Matplotlib chevauchement des annotations
je veux annoter les barres dans un graphique avec du texte mais si les barres sont rapprochées et ont une hauteur comparable, les annotations sont au-dessus de ea. autre et donc difficile à lire (les coordonnées pour les annotations ont été prises de la position de la barre et de la hauteur).
y a-t-il un moyen d'en déplacer un en cas de collision?
Edit: les barres sont très minces et très proches parfois donc juste s'aligner verticalement ne résout pas le problème...
une image pourrait clarifier les choses:
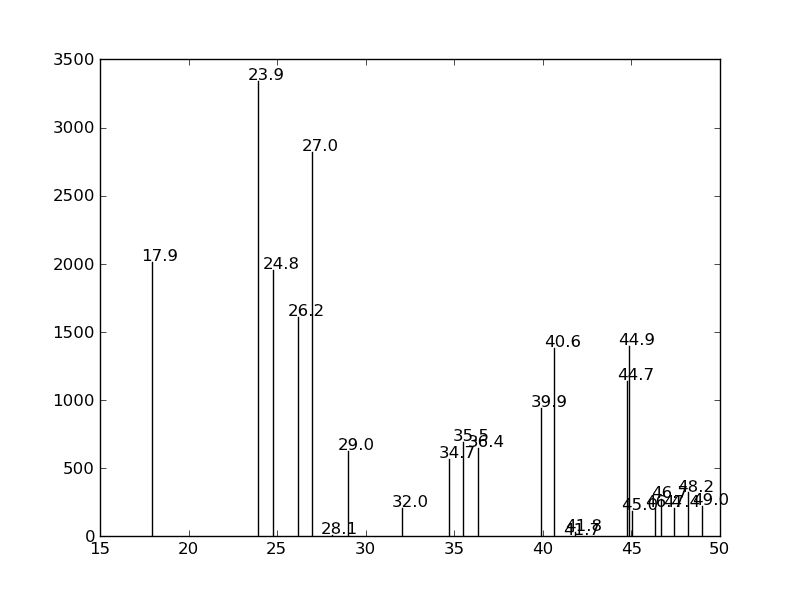
3 réponses
j'ai écrit une solution rapide, qui vérifie chaque position d'annotation contre les boîtes de limites par défaut pour toutes les autres annotations. S'il y a une collision, elle change de position pour la place libre suivante. Il met aussi de belles flèches.
pour un exemple assez extrême, il produira ceci (aucun des nombres ne se chevauchent)):
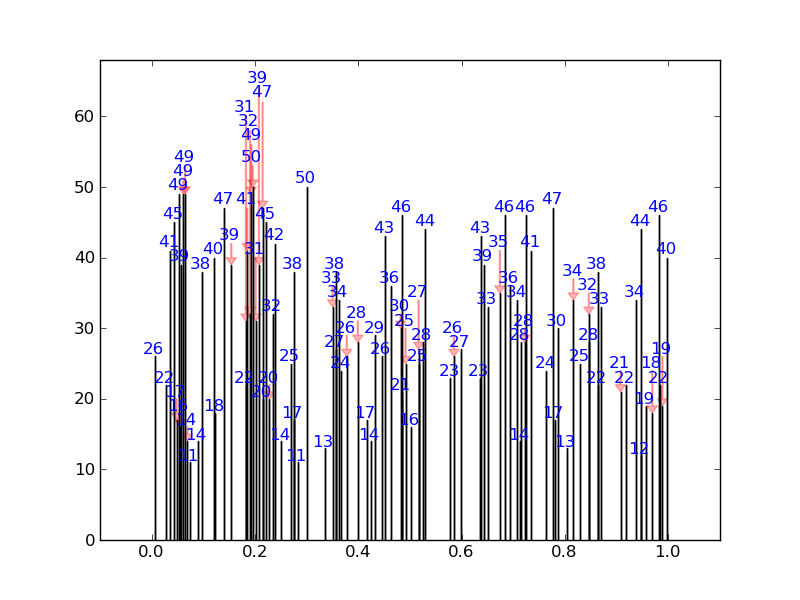
au lieu de ceci:
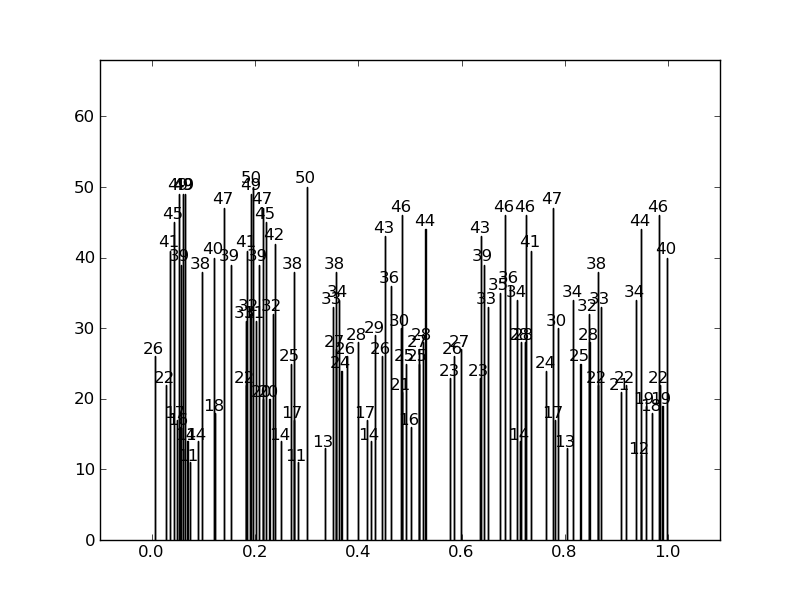
voici le code:
import numpy as np
import matplotlib.pyplot as plt
from numpy.random import *
def get_text_positions(x_data, y_data, txt_width, txt_height):
a = zip(y_data, x_data)
text_positions = y_data.copy()
for index, (y, x) in enumerate(a):
local_text_positions = [i for i in a if i[0] > (y - txt_height)
and (abs(i[1] - x) < txt_width * 2) and i != (y,x)]
if local_text_positions:
sorted_ltp = sorted(local_text_positions)
if abs(sorted_ltp[0][0] - y) < txt_height: #True == collision
differ = np.diff(sorted_ltp, axis=0)
a[index] = (sorted_ltp[-1][0] + txt_height, a[index][1])
text_positions[index] = sorted_ltp[-1][0] + txt_height
for k, (j, m) in enumerate(differ):
#j is the vertical distance between words
if j > txt_height * 2: #if True then room to fit a word in
a[index] = (sorted_ltp[k][0] + txt_height, a[index][1])
text_positions[index] = sorted_ltp[k][0] + txt_height
break
return text_positions
def text_plotter(x_data, y_data, text_positions, axis,txt_width,txt_height):
for x,y,t in zip(x_data, y_data, text_positions):
axis.text(x - txt_width, 1.01*t, '%d'%int(y),rotation=0, color='blue')
if y != t:
axis.arrow(x, t,0,y-t, color='red',alpha=0.3, width=txt_width*0.1,
head_width=txt_width, head_length=txt_height*0.5,
zorder=0,length_includes_head=True)
voici le code de production de ces parcelles, montrant l'utilisation:
#random test data:
x_data = random_sample(100)
y_data = random_integers(10,50,(100))
#GOOD PLOT:
fig2 = plt.figure()
ax2 = fig2.add_subplot(111)
ax2.bar(x_data, y_data,width=0.00001)
#set the bbox for the text. Increase txt_width for wider text.
txt_height = 0.04*(plt.ylim()[1] - plt.ylim()[0])
txt_width = 0.02*(plt.xlim()[1] - plt.xlim()[0])
#Get the corrected text positions, then write the text.
text_positions = get_text_positions(x_data, y_data, txt_width, txt_height)
text_plotter(x_data, y_data, text_positions, ax2, txt_width, txt_height)
plt.ylim(0,max(text_positions)+2*txt_height)
plt.xlim(-0.1,1.1)
#BAD PLOT:
fig = plt.figure()
ax = fig.add_subplot(111)
ax.bar(x_data, y_data, width=0.0001)
#write the text:
for x,y in zip(x_data, y_data):
ax.text(x - txt_width, 1.01*y, '%d'%int(y),rotation=0)
plt.ylim(0,max(text_positions)+2*txt_height)
plt.xlim(-0.1,1.1)
plt.show()
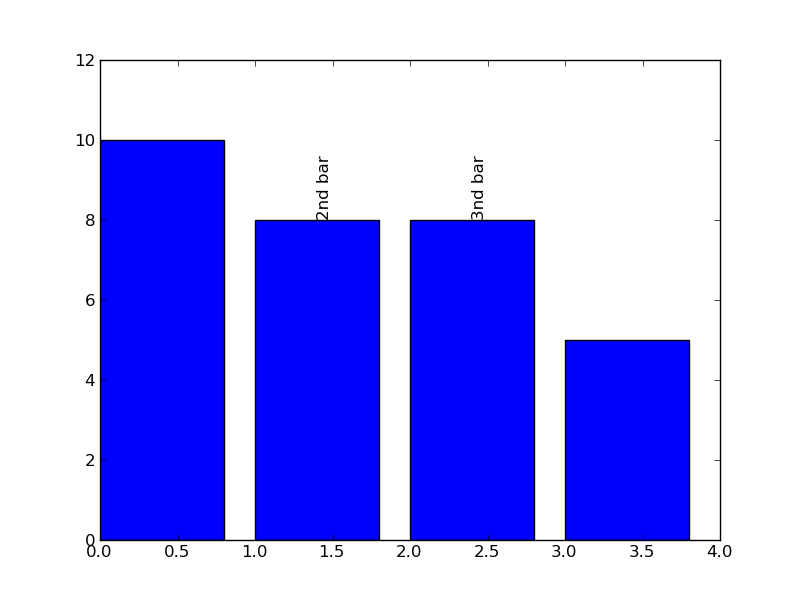
une option est de faire tourner le texte/annotation, qui est défini par le mot-clé/propriété rotation . Dans l'exemple suivant, je tourne le texte de 90 degrés pour garantir qu'il ne entrera pas en collision avec le texte voisin. J'ai aussi placé le mot-clé va (abréviation de verticalalignment ), de sorte que le texte est présenté au-dessus de la barre (au-dessus du point que j'utilise pour définir le texte):
import matplotlib.pyplot as plt
data = [10, 8, 8, 5]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.bar(range(4),data)
ax.set_ylim(0,12)
# extra .4 is because it's half the default width (.8):
ax.text(1.4,8,"2nd bar",rotation=90,va='bottom')
ax.text(2.4,8,"3nd bar",rotation=90,va='bottom')
plt.show()
le résultat est le chiffre suivant:
déterminer par programmation s'il y a des collisions entre diverses annotations est un processus plus délicat. Cela pourrait valoir la peine d'une question séparée: Matplotlib text dimensions .
une autre option utilisant Ma bibliothèque adjustText , écrite spécialement à cet effet ( https://github.com/Phlya/adjustText ). Je pense qu'il est probablement beaucoup plus lent que la réponse acceptée (il ralentit considérablement avec beaucoup de barres), mais beaucoup plus générale et configurable.
from adjustText import adjust_text
np.random.seed(2017)
x_data = np.random.random_sample(100)
y_data = np.random.random_integers(10,50,(100))
f, ax = plt.subplots(dpi=300)
bars = ax.bar(x_data, y_data, width=0.001, facecolor='k')
texts = []
for x, y in zip(x_data, y_data):
texts.append(plt.text(x, y, y, horizontalalignment='center', color='b'))
adjust_text(texts, add_objects=bars, autoalign='y', expand_objects=(0.1, 1),
only_move={'points':'', 'text':'y', 'objects':'y'}, force_text=0.75, force_objects=0.1,
arrowprops=dict(arrowstyle="simple, head_width=0.25, tail_width=0.05", color='r', lw=0.5, alpha=0.5))
plt.show()
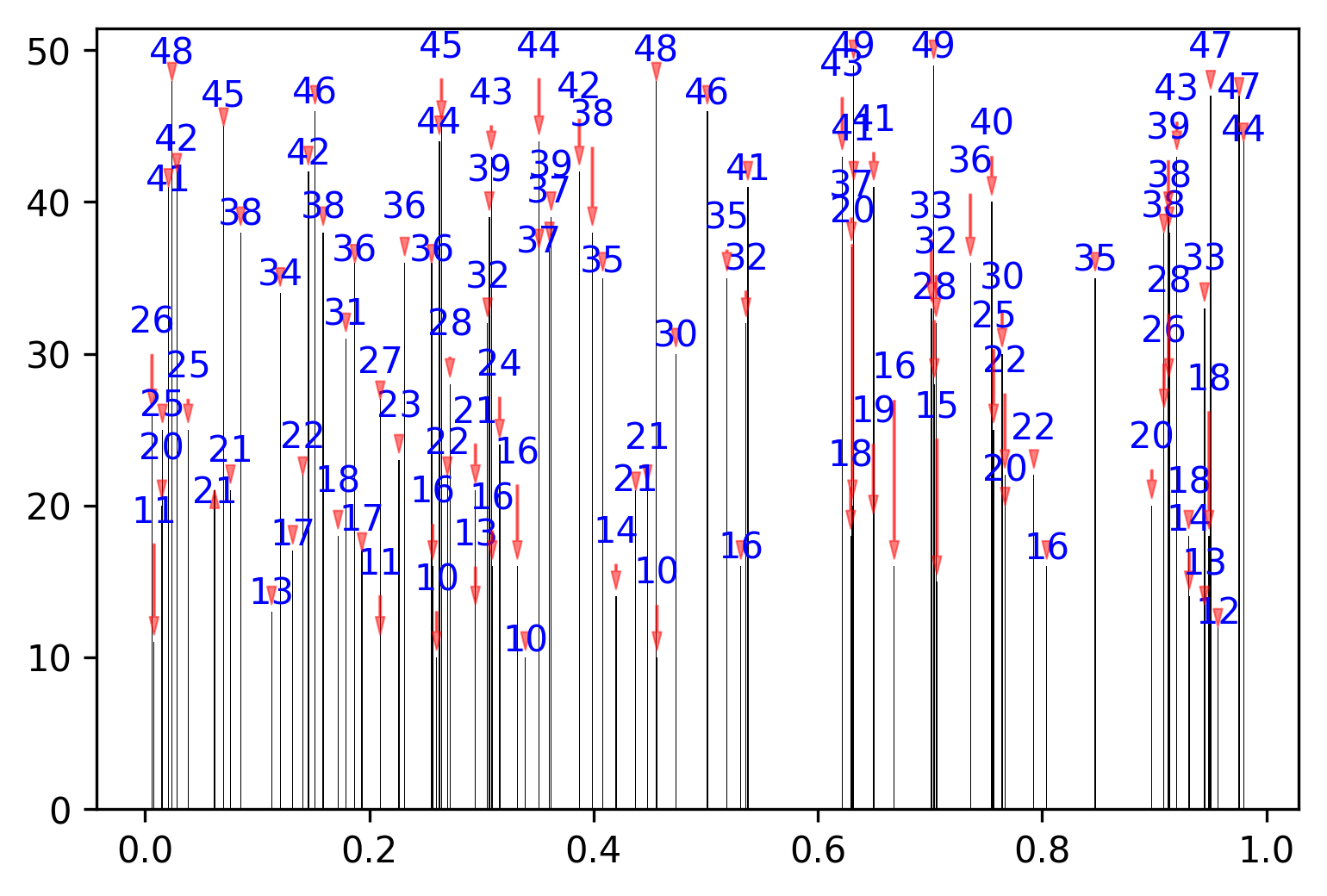
si nous permettons l'autoalignement le long de l'axe x, il obtient même meilleur (j'ai juste besoin de résoudre un petit problème qu'il n'aime pas mettre des étiquettes au-dessus de la points et pas un peu sur le côté...).
np.random.seed(2017)
x_data = np.random.random_sample(100)
y_data = np.random.random_integers(10,50,(100))
f, ax = plt.subplots(dpi=300)
bars = ax.bar(x_data, y_data, width=0.001, facecolor='k')
texts = []
for x, y in zip(x_data, y_data):
texts.append(plt.text(x, y, y, horizontalalignment='center', size=7, color='b'))
adjust_text(texts, add_objects=bars, autoalign='xy', expand_objects=(0.1, 1),
only_move={'points':'', 'text':'y', 'objects':'y'}, force_text=0.75, force_objects=0.1,
arrowprops=dict(arrowstyle="simple, head_width=0.25, tail_width=0.05", color='r', lw=0.5, alpha=0.5))
plt.show()
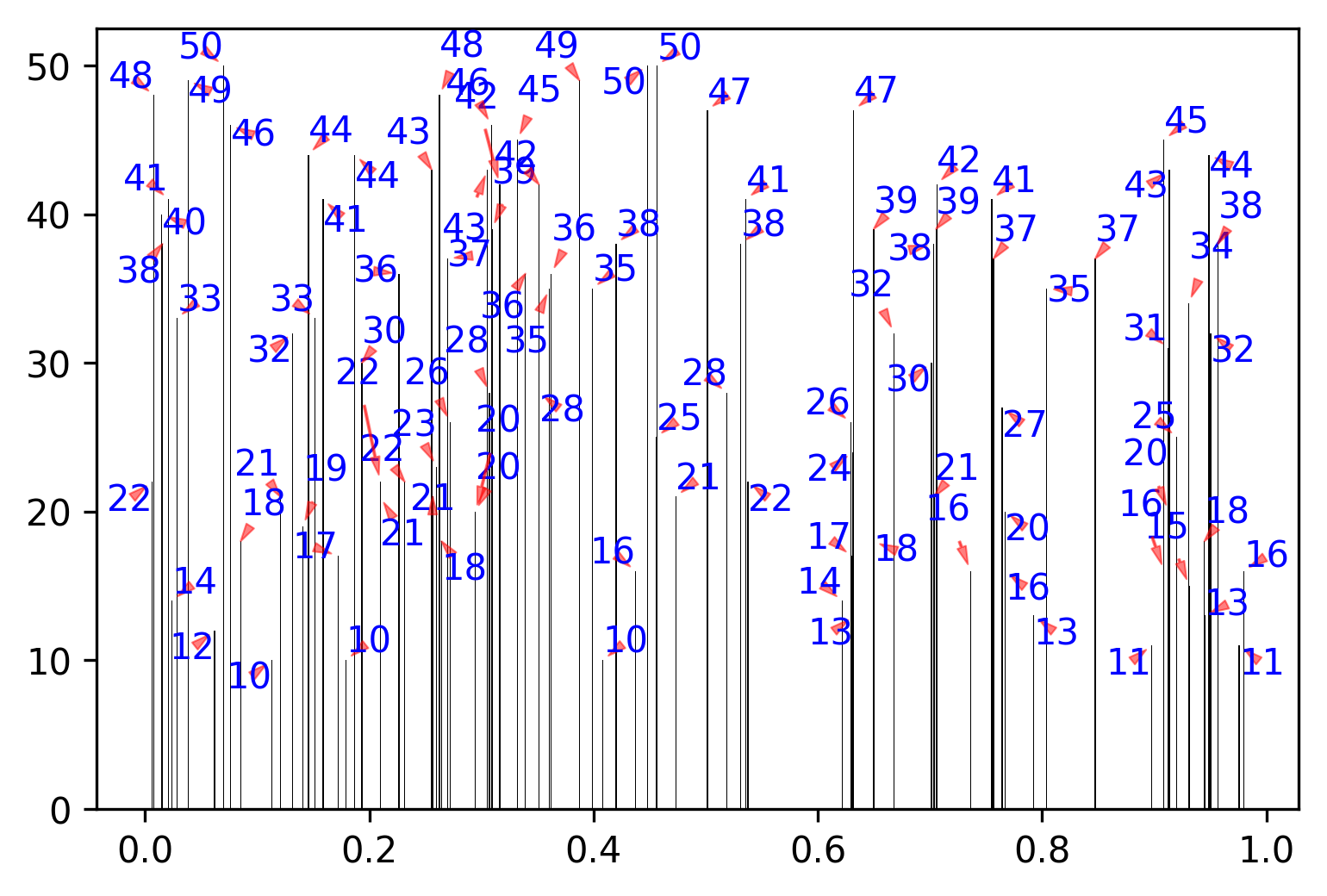
(j'ai dû ajuster certains paramètres ici, bien sûr)