Fusionner les DataFrames de pandas où une valeur se situe entre deux autres [dupliquer]
cette question a déjà une réponse ici:
je dois fusionner deux DataFrames pandas sur un identifiant et une condition où une date dans une dataframe est entre deux dates dans les autres dataframe.
Dataframe a a une date ("fdate") et un ID ("cusip"):
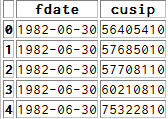
je dois fusionner avec ce dataframe B:
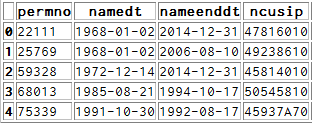
sur A.cusip==B.ncusip et A.fdate se situe entre B.namedt et B.nameenddt .
en SQL ce serait trivial, mais le seul moyen que je peux voir comment faire cela en pandas doit d'abord fusionner inconditionnellement sur l'Identifiant, puis filtrer sur la condition date:
df = pd.merge(A, B, how='inner', left_on='cusip', right_on='ncusip')
df = df[(df['fdate']>=df['namedt']) & (df['fdate']<=df['nameenddt'])]
Est-ce vraiment la meilleure façon de le faire? Il semble que ce serait beaucoup mieux si l'on pouvait filtrer à l'intérieur de la fusion afin d'éviter d'avoir une base de données potentiellement très grande après la fusion mais avant que le filtre ait terminé.
4 réponses
comme vous dites, c'est assez facile en SQL, alors pourquoi ne pas le faire en SQL?
import pandas as pd
import sqlite3
#We'll use firelynx's tables:
presidents = pd.DataFrame({"name": ["Bush", "Obama", "Trump"],
"president_id":[43, 44, 45]})
terms = pd.DataFrame({'start_date': pd.date_range('2001-01-20', periods=5, freq='48M'),
'end_date': pd.date_range('2005-01-21', periods=5, freq='48M'),
'president_id': [43, 43, 44, 44, 45]})
war_declarations = pd.DataFrame({"date": [datetime(2001, 9, 14), datetime(2003, 3, 3)],
"name": ["War in Afghanistan", "Iraq War"]})
#Make the db in memory
conn = sqlite3.connect(':memory:')
#write the tables
terms.to_sql('terms', conn, index=False)
presidents.to_sql('presidents', conn, index=False)
war_declarations.to_sql('wars', conn, index=False)
qry = '''
select
start_date PresTermStart,
end_date PresTermEnd,
wars.date WarStart,
presidents.name Pres
from
terms join wars on
date between start_date and end_date join presidents on
terms.president_id = presidents.president_id
'''
df = pd.read_sql_query(qry, conn)
df:
PresTermStart PresTermEnd WarStart Pres
0 2001-01-31 00:00:00 2005-01-31 00:00:00 2001-09-14 00:00:00 Bush
1 2001-01-31 00:00:00 2005-01-31 00:00:00 2003-03-03 00:00:00 Bush
vous devriez pouvoir le faire maintenant en utilisant le paquet pandasql
import pandasql as ps
sqlcode = '''
select A.cusip
from A
inner join B on A.cusip=B.ncusip
where A.fdate >= B.namedt and A.fdate <= B.nameenddt
group by A.cusip
'''
newdf = ps.sqldf(sqlcode,locals())
je pense que la réponse de @ChuHo est bonne. Je crois que pandasql fait la même chose pour vous. Je n'ai pas comparé les deux, mais c'est plus facile à lire.
il n'y a pas de façon pandamique de le faire pour le moment.
cette réponse avait pour but de s'attaquer au problème du polymorphisme, qui s'est avéré être une très mauvaise idée .
puis la fonction numpy.piecewise apparaît dans une autre réponse, mais avec peu d'explications, donc j'ai pensé que je voudrais clarifier comment cette fonction peut être utilisée.
Numpy way avec piecewise (Mémoire lourde)
la fonction np.piecewise peut être utilisée pour générer le comportement d'une jointure personnalisée. Il ya beaucoup de frais généraux impliqués et il n'est pas très efficace en soi, mais il fait le travail.
conditions de production pour l'assemblage
import pandas as pd
from datetime import datetime
presidents = pd.DataFrame({"name": ["Bush", "Obama", "Trump"],
"president_id":[43, 44, 45]})
terms = pd.DataFrame({'start_date': pd.date_range('2001-01-20', periods=5, freq='48M'),
'end_date': pd.date_range('2005-01-21', periods=5, freq='48M'),
'president_id': [43, 43, 44, 44, 45]})
war_declarations = pd.DataFrame({"date": [datetime(2001, 9, 14), datetime(2003, 3, 3)],
"name": ["War in Afghanistan", "Iraq War"]})
start_end_date_tuples = zip(terms.start_date.values, terms.end_date.values)
conditions = [(war_declarations.date.values >= start_date) &
(war_declarations.date.values <= end_date) for start_date, end_date in start_end_date_tuples]
> conditions
[array([ True, True], dtype=bool),
array([False, False], dtype=bool),
array([False, False], dtype=bool),
array([False, False], dtype=bool),
array([False, False], dtype=bool)]
C'est une liste de tableaux où chaque tableau nous indique si le terme laps de temps correspondant pour chacune des deux déclarations de guerre que nous avons. le les conditions peuvent exploser avec des ensembles de données plus grands comme il sera la longueur du df gauche et le DF droit multiplié.
par morceaux "magie"
maintenant par morceaux prendra le president_id des Termes et le placera dans le war_declarations dataframe pour chacune des guerres correspondantes.
war_declarations['president_id'] = np.piecewise(np.zeros(len(war_declarations)),
conditions,
terms.president_id.values)
date name president_id
0 2001-09-14 War in Afghanistan 43.0
1 2003-03-03 Iraq War 43.0
maintenant, pour finir cet exemple, nous avons juste besoin de fusionner régulièrement au nom des Présidents.
war_declarations.merge(presidents, on="president_id", suffixes=["_war", "_president"])
date name_war president_id name_president
0 2001-09-14 War in Afghanistan 43.0 Bush
1 2003-03-03 Iraq War 43.0 Bush
polymorphisme (ne fonctionne pas)
j'ai voulu partager mes efforts de recherche, donc même si ce ne résout pas le problème , j'espère qu'il sera permis de vivre sur ici comme une réponse utile au moins. Comme il est difficile de repérer l'erreur, quelqu'un d'autre peut essayer et penser qu'il a une solution qui fonctionne, alors qu'en fait, il ne le fait pas.
le seul autre moyen que j'ai pu trouver est de créer deux nouvelles classes, une PointInTime et une durée
tous les deux devraient avoir des méthodes __eq__ où ils renvoient true si un Pointtintime est comparé à un temps qui le contient.
après cela, vous pouvez remplir votre DataFrame avec ces objets, et rejoindre sur les colonnes dans lesquelles ils vivent.
quelque chose comme ça:
class PointInTime(object):
def __init__(self, year, month, day):
self.dt = datetime(year, month, day)
def __eq__(self, other):
return other.start_date < self.dt < other.end_date
def __ne__(self, other):
return not self.__eq__(other)
def __repr__(self):
return "{}-{}-{}".format(self.dt.year, self.dt.month, self.dt.day)
class Timespan(object):
def __init__(self, start_date, end_date):
self.start_date = start_date
self.end_date = end_date
def __eq__(self, other):
return self.start_date < other.dt < self.end_date
def __ne__(self, other):
return not self.__eq__(other)
def __repr__(self):
return "{}-{}-{} -> {}-{}-{}".format(self.start_date.year, self.start_date.month, self.start_date.day,
self.end_date.year, self.end_date.month, self.end_date.day)
Note importante: Je ne Classe pas datetime parce que pandas considérez le dtype de la colonne des objets datetime comme un dtype datetime, et puisque le timespan ne l'est pas, pandas refuse silencieusement de fusionner sur eux.
si nous instancions deux objets de ces classes, ils peuvent maintenant être comparés:
pit = PointInTime(2015,1,1)
ts = Timespan(datetime(2014,1,1), datetime(2015,2,2))
pit == ts
True
nous pouvons également remplir deux images de données avec ces objets:
df = pd.DataFrame({"pit":[PointInTime(2015,1,1), PointInTime(2015,2,2), PointInTime(2015,3,3)]})
df2 = pd.DataFrame({"ts":[Timespan(datetime(2015,2,1), datetime(2015,2,5)), Timespan(datetime(2015,2,1), datetime(2015,4,1))]})
et puis le genre de fusion des œuvres:
pd.merge(left=df, left_on='pit', right=df2, right_on='ts')
pit ts
0 2015-2-2 2015-2-1 -> 2015-2-5
1 2015-2-2 2015-2-1 -> 2015-4-1
mais seulement en quelque sorte.
PointInTime(2015,3,3) aurait également dû être inclus dans cette rubrique sur Timespan(datetime(2015,2,1), datetime(2015,4,1))
mais ce n'est pas le cas.
I figure pandas compare PointInTime(2015,3,3) à PointInTime(2015,2,2) et fait l'hypothèse que puisqu'ils ne sont pas égaux, PointInTime(2015,3,3) ne peut pas être égal à Timespan(datetime(2015,2,1), datetime(2015,4,1)) , puisque cette période était égale à PointInTime(2015,2,2)
en quelque sorte:
Rose == Flower
Lilly != Rose
donc:
Lilly != Flower
Edit:
j'ai essayé de rendre tous les Pointsintime égaux les uns aux autres, cela a changé le comportement de la jointure pour inclure le 2015-3-3, mais le 2015-2-2 n'a été inclus que pour la durée 2015-2-1 -> 2015-2-5, donc cela renforce mon hypothèse ci-dessus.
Si quelqu'un a d'autres idées, s'il vous plaît commentaire et je peux l'essayer.
une solution pandas serait grande si elle était implémentée de la même manière que foverlaps() à partir de données.table package in R. jusqu'à présent, j'ai trouvé que les morceaux de numpy() sont efficaces. J'ai fourni le code basé sur une discussion antérieure fusion des dataframes basé sur la gamme de date
A['permno'] = np.piecewise(np.zeros(A.count()[0]),
[ (A['cusip'].values == id) & (A['fdate'].values >= start) & (A['fdate'].values <= end) for id, start, end in zip(B['ncusip'].values, B['namedf'].values, B['nameenddt'].values)],
B['permno'].values).astype(int)