perte, val perte, acc et val acc ne pas mettre à jour à toutes les époques
j'ai créé un réseau LSTM pour la classification des séquences (binaire) où chaque échantillon a 25 timesteps et 4 fonctionnalités. Voici ma topologie de réseau keras:
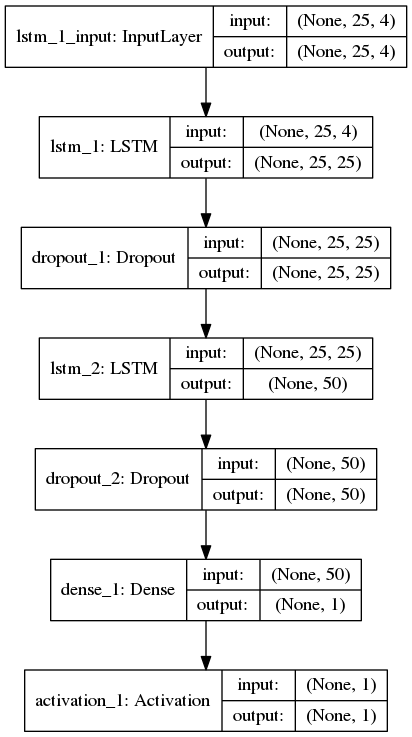
ci-dessus, la couche d'activation après la couche Dense utilise la fonction softmax. J'ai utilisé binary_crossentropy pour la fonction de perte Et Adam comme optimiseur pour compiler le modèle keras. Formé le modèle avec batch_size=256, shuffle = True et validation_split = 0,05, ce qui suit est le journal d'entraînement:
Train on 618196 samples, validate on 32537 samples
2017-09-15 01:23:34.407434: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:893] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2017-09-15 01:23:34.407719: I tensorflow/core/common_runtime/gpu/gpu_device.cc:955] Found device 0 with properties:
name: GeForce GTX 1050
major: 6 minor: 1 memoryClockRate (GHz) 1.493
pciBusID 0000:01:00.0
Total memory: 3.95GiB
Free memory: 3.47GiB
2017-09-15 01:23:34.407735: I tensorflow/core/common_runtime/gpu/gpu_device.cc:976] DMA: 0
2017-09-15 01:23:34.407757: I tensorflow/core/common_runtime/gpu/gpu_device.cc:986] 0: Y
2017-09-15 01:23:34.407764: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1045] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 1050, pci bus id: 0000:01:00.0)
618196/618196 [==============================] - 139s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 2/50
618196/618196 [==============================] - 132s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 3/50
618196/618196 [==============================] - 134s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 4/50
618196/618196 [==============================] - 133s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 5/50
618196/618196 [==============================] - 132s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 6/50
618196/618196 [==============================] - 132s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 7/50
618196/618196 [==============================] - 132s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 8/50
618196/618196 [==============================] - 132s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
... and so on through 50 epochs with same numbers
Jusqu'à présent, j'ai aussi essayé d'utiliser rmsprop, nadam optimizers et batch_size(s) 128, 512, 1024 mais la perte, val_loss, acc, val_acc est toujours restée la même à toutes les époques, donnant une précision dans la gamme de 0.72 à 0.74 à chaque tentative.
1 réponses
softmax l'activation s'assure que la somme des sorties est 1. Il est utile pour assurer qu'une seule classe parmi de nombreuses classes seront de sortie.
Puisque vous avez seulement 1 sortie (une seule classe), c'est certainement une mauvaise idée. Vous finissez probablement avec 1 comme résultat pour tous les échantillons.
Utiliser sigmoid à la place. Il va bien avec binary_crossentropy.