Analyse Matlab-PCA et reconstruction de données multidimensionnelles
j'ai un grand ensemble de données multidimensionnelles(132 dimensions).
je suis un débutant dans l'exploration de données et je veux appliquer L'analyse des composants principaux en utilisant Matlab. Cependant, j'ai vu qu'il y a beaucoup de fonctions expliquées sur le web, mais je ne comprends pas comment elles devraient être appliquées.
fondamentalement, je veux appliquer PCA et obtenir les vecteurs propres et leurs valeurs propres correspondantes à partir de mes données.
après cette étape I voulez être en mesure de faire une reconstruction de mes données basée sur une sélection des vecteurs propres obtenus.
je peux le faire manuellement, mais je me demandais s'il y avait des fonctions prédéfinies qui pourraient le faire parce qu'elles devraient déjà être optimisées.
Mon initiale des données est quelque chose comme : size(x) = [33800 132]. Donc en gros j'ai 132 caractéristiques(dimensions) et 33800 points de données. Et je veux effectuer PCA sur cet ensemble de données.
toute aide ou allusion ferait l'affaire.
2 réponses
voici un aperçu rapide. D'abord, nous créons une matrice de vos variables cachées (ou "facteurs"). Il compte 100 observations et il y a deux facteurs indépendants.
>> factors = randn(100, 2);
maintenant créer une matrice de charges. Cela va cartographier les variables cachées sur vos variables observées. Dire vos variables observées ont quatre caractéristiques. Alors votre matrice de charge doit être 4 x 2
>> loadings = [
1 0
0 1
1 1
1 -1 ];
cela vous indique que la première variable observée charge sur la première facteur, la seconde charge sur le deuxième facteur, la troisième variable de charges sur la somme des facteurs et la quatrième charges variables sur la différence des facteurs.
maintenant, Créez vos observations:
>> observations = factors * loadings' + 0.1 * randn(100,4);
j'ai ajouté une petite quantité de bruit aléatoire pour simuler l'erreur expérimentale. Maintenant nous effectuons L'ACP en utilisant le pca fonction à partir de la boîte à outils de stats:
>> [coeff, score, latent, tsquared, explained, mu] = pca(observations);
la variable score est le tableau des scores des composantes principales. Ils seront orthogonale par construction, que vous pouvez vérifier -
>> corr(score)
ans =
1.0000 0.0000 0.0000 0.0000
0.0000 1.0000 0.0000 0.0000
0.0000 0.0000 1.0000 0.0000
0.0000 0.0000 0.0000 1.0000
La combinaison score * coeff' reproduira la version centrée de vos observations. La moyenne mu est soustrait avant d'effectuer L'ACP. Pour reproduire vos observations originales, vous devez l'ajouter de nouveau dans,
>> reconstructed = score * coeff' + repmat(mu, 100, 1);
>> sum((observations - reconstructed).^2)
ans =
1.0e-27 *
0.0311 0.0104 0.0440 0.3378
pour obtenir une approximation de vos données originales, vous pouvez commencer à supprimer des colonnes à partir des composants principaux calculés. Pour avoir une idée des colonnes à laisser tomber, nous examinons le explained variable
>> explained
explained =
58.0639
41.6302
0.1693
0.1366
les entrées vous indiquent quel pourcentage de la variance est expliqué par chacune des composantes principales. On voit clairement que les deux premières composantes sont plus significatives que les deux autres (elles expliquent plus de 99% de la variance entre elles). L'utilisation des deux premières composantes pour reconstruire les observations donne l'approximation rank-2,
>> approximationRank2 = score(:,1:2) * coeff(:,1:2)' + repmat(mu, 100, 1);
Nous pouvons maintenant essayer traçage:
>> for k = 1:4
subplot(2, 2, k);
hold on;
grid on
plot(approximationRank2(:, k), observations(:, k), 'x');
plot([-4 4], [-4 4]);
xlim([-4 4]);
ylim([-4 4]);
title(sprintf('Variable %d', k));
end
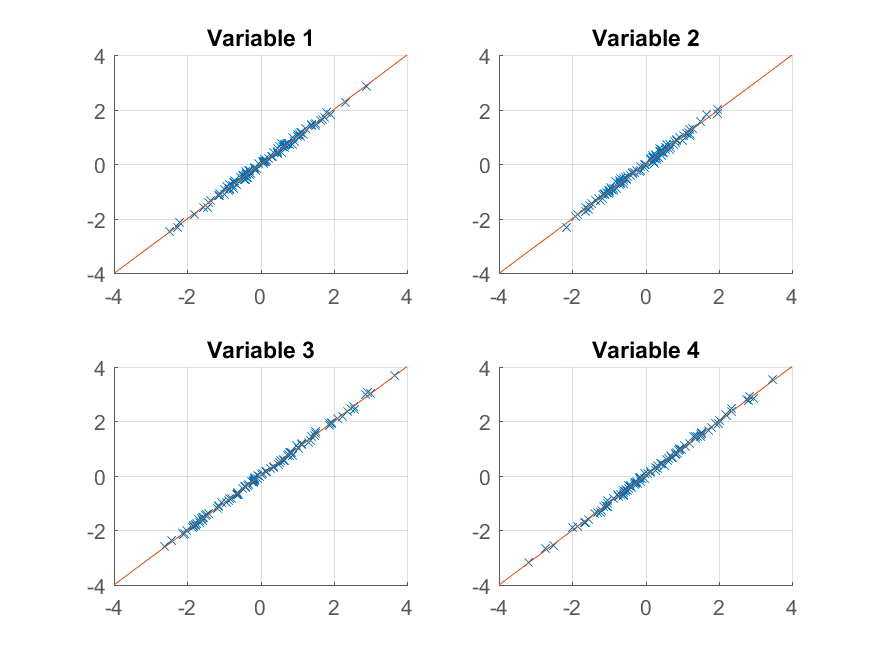
nous obtenons une reproduction presque parfaite des observations originales. Si nous voulions une approximation plus grossière, nous pourrions simplement utiliser le premier composant principal:
>> approximationRank1 = score(:,1) * coeff(:,1)' + repmat(mu, 100, 1);
et de l'intrigue,
>> for k = 1:4
subplot(2, 2, k);
hold on;
grid on
plot(approximationRank1(:, k), observations(:, k), 'x');
plot([-4 4], [-4 4]);
xlim([-4 4]);
ylim([-4 4]);
title(sprintf('Variable %d', k));
end
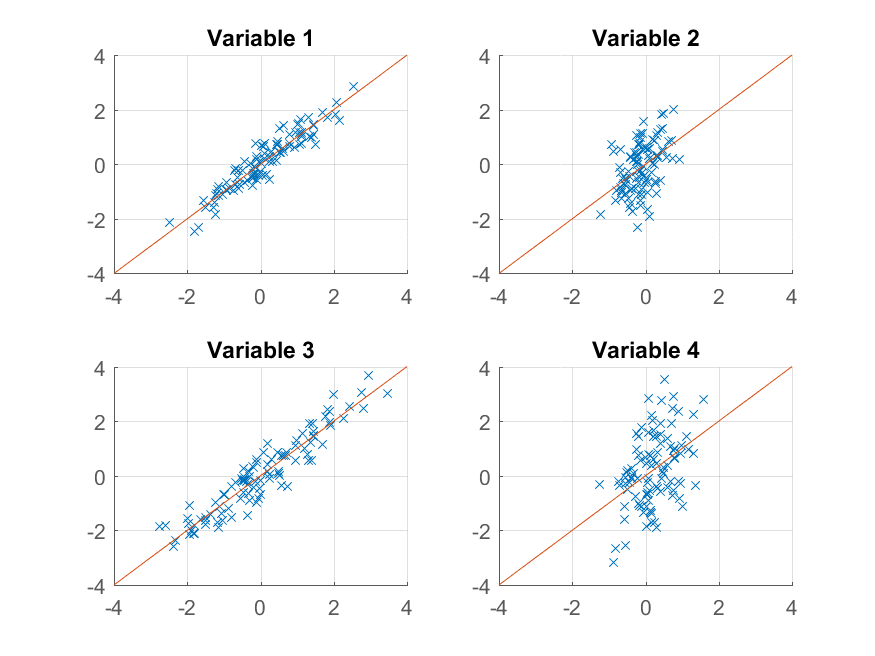
Cette fois, la reconstruction n'est pas si bon. C'est parce que nous avons délibérément construit nos données à deux facteurs, et on ne la reconstruit qu'à partir de l'un d'eux.
notez que malgré la similarité suggestive entre la façon dont nous avons construit les données originales et leur reproduction,
>> observations = factors * loadings' + 0.1 * randn(100,4);
>> reconstructed = score * coeff' + repmat(mu, 100, 1);
il n'y a pas nécessairement de correspondance entre factors et score, ou entre loadings et coeff. L'algorithme PCA ne sait rien sur la façon dont vos données sont construites - il essaie simplement d'expliquer autant de la variance totale qu'il peut avec chaque successive composant.
L'utilisateur @Mari a demandé dans les commentaires comment elle pouvait tracer l'erreur de reconstruction en fonction du nombre de composants principaux. À l'aide de la variable explained au-dessus c'est assez facile. Je vais générer quelques données avec une structure de facteurs plus intéressante pour illustrer l'effet -
>> factors = randn(100, 20);
>> loadings = chol(corr(factors * triu(ones(20))))';
>> observations = factors * loadings' + 0.1 * randn(100, 20);
maintenant, toutes les observations se chargent sur un facteur commun significatif, avec d'autres facteurs d'importance décroissante. Nous pouvons obtenir la décomposition PCA comme avant
>> [coeff, score, latent, tsquared, explained, mu] = pca(observations);
et tracer le pourcentage de la variance expliquée comme suit,
>> cumexplained = cumsum(explained);
cumunexplained = 100 - cumexplained;
plot(1:20, cumunexplained, 'x-');
grid on;
xlabel('Number of factors');
ylabel('Unexplained variance')
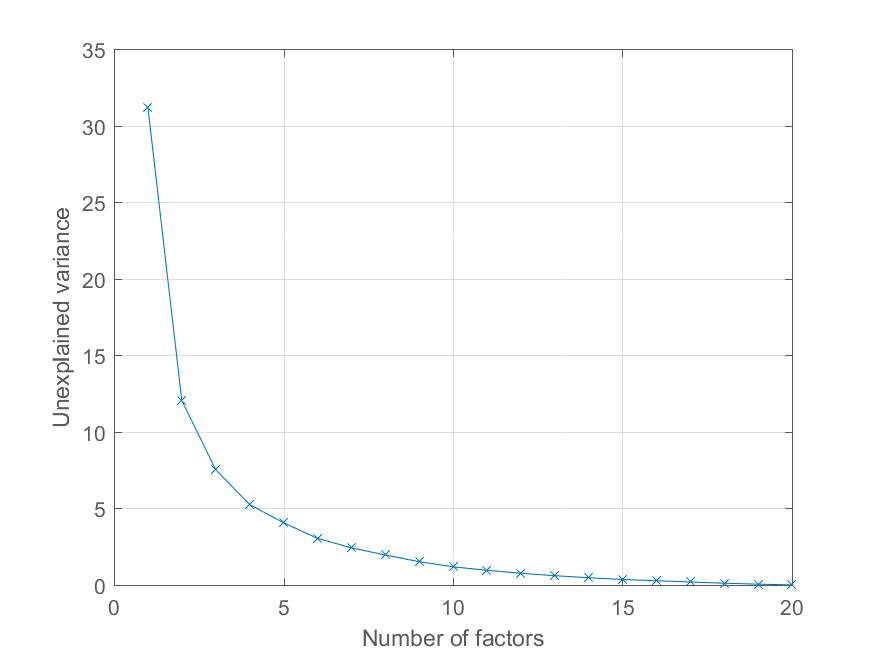
Vous avez une très bonne boîte à outils de réduction de la dimensionnalité à http://homepage.tudelft.nl/19j49/Matlab_Toolbox_for_Dimensionality_Reduction.html Outre PCA, cette boîte à outils a beaucoup d'autres algorithmes pour la réduction de la dimensionnalité.
Exemple de faire de l'APC:
Reduced = compute_mapping(Features, 'PCA', NumberOfDimension);