
fig, ax = plt.subplots(1, 1)
ax.plot(values, label='values')
ax.plot(values_averages, label='averages')
ax.grid()
ax.set_xlim(0, N)
ax.set_ylim(0, N)
fig.show()
Qui donne:
Que diriez-vous de un filtre de moyenne mobile ? Il est également un one-liner et a l'avantage, que vous pouvez facilement manipuler le type de fenêtre si vous avez besoin d'autre chose que le rectangle, à savoir. une moyenne mobile simple n-longue d'un tableau a:
lfilter(np.ones(N)/N, [1], a)[N:]
Et avec la fenêtre triangulaire appliquée:
lfilter(np.ones(N)*scipy.signal.triang(N)/N, [1], a)[N:]
Il y a un commentaire de mab enterré dans l'une des réponses ci-dessus qui a cette méthode. bottleneck a move_mean, qui est une moyenne mobile simple:
import numpy as np
import bottleneck as bn
a = np.arange(10) + np.random.random(10)
mva = bn.move_mean(a, window=2, min_count=1)
min_count est un paramètre pratique qui prendra essentiellement la moyenne mobile jusqu'à ce point dans votre tableau. Si vous ne définissez pas min_count, il sera égal à window, et tout à window points nan.
Une autre solution utilisant simplement une bibliothèque standard et deque:
from collections import deque
import itertools
def moving_average(iterable, n=3):
# http://en.wikipedia.org/wiki/Moving_average
it = iter(iterable)
# create an iterable object from input argument
d = deque(itertools.islice(it, n-1))
# create deque object by slicing iterable
d.appendleft(0)
s = sum(d)
for elem in it:
s += elem - d.popleft()
d.append(elem)
yield s / n
# example on how to use it
for i in moving_average([40, 30, 50, 46, 39, 44]):
print(i)
# 40.0
# 42.0
# 45.0
# 43.0
Si vous choisissez de lancer le vôtre, plutôt que d'utiliser une bibliothèque existante, soyez conscient de l'erreur en virgule flottante et essayez de minimiser ses effets:
class SumAccumulator:
def __init__(self):
self.values = [0]
self.count = 0
def add( self, val ):
self.values.append( val )
self.count = self.count + 1
i = self.count
while i & 0x01:
i = i >> 1
v0 = self.values.pop()
v1 = self.values.pop()
self.values.append( v0 + v1 )
def get_total(self):
return sum( reversed(self.values) )
def get_size( self ):
return self.count
Si toutes vos valeurs sont à peu près du même ordre de grandeur, cela aidera à préserver la précision en ajoutant toujours des valeurs de magnitudes à peu près similaires.