Liste de Big - O pour les fonctions PHP
après avoir utilisé PHP pendant un certain temps maintenant, je l'ai remarqué que pas tous PHP construit dans les fonctions aussi vite que prévu. Considérons les deux implémentations possibles ci-dessous d'une fonction qui trouve si un nombre est premier en utilisant un tableau de nombres premiers en cache.
//very slow for large $prime_array
$prime_array = array( 2, 3, 5, 7, 11, 13, .... 104729, ... );
$result_array = array();
foreach( $prime_array => $number ) {
$result_array[$number] = in_array( $number, $large_prime_array );
}
//speed is much less dependent on size of $prime_array, and runs much faster.
$prime_array => array( 2 => NULL, 3 => NULL, 5 => NULL, 7 => NULL,
11 => NULL, 13 => NULL, .... 104729 => NULL, ... );
foreach( $prime_array => $number ) {
$result_array[$number] = array_key_exists( $number, $large_prime_array );
}
c'est parce que in_array est implémenté avec une recherche linéaire O(n) qui ralentira linéairement avec la croissance de $prime_array . Où la fonction array_key_exists est implémentée avec une recherche de hachage O (1) qui ne ralentira pas down à moins que la table de hachage soit extrêmement peuplée (dans ce cas, c'est seulement O(n)).
Jusqu'à présent, j'ai dû découvrir les big-O via trial and error, et occasionnellement en regardant le code source . Maintenant pour la question...
Est une liste de la partie théorique (et pratique) big O fois pour toutes* le PHP intégré dans les fonctions?
*ou au moins l'intéressant
par exemple trouver très difficile de prédire ce que le big O des fonctions énumérées parce que l'implémentation possible dépend des structures de données de base inconnues de PHP: array_merge, array_merge_recursive, array_reverse, array_intersect, array_combine, str_replace (avec des entrées de tableau), etc.
4 réponses
Puisqu'il ne semble pas que quelqu'un a fait cela avant que je pensais que ce serait une bonne idée de l'avoir pour référence quelque part. J'y suis allé soit par benchmark soit par code-skimming pour caractériser les fonctions array_* . J'ai essayé de mettre le plus intéressant Big-O en haut. Cette liste n'est pas complète.
Note: Tout le Big-O où calculé en supposant une recherche de hachage est O(1) même si c'est vraiment O(n). Le coefficient de n est si faible, le le fait de stocker un tableau suffisamment grand vous nuirait avant que les caractéristiques de lookup Big-O commencent à prendre effet. Par exemple, la différence entre un appel à array_key_exists à N=1 et N=1.000.000 est une augmentation de temps d'environ 50%.
Points Intéressants :
-
isset/array_key_existsest beaucoup plus rapide quein_arrayetarray_search -
+(union) est un peu plus rapide quearray_merge(et semble plus agréable). Mais il fonctionne différemment donc, gardez cela à l'esprit. -
shuffleest sur le même Big-O tierarray_rand -
array_pop/array_pushest plus rapide quearray_shift/array_unshiften raison de la pénalité de réindexation
"Lookup :
array_key_exists O (n) mais vraiment proche de O (1) - Ceci est dû au sondage linéaire en les collisions, mais parce que les chances de collision est très faible, le coefficient est également très faible. Par exemple, la différence entre N=1000 et N=100000 ne ralentit que de 50% environ.
isset( $array[$index] ) O(n) mais vraiment proche de O(1) - il utilise la même recherche que array_key_exists. Depuis sa construction de langage, va mettre en cache la recherche Si la clé est codée en dur, résultant en une accélération dans les cas où la même la clé est utilisée de façon répétée.
in_array O(n) - c'est parce qu'il fait une recherche linéaire à travers le tableau jusqu'à ce qu'il trouve la valeur.
array_search O(n) - il utilise la même fonction de base que in_array mais renvoie de la valeur.
fonctions de file d'attente :
array_push O (∑var_i, pour tous i)
array_pop O (1)
array_shift O(n) - c'est à réindexer toutes les clés
array_unshift O(n + ∑ var_i, pour tout i), il a pour réindexer toutes les clés
Matrice D'Intersection, Union, Soustraction :
array_intersect_key si l'intersection de 100% ne O(Max(param_i_size)*∑param_i_count, pour tout i), si l'intersection de 0% se coupent en O(∑param_i_size, pour tout i)
array_intersect si l'intersection de 100% ne O(n^2*∑param_i_count, pour tout i), si l'intersection de 0% se coupent en O(n^2)
array_intersect_assoc si l'intersection de 100% ne O(Max(param_i_size)*∑param_i_count, pour tout i), si l'intersection de 0% se coupent en O(∑param_i_size, pour tout i)
array_diff O(π param_i_size, pour tous les i)) Que du produit de tous les param_sizes
array_diff_key O(∑ param_i_size, pour moi != 1) - c'est parce que nous n'avons pas besoin d'itérer sur le premier tableau.
array_merge O (∑ array_i, i != 1) - n'a pas besoin d'itérer sur le premier tableau
+ (union) O (n), où n est la taille du 2e tableau (i.e. array_first + array_second) - moins de frais généraux que array_merge puisqu'il n'a pas à renuméroter
array_replace O( ∑ array_i, pour tout i )
Aléatoire :
shuffle O(n)
array_rand O(n) - nécessite un sondage linéaire.
Obvious Big-O :
array_fill O (n)
array_fill_keys O (n)
range O (n)
array_splice O (offset + longueur)
array_slice O(offset + longueur) ou O(n) si longueur = NULL
array_keys O (n)
array_values O (n)
array_reverse O (n)
array_pad O (pad_size)
array_flip O (n)
array_sum O (n)
array_product O (n)
array_reduce O (n)
array_filter O (n)
array_map O (n)
array_chunk O (n)
array_combine O (n)
je tiens à remercier Eureqa pour rendre facile de trouver le Big-O des fonctions. C'est un programme incroyable gratuit qui peut trouver la meilleure fonction d'Ajustement pour les données arbitraires.
EDIT:
pour ceux qui doutent que les ID favori de tableau de PHP sont O(N) , j'ai écrit un benchmark pour tester que (ils sont encore effectivement O(1) pour les valeurs les plus réalistes).
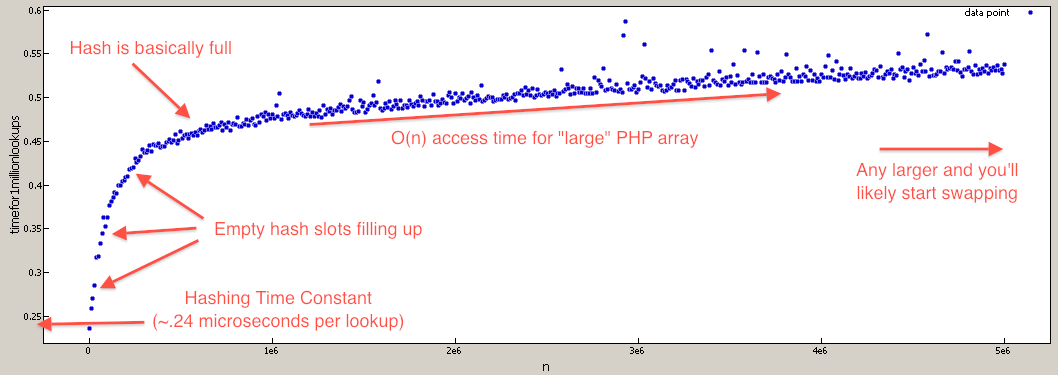
$tests = 1000000;
$max = 5000001;
for( $i = 1; $i <= $max; $i += 10000 ) {
//create lookup array
$array = array_fill( 0, $i, NULL );
//build test indexes
$test_indexes = array();
for( $j = 0; $j < $tests; $j++ ) {
$test_indexes[] = rand( 0, $i-1 );
}
//benchmark array lookups
$start = microtime( TRUE );
foreach( $test_indexes as $test_index ) {
$value = $array[ $test_index ];
unset( $value );
}
$stop = microtime( TRUE );
unset( $array, $test_indexes, $test_index );
printf( "%d,%1.15f\n", $i, $stop - $start ); //time per 1mil lookups
unset( $stop, $start );
}
vous voulez presque toujours utiliser isset au lieu de array_key_exists . Je ne regarde pas les internes, mais je suis assez sûr que array_key_exists est O(N) parce qu'il itère sur chaque touche du tableau, tandis que isset essaie d'accéder à l'élément en utilisant le même algorithme de hachage qui est utilisé lorsque vous accédez à un index de tableau. Qui devrait être O(1).
un " gotcha "à surveiller est celui-ci:
$search_array = array('first' => null, 'second' => 4);
// returns false
isset($search_array['first']);
// returns true
array_key_exists('first', $search_array);
j'étais curieux, donc j'ai comparé la différence:
<?php
$bigArray = range(1,100000);
$iterations = 1000000;
$start = microtime(true);
while ($iterations--)
{
isset($bigArray[50000]);
}
echo 'is_set:', microtime(true) - $start, ' seconds', '<br>';
$iterations = 1000000;
$start = microtime(true);
while ($iterations--)
{
array_key_exists(50000, $bigArray);
}
echo 'array_key_exists:', microtime(true) - $start, ' seconds';
?>
is_set: 0.132308959961 secondes
array_key_exists: 2.33202195168 secondes
bien sûr, cela ne montre pas la complexité du temps, mais il montre comment les deux fonctions se comparent.
pour tester la complexité du temps, comparez le temps qu'il faut pour exécuter l'une de ces fonctions sur le premier la clé et la dernière touche.
l'explication pour le cas que vous décrivez spécifiquement est que les tableaux associatifs sont implémentés comme des tables de hachage - donc la recherche par clé (et en conséquence, array_key_exists ) est O(1). Cependant, les tableaux ne sont pas indexés par valeur, donc la seule façon dans le cas général de découvrir si une valeur existe dans le tableau est une recherche linéaire. Il n'y a pas de surprise là.
Je ne pense pas qu'il y ait de documentation spécifique complète sur la complexité algorithmique des méthodes PHP. Cependant, si c'est une préoccupation assez grande pour justifier l'effort, vous pouvez toujours regarder à travers le code source .
si les gens rencontraient des problèmes dans la pratique avec les collisions de clés, ils mettraient en œuvre des conteneurs avec une recherche de hachage secondaire ou arbre équilibré. L'arbre équilibré donnerait un comportement o(log n) dans le pire des cas et O (1) Moy. cas (le hash). Le overhead n'en vaut pas la peine dans la plupart des applications en mémoire, mais peut-être il y a des bases de données qui mettent en œuvre cette forme de stratégie mixte comme leur cas par défaut.