Markov processus de décision: valeur itération, comment cela fonctionne-t-il?
j'ai beaucoup lu à propos deProcessus de Décision de Markov (à l'aide de la valeur de l'itération) dernièrement, mais je ne peux pas obtenir ma tête autour d'eux. J'ai trouvé beaucoup de ressources sur Internet / Livres, mais ils utilisent tous des formules mathématiques qui sont beaucoup trop complexes pour mes compétences.
depuis que c'est ma première année à l'Université, j'ai trouvé que les explications et les formules fournies sur le web utilisent des notions / termes qui sont beaucoup trop compliquées pour moi et ils supposent que le lecteur sait des choses dont je n'ai jamais entendu parler.
je veux l'utiliser sur une grille 2D (remplie de murs(inaccessible), de pièces(désirable) et d'ennemis qui se déplacent(ce qui doit être évité à tout prix)). Le but est de collecter toutes les pièces sans toucher les ennemis, et je veux créer une IA pour le joueur principal en utilisant un processus de décision Markov (MDP). Voici comment il ressemble en partie (notez que l'aspect lié au jeu n'est pas tellement une préoccupation ici. J'ai juste très envie de comprendre MDPs en général):

D'après ce que j'ai compris, une simplification grossière de MDPs c'est qu'ils peuvent créer une grille qui tient dans quelle direction nous devons aller (une sorte de grille de "flèches" pointant vers où nous devons aller, départ à une certaine position sur la grille) pour arriver à certains objectifs et d'éviter certains obstacles. Spécifique à ma situation, cela signifierait qu'il permet au joueur pour savoir dans quelle direction aller ramasser les pièces et éviter les ennemis.
maintenant, en utilisant le MDP termes, cela voudrait dire qu'il crée un ensemble d'états(la grille) qui détient un certain nombre de politiques(les mesures à prendre -> haut, bas, droite, gauche) pour un certain état(position sur la grille). Les politiques sont déterminées par les valeurs" d'utilité " de chaque État, qui sont eux-mêmes calculés en évaluant combien obtenir là-bas serait bénéfique dans le court et le long terme.
Est-ce correct? Ou suis-je complètement sur la mauvaise voie?
<!-Je voudrais au moins savoir ce que les variables de l'équation suivante représentent dans ma situation: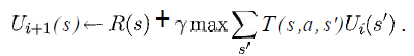
je sais que s une liste de tous les carrés de la grille, a serait une action spécifique (haut / bas / droite / gauche), mais quid du reste?
comment les fonctions de récompense et d'utilité seraient-elles mises en œuvre?
ce serait vraiment génial si quelqu'un connaissait un lien simple qui montre un pseudo-code pour implémenter une version de base avec des similitudes à ma situation d'une manière très lente, parce que je ne sais même pas par où commencer ici.
Merci pour votre temps précieux.
(Note: n'hésitez pas à Ajouter / Supprimer des balises ou à me dire dans les commentaires si je dois donner plus de détails pour quelque chose ou quelque chose comme ça.)
4 réponses
Oui, la notation mathématique peut la rendre beaucoup plus compliquée qu'elle ne l'est. Vraiment, c'est une idée très simple. J'ai mis en place un valeur applet de démo d'itération que vous pouvez jouer avec pour faire une meilleure idée.
en gros, disons que vous avez une grille 2D avec un robot. Le robot peut essayer de se déplacer vers le Nord, le Sud, L'est, L'Ouest (ce sont les actions a) mais, parce que sa roue gauche est glissante, quand il essaie de se déplacer vers le Nord il n'y a qu'un .9 probabilité qu'il retrouver dans le carré Nord de, quand il en est un .1 probabilité qu'il se retrouve au carré ouest de celui-ci (de même pour les 3 autres actions). Ces probabilités sont saisies par la fonction T (). À savoir, T (s,A,s') ressemblera à:
s A s' T //x=0,y=0 is at the top-left of the screen
x,y North x,y+1 .9 //we do move north
x,y North x-1,y .1 //wheels slipped, so we move West
x,y East x+1,y .9
x,y East x,y-1 .1
x,y South x,y+1 .9
x,y South x-1,y .1
x,y West x-1,y .9
x,y West x,y+1 .1
Vous définissez ensuite la Récompense à 0 pour tous les etats, mais 100 pour l'objectif de l'état, qui est, à l'emplacement où vous voulez que le robot.
ce que la valeur-itération fait est ses débuts en donnant un utilitaire de 100 à l'état du but et 0 à tous les autres États. Puis sur la première itération ce 100 d'utilité est distribué en arrière 1-étape du but, de sorte que tous les États qui peuvent arriver à l'état de but en 1 étape (tous les 4 carrés juste à côté de lui) obtiendront un certain utilité. À savoir, ils obtiendront une utilité égale à la probabilité que de cet état nous pouvons atteindre le but énoncé. Nous continuons ensuite à itérer, à chaque étape, nous éloignons l'utilitaire d'un pas de plus de l'objectif.
Dans l'exemple ci-dessus, disons que vous commencez avec R (5,5)= 100 et R (.) = 0 pour tous les autres états. Donc, le but est d'arriver à 5,5.
lors de la première itération, nous définissons
R (5,6) = gamma * (.9 * 100) + gamma * (.1 * 100)--4-->
parce que sur 5,6 si vous allez vers le Nord il y a un .9 Probabilité de finir à 5,5, alors que si vous allez à L'Ouest Il ya un .1 Probabilité de finir à 5,5.
de Même pour (5,4), (4,5), (6,5).
tous les autres États restent avec U = 0 après la première itération de la valeur itération.
je recommande D'utiliser Q-learning pour votre mise en œuvre.
peut-être Pouvez-vous utiliser ce post que j'ai écrit comme une inspiration. C'est un Q-learning démo avec le code source Java. Cette démo est une carte avec 6 champs et l'IA apprend d'où il devrait aller de chaque etat pour obtenir la récompense.
Q-learning est une technique qui permet à L'IA d'apprendre par elle-même en lui donnant une récompense ou une punition.
cet exemple montre le Q-learning utilisé pour trouver le chemin. Un robot apprend où il doit aller de n'importe quel état.
le robot commence à un endroit aléatoire, il garde la mémoire du score pendant qu'il explore la zone, chaque fois qu'il atteint le but, nous répétons avec un nouveau départ aléatoire. Après assez de répétitions les valeurs de score seront stationnaires (convergence).
dans cet exemple, le résultat de l'action est déterministe (la probabilité de transition est de 1) et la sélection de l'action est aléatoire. Les valeurs de score sont calculées par le Q-learning de l'algorithme de Q(s,a).
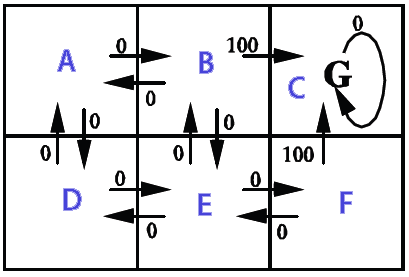
L'image montre les états (A,B,C,D,E, F), les actions possibles des États et la récompense donnée.
Résultat Q*(s,a)
politique Π*(s)
Qlearning.java
import java.text.DecimalFormat; import java.util.Random; /** * @author Kunuk Nykjaer */ public class Qlearning { final DecimalFormat df = new DecimalFormat("#.##"); // path finding final double alpha = 0.1; final double gamma = 0.9; // states A,B,C,D,E,F // e.g. from A we can go to B or D // from C we can only go to C // C is goal state, reward 100 when B->C or F->C // // _______ // |A|B|C| // |_____| // |D|E|F| // |_____| // final int stateA = 0; final int stateB = 1; final int stateC = 2; final int stateD = 3; final int stateE = 4; final int stateF = 5; final int statesCount = 6; final int[] states = new int[]{stateA,stateB,stateC,stateD,stateE,stateF}; // http://en.wikipedia.org/wiki/Q-learning // http://people.revoledu.com/kardi/tutorial/ReinforcementLearning/Q-Learning.htm // Q(s,a)= Q(s,a) + alpha * (R(s,a) + gamma * Max(next state, all actions) - Q(s,a)) int[][] R = new int[statesCount][statesCount]; // reward lookup double[][] Q = new double[statesCount][statesCount]; // Q learning int[] actionsFromA = new int[] { stateB, stateD }; int[] actionsFromB = new int[] { stateA, stateC, stateE }; int[] actionsFromC = new int[] { stateC }; int[] actionsFromD = new int[] { stateA, stateE }; int[] actionsFromE = new int[] { stateB, stateD, stateF }; int[] actionsFromF = new int[] { stateC, stateE }; int[][] actions = new int[][] { actionsFromA, actionsFromB, actionsFromC, actionsFromD, actionsFromE, actionsFromF }; String[] stateNames = new String[] { "A", "B", "C", "D", "E", "F" }; public Qlearning() { init(); } public void init() { R[stateB][stateC] = 100; // from b to c R[stateF][stateC] = 100; // from f to c } public static void main(String[] args) { long BEGIN = System.currentTimeMillis(); Qlearning obj = new Qlearning(); obj.run(); obj.printResult(); obj.showPolicy(); long END = System.currentTimeMillis(); System.out.println("Time: " + (END - BEGIN) / 1000.0 + " sec."); } void run() { /* 1. Set parameter , and environment reward matrix R 2. Initialize matrix Q as zero matrix 3. For each episode: Select random initial state Do while not reach goal state o Select one among all possible actions for the current state o Using this possible action, consider to go to the next state o Get maximum Q value of this next state based on all possible actions o Compute o Set the next state as the current state */ // For each episode Random rand = new Random(); for (int i = 0; i < 1000; i++) { // train episodes // Select random initial state int state = rand.nextInt(statesCount); while (state != stateC) // goal state { // Select one among all possible actions for the current state int[] actionsFromState = actions[state]; // Selection strategy is random in this example int index = rand.nextInt(actionsFromState.length); int action = actionsFromState[index]; // Action outcome is set to deterministic in this example // Transition probability is 1 int nextState = action; // data structure // Using this possible action, consider to go to the next state double q = Q(state, action); double maxQ = maxQ(nextState); int r = R(state, action); double value = q + alpha * (r + gamma * maxQ - q); setQ(state, action, value); // Set the next state as the current state state = nextState; } } } double maxQ(int s) { int[] actionsFromState = actions[s]; double maxValue = Double.MIN_VALUE; for (int i = 0; i < actionsFromState.length; i++) { int nextState = actionsFromState[i]; double value = Q[s][nextState]; if (value > maxValue) maxValue = value; } return maxValue; } // get policy from state int policy(int state) { int[] actionsFromState = actions[state]; double maxValue = Double.MIN_VALUE; int policyGotoState = state; // default goto self if not found for (int i = 0; i < actionsFromState.length; i++) { int nextState = actionsFromState[i]; double value = Q[state][nextState]; if (value > maxValue) { maxValue = value; policyGotoState = nextState; } } return policyGotoState; } double Q(int s, int a) { return Q[s][a]; } void setQ(int s, int a, double value) { Q[s][a] = value; } int R(int s, int a) { return R[s][a]; } void printResult() { System.out.println("Print result"); for (int i = 0; i < Q.length; i++) { System.out.print("out from " + stateNames[i] + ": "); for (int j = 0; j < Q[i].length; j++) { System.out.print(df.format(Q[i][j]) + " "); } System.out.println(); } } // policy is maxQ(states) void showPolicy() { System.out.println("\nshowPolicy"); for (int i = 0; i < states.length; i++) { int from = states[i]; int to = policy(from); System.out.println("from "+stateNames[from]+" goto "+stateNames[to]); } } }imprimer le résultat
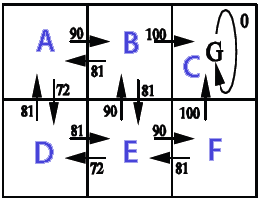
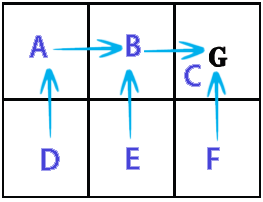
out from A: 0 90 0 72,9 0 0 out from B: 81 0 100 0 81 0 out from C: 0 0 0 0 0 0 out from D: 81 0 0 0 81 0 out from E: 0 90 0 72,9 0 90 out from F: 0 0 100 0 81 0 showPolicy from a goto B from b goto C from c goto C from d goto A from e goto B from f goto C Time: 0.025 sec.
Pas de réponse exhaustive, mais de clarifier les remarque.
état une seule cellule. L'état contient l'information ce qui est dans chaque cellule pour toutes les cellules concernées à la fois. Cela signifie qu'un élément d'état contient les informations que les cellules sont solides et qui sont vides; que ceux-ci contiennent des monstres; où sont les pièces; où est le joueur.
peut-être que vous pourriez utiliser une carte de chaque cellule à son contenu comme état. Ce n'est ignorer l' mouvement de monstres et les joueurs, qui sont probablement très importants, aussi.
les détails dépendent de la façon dont vous voulez modéliser votre problème (décider ce qui appartient à l'état et sous quelle forme).
puis une politique établit une correspondance entre chaque état et une action telle que gauche, droite, saut, etc.
tout d'abord, vous devez comprendre le problème qui est exprimé par un MDP avant de penser à la façon dont les algorithmes comme l'itération de valeur fonctionnent.
je sais que c'est un assez vieux post, mais je suis tombé sur elle lors de la recherche pour le MDP, je ne veux noter (pour les gens à venir ici) un peu plus de commentaires sur lorsque vous avez déclaré que "s" et "a" ont été.
je pense que pour un vous avez absolument raison, c'est votre liste de [haut,bas,gauche,droite].
Cependant pour s c'est vraiment l'endroit dans le réseau et s' est l'endroit où vous pouvez aller. Ce que cela signifie est que vous choisissez un état, et puis vous choisissez un s particulier et passez en revue toutes les actions qui peuvent vous mener à ce sprime, que vous utilisez pour comprendre ces valeurs. (ramasser un max de personnes). Enfin vous allez pour le prochain s' et faire la même chose, quand vous avez épuisé toutes les valeurs de s' puis vous trouvez le max de ce que vous venez de terminer la recherche sur.
supposons que vous avez choisi une cellule de grille dans le coin, vous n'avez que 2 états dans lesquels vous pouvez éventuellement vous déplacer (en supposant que le coin en bas à gauche), selon la façon dont vous choisissez de "nommer" vos états, nous pourrions dans ce cas suppose qu'un État est une coordonnée x, y, donc votre état actuel s est 1,1 et votre liste de s (ou de s prime) est x+1, y et x, y+1 (Pas de diagonale dans cet exemple) (la partie sommation qui va sur tout s')
aussi vous ne l'avez pas énuméré dans votre équation, mais le max est de a ou l'action qui vous donne le max, donc d'abord vous choisissez le s' qui vous donne le max et ensuite à l'intérieur que vous choisissez l'action (au moins c'est ma compréhension de l'algorithme).
Donc, si vous a
x,y+1 left = 10
x,y+1 right = 5
x+1,y left = 3
x+1,y right 2
vous choisirez x, y+1 comme votre s', mais ensuite vous devrez choisir une action qui est maximisée ce qui est dans ce cas laissé pour x,y+1. Je ne suis pas sûr qu'il y ait une différence subtile entre juste trouver le nombre maximum et trouver l'État alors le nombre maximum bien que peut-être quelqu'un un jour peut clarifier cela pour moi.
si vos mouvements sont déterministes (ce qui signifie que si vous dites aller de l'avant, vous allez de l'avant avec une certitude de 100%), alors c'est assez facile vous avez une action, cependant si elles sont non déterministes, vous avez une certitude de 80%, alors vous devriez considérer les autres actions qui vous y arrivez. C'est le contexte de la roue glissante que Jose a mentionné ci-dessus.
Je ne veux pas altérer ce que d'autres ont dit, mais juste pour donner quelques informations supplémentaires.