Fusionner les PDF avec PDFTK avec des signets?
utiliser pdftk pour fusionner plusieurs pdf fonctionne bien. Cependant, un moyen facile de faire un signet pour chaque pdf fusionné?
Je ne vois rien sur le pdftk docs à ce sujet donc je ne pense pas que ce soit possible avec pdftk.
tous nos fichiers fusionnés seront d'une page, donc vous vous demandez s'il y a un autre utilitaire qui peut ajouter des signets par la suite?
ou un autre utilitaire pdf basé sur linux qui permettra de fusionner tout en spécifiant un signet pour chaque pdf individuel.
10 réponses
vous pouvez aussi fusionner plusieurs fichiers PDF avec Ghostscript. Le grand avantage de cette voie est qu'une solution est facilement scriptable, et ne nécessite pas un réel effort de programmation:
gswin32c.exe ^
-dBATCH -dNOPAUSE ^
-sDEVICE=pdfwrite ^
-sOutputFile=merged.pdf ^
[...more Ghostscript options as needed...] ^
input1.pdf input2.pdf input3.pdf [....]
avec Ghostscript vous pourrez passer pdfmark déclarations qui peuvent ajouter une Table des matières ainsi que des signets pour chaque fichier source supplémentaire allant dans le PDF résultant. Par exemple:
gswin32c.exe ^
-dBATCH -dNOPAUSE ^
-sDEVICE=pdfwrite ^
-sOutputFile=merged.pdf ^
[...more Ghostscript options as needed...] ^
file-with-pdfmarks-to-generate-a-ToC.ps ^
-f input1.pdf input2.pdf input3.pdf [....]
ou
gswin32c.exe ^
-dBATCH -dNOPAUSE ^
-sDEVICE=pdfwrite ^
-sOutputFile=merged.pdf ^
[...more Ghostscript options as needed...] ^
file-with-pdfmarks-to-generate-a-ToC.ps ^
-f input1.pdf ^
input2.pdf ^
input3.pdf [....]
Pour une introduction à la pdfmark sujet, voir aussi Thomas Merz PDFmark Primer .
modifier:
Je voulais vous donner un exemple pour file-with-pdfmarks-to-generate-a-ToC.ps , mais en quelque sorte oublié. Le voici:
[/Page 1 /View [/XYZ null null null] /Title (File 1) /OUT pdfmark
[/Page 2 /View [/XYZ null null null] /Title (File 2) /OUT pdfmark
[/Page 3 /View [/XYZ null null null] /Title (File 3) /OUT pdfmark
[/Page 4 /View [/XYZ null null null] /Title (File 4) /OUT pdfmark
cela créerait un ToC Pour le les 4 Premiers fichiers = = les 4 premières pages (puisque vous garantissez que vos fichiers ingrédients sont d'une page chacun pour votre fichier PDF fusionné).
- la partie
[/XYZ null null null]s'assure que le niveau de vue et de zoom de votre page ne change pas par rapport au niveau actuel lorsque vous suivez le lien. (Vous pouvez dire[/XYZ 222 111 2]pour le faire, si vous voulez un exemple arbitraire.) - le
/Title (some string you want)Machin détermine quel texte est dans la table des matières.
et, vous pourriez même ajouter ces paramètres à la ligne de commande Ghostscript directement:
gswin32c.exe ^
-o merged.pdf ^
[...more Ghostscript options as needed...] ^
-c "[/Page 1 /View [/XYZ null null null] /Title (File 1) /OUT pdfmark" ^
-c "[/Page 2 /View [/XYZ null null null] /Title (File 2) /OUT pdfmark" ^
-c "[/Page 3 /View [/XYZ null null null] /Title (File 3) /OUT pdfmark" ^
-c "[/Page 4 /View [/XYZ null null null] /Title (File 4) /OUT pdfmark" ^
-f input1.pdf ^
input2.pdf ^
input3.pdf ^
input4.pdf [....]
'nouvelle édition:
Oh, et par la manière: Ghostscript ne préserver les signets lorsque vous l'utilisez pour fusionner deux fichiers PDF en un seul -- pdftk.exe ne fonctionne pas. Utilisons celui généré par la commande de ma première édition (concaténant effectivement 2 copies du même fichier):
gswin32c ^
-sDEVICE=pdfwrite ^
-o doublemerged.pdf ^
merged.pdf ^
merged.pdf
le fichier doublemerged.pdf aura désormais 2*4 = 8 signets.
- Ce qui est comme prévu: les signets 1, 2, 3, et 4 lien vers les pages 1, 2, 3 et 4.
- le problème est que les signets 5, 6, 7 et 8 renvoient aussi aux pages 1, 2, 3 et 4.
la raison est que les signets préexistants ont traité leurs cibles de lien par des nombres de page absolus. Pour contourner cela (et les signets fonctionnent dans les fichiers fusionnés), il faudrait générer des signets qui pointent pour lier des cibles par des destinations nommées (et s'assurer que ce sont des uniq à travers des documents qui sont fusionnés).
(cette approche fonctionne aussi sur linux, utilisez simplement gs au lieu de gswin32c.)
Annexe
au-dessus de la ligne de commande utilise [...more Ghostscript options as needed...] comme support de place pour plus d'options.
Si vous n'utilisez pas d'autres options, Ghostscript appliquera ses valeurs par défaut pour les différents paramètres. Cependant, cela peut vous donner des résultats qui peuvent ne pas à votre goût. Puisque Ghostscript génère un PDF entièrement nouveau basé sur l'entrée, cela signifie que certains des objets originaux peuvent être modifiés. Ceci est vrai pour les espaces de couleur et pour niveaux de compression d'image.
Comment appliquer des paramètres qui laissent inchangées les images originellement incrustées peut être vu à Super-Utilisateur: "utilisez Ghostscript, mais dites-lui de ne pas retraiter les images" .
je sais qu'il y a d'autres façons de faire cela déjà mentionné, mais avec pdftk vous pouvez prendre le PDF fusionné et y ajouter des signets en utilisant la fonction PDFTK dump_data pour créer un .fichier d'information des informations existantes dans le pdf. Ensuite, vous pouvez ajouter un signet infos à la .info fichier à ajouter les quatre lignes suivantes pour chaque signet
BookmarkBegin
BookmarkTitle: name
BookmarkLevel: level
BookmarkPageNumber: page number
utilisez ensuite l'appel update_info pour mettre à jour les signets PDF fusionnés avec ceux que vous avez écrits .fichier d'information. J'ai écrit quelques fonctions simples qui font cela pour moi dans autohotkey si quelqu'un est intéressé. Voir http://www.autohotkey.com/board/topic/98985-scripts-to-merge-pdfs-and-add-bookmarks-with-pdftk /
ajoutez ou modifiez aussi les signets pdf que vous pouvez utiliser JPdfBookmarks . C'est un excellent outil de logiciel libre multi-OS que j'utilise depuis un certain temps maintenant avec d'excellents résultats. Il traite avec les signets seulement si, de sorte que vous auriez besoin d'un autre outil pour fusionner ou réorganiser les pages. En plus de pdftk je suggère d'essayer PDF Split et fusionner (bonne application, mais L'UI bizarre, gâche signets de mon expérience), PDF-Shuffler (semble fonctionner bien, mais gèle parfois tout en traitant avec certains fichiers), ou PdfMod (le meilleur potentiellement car il traite de réarrangement, Fusion et traiter avec des signets, bien que je n'ai pas été en mesure de comprendre comment ajouter des fichiers PDF dans une page spécifique).
désolé de ne pas avoir fourni quelques liens, comme un internaute novice le système ne me permet d'ajouter que 2 hyperliens.
voir cette réponse à https://stackoverflow.com/a/17781138/547578 . J'ai utilisé un truc appelé Sejda. Elle fonctionne. Il combine parfaitement les signets. Merci @blablatros.
la bonne réponse de @pipitas ne résout pas les problèmes de marque-page mis au point, et la question est liée dans la discussion unix https://unix.stackexchange.com/questions/17065/add-and-edit-bookmarks-to-pdf/31070 , où je suggère
si vous vous en tenez toujours à ces scripts unix, alors
- extrait de signet de données évaluées à partir d'
pdftk - Ecrivez un script supplémentaire pour convertir dumped les données de marque-page au format pdfmarks, qui ghostscript commande
gsest acceptée. - utiliser
gsscript pour les fusionner avec pdfmarks
le script existe déjà, voir pdf-merge.py de fusionner les PDF avec PDFTK avec des signets?
peut-être que ce qui suit est utile. Je voulais fusionner tous les fichiers PDF (in_nn.pdf) situé dans un répertoire.pdf qui a les noms de pdfs entrants (in_nn) comme ToC. J'ai écrit un script python qui lit les noms et extrait les numéros de page et génère un fichier nommé pdfmarks. La fusion des fichiers se fait alors facilement avec gs. La commande exacte est sortie par le script et doit être exécutée séparément (peut-être avec quelques modifications dues à des adaptations de la taille de la page ou en raison de l'opération système.)
le voilà. Peut-être quelques modifications sont nécessaires pour windows? (désolé pour les commentaires ne sont pas en anglais). Il suffit d'exécuter le script python dans le répertoire où se trouvent les pdfs à fusionner.
#!/usr/bin/env python
import subprocess
# Dieses Skript dient dazu, eine Reihe von pdfs zu einem einzigen pdf zusammenzufassen und bookmarks fuer diese pdf-Datei zu erzeugen.
# Dafuer wird ein Datei pdfmark benoetigt, die mit diesem Skript erzeugt wird.
# Dazu einfach dieses Skript in dem Verzeichnis aufrufen, das genau alle zusammenzufassenden pdfs (*pdf, s.u.) enthaelt.
# Das zusammenfassende pdf wird dann mit diesem Befehl (in der bash) generiert:
# gs -dBATCH -dNOPAUSE -sPAPERSIZE=A4 -sDEVICE=pdfwrite -sOutputFile="all.pdf" $(ls *pdf ) pdfmarks
# Bereits Inhaltsverzeichnisse bleiben erhalten, die neuen kommen ans Ende des Inhaltsverzeichnisses.
#
# pdfmarks sieht dabei prinzipiell so aus:
#
# [/Title (Nr. 1) /Page 1 /OUT pdfmark
# [/Title (Nr. 2) /Page 5 /OUT pdfmark
# [/Title (Nr. 3) /Page 9 /OUT pdfmark
# usw.
p = subprocess.Popen('ls *pdf', shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
pdfdateien = []
kombinationen = []
for line in p.stdout.readlines():
# p enthaelt alle pdf-Dateinamen
pdfdateien.append(line)
for datei in pdfdateien:
cmd = "pdfinfo %s" %datei
q=subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
kombination = [datei]
for line in p.stdout.readlines():
# p enthaelt alle pdf-Dateinamen
pdfdateien.append(line)
for datei in pdfdateien:
cmd = "pdfinfo %s" %datei
q=subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
kombination = [datei]
for subline in q.stdout.readlines():
# q enthaelt die Zeilen von pdfinfo
if "Pages" in subline:
kombination.append(subline)
kombinationen.append(kombination)
# Jetzt kombinationen in benoetigtes Format bringen:
kombinationen_bereinigt = []
out_string1 = "[/Title ("
out_string2 = ") /Page "
out_string3 = " /OUT pdfmark\n"
seitenzahl = 1
for kombination in kombinationen:
dateiname = kombination[0][0:len(kombination[0])-5]
#
# Hier noch dateiname evtl. verwursten
# z. B.
# lesezeichen = dateiname[0:1]+" "+dateiname[6:8]+"/"+dateiname[1:5]
lesezeichen = dateiname
anz_seiten = kombination[1][16:len(kombination[1])-1]
seitenzahl_str = str(seitenzahl)
kombination_bereinigt = out_string1+lesezeichen+out_string2+seitenzahl_str+out_string3
kombinationen_bereinigt.append(kombination_bereinigt)
seitenzahl += int(anz_seiten)
# Ausgabe ins file
outfile = open("pdfmarks", "w")
for i in kombinationen_bereinigt:
outfile.write(i)
outfile.close()
# Merge-Befehl absetzen
print "\nFor merging all pdfs execute this (or similar) command (in bash shell):"
print "gs -dBATCH -dNOPAUSE -sPAPERSIZE=A4 -sDEVICE=pdfwrite -sOutputFile=\"all.pdf\" $(ls *pdf ) pdfmarks\n"
Malheureusement, il n'existe pas de moyen facile de le faire. Vous pouvez utiliser la bibliothèque sur laquelle pdftk est construit directement et soit écrire un programme Java ou un .NET qui utilise iText ou iTextSharp pour fusionner vos mono-pagers et créer les signets. Si vous voulez suivre la voie iText, il y a beaucoup d'exemples disponibles en ligne ou dans le livre iText (écrit par l'auteur iText).
... ou, dites-moi ce qui ne fonctionne pas et je peux vous aider.
ce qui suit est destiné à être un commentaire à la réponse de pdfmerger ( https://stackoverflow.com/a/30524828/3915004 ).
Merci pour votre script pdfmerger! Je sais que la question est marquée linux, mais pour généraliser votre script pour Mac OS X, 2 choses sont nécessaires:
- ghostscript
gset - la commande
pdfinfo(qui est incluse par exemple danspoppler)
installez-les en obtenant d'abord brew (google it, il est installé via certains curl / ruby-magic commande ^^) et puis tout simplement:
brew install ghostscript
brew install poppler
ADD - ON: READ TEXT-FILE WITH CHAPTER TITLES:
pour développer votre script. J'utilise ce flux de travail principalement pour les livres disponibles en téléchargement de chapitre sur le site des éditeurs. Un fichier texte contenant les noms de chapitre peut facilement être générer. L'add-on suivant à votre code lit en outre un textfile 'chapitres.txt ' contenant une ligne par pdf à fusionner. (Note, je n'ai pas mis en place de contrôle sur le nombre de lignes correspondant au nombre de PDF.)
développez simplement votre script en remplaçant les lignes suivantes:
p = subprocess.Popen('ls *pdf', shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
c = subprocess.Popen('less chapters.txt', shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
pdfdateien = []
kombinationen = []
chapternames = []
for line in c.stdout.readlines():
# c contains all chapter-titles
chapternames.append(line)
for line in p.stdout.readlines():
et
for index, kombination in enumerate(kombinationen):
# dateiname = kombination[0][0:len(kombination[0])-5]
#
# Hier noch dateiname evtl. verwursten
# z. B.
# lesezeichen = dateiname[0:1]+" "+dateiname[6:8]+"/"+dateiname[1:5]
# lesezeichen = dateiname
lesezeichen=chapternames[index][:-1]
anz_seiten = kombination[1][16:len(kombination[1])-1]
SEJDA PDF (qui a été suggéré dans l'une des réponses ) est également disponible comme un service en ligne: https://www.sejda.com/merge-pdf .
cela peut s'avérer pratique si vous ne voulez pas installer de logiciel supplémentaire et préférez travailler en ligne à partir d'un navigateur.
Mesures visant à fusionner:
- faire glisser et déposer tous les fichiers PDF sur la page web
-
par défaut tous les signets existants sont préservés et fonctionneront aussi dans le document fusionné .
-
Éventuellement, de l'outil de fusion de créer une table des matières basée sur les documents PDF combiné

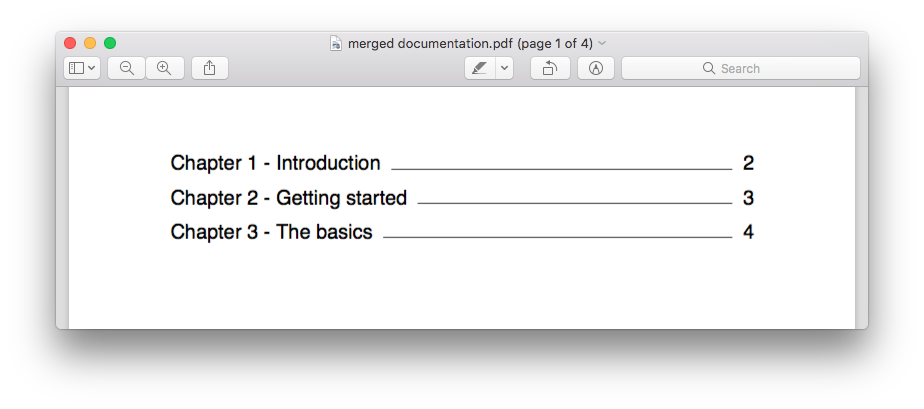
le service en ligne pour fusionner des fichiers PDF est libre d'utiliser jusqu'à 30 fichiers par heure et des fichiers jusqu'à 50Mb/200 pages.
avertissement: je suis un dev open source travaillant sur Sejda.